
By Dan Ortega
Product Marketing
Dan has had more than 20 years of experience helping customers understand the business value of technologies. His domain expertise spans enterprise software, IoT, ITSM/ITOM, data analytics, mobility, business intelligence, SaaS, content management, predictive analytics, and information lifecycle management. Throughout his career, Dan has worked with companies ranging in size from start-up to Fortune 500 and enjoys sharing insights on business value creation through his contributions to the Hazelcast blog. Dan was born in New York, grew up in Mexico City, and returned to get his B.A. in Economics from the University of Michigan.
View all blogs by the authorJul 16, 2019
The Role of Streaming Technology in Retail Banking
Stream processing refers to real-time management of data entering a banking system (or any information system, actually) at high speed and volume, usually from a broad range of sources. The “management” aspect means data is wholly or partially processed and contextualized before entering an in-memory (operational) system, where pre-processing can significantly accelerate response times. Before in-memory technologies, transactional data was managed as a batch process and analyzed every hour, once a day, etc., depending on the data involved, the bank’s policies for handling data, regulatory and compliance requirements, and so on. While having instant access to operational data is critical for some applications such as fraud detection, other use cases may not require an immediate interpretation of the data (e.g., updating customer contact preference information). This means that while real-time streaming enables retail banks to take the integrated customer experience to a whole different level, non-real-time data requirements imply there is still going to be a place for batch processing and systems should be architected on the assumption that both will be working together since they address different but complementary facets of data processing.
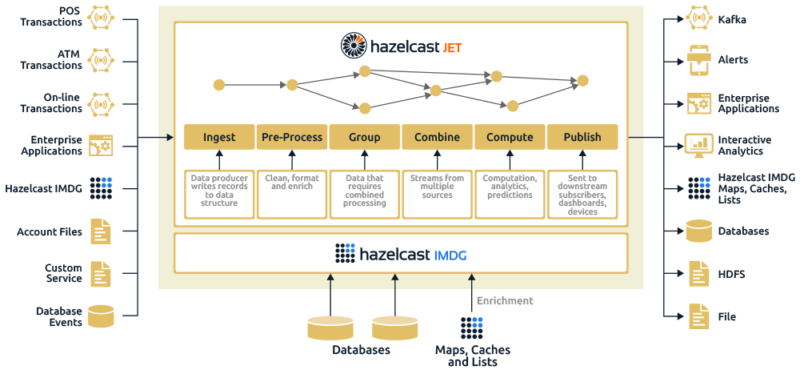
Architecturally, it would look like this:
In this model, there is a broad range of potential sources of data entering the system; this includes input from IoT devices, external systems through a variety of APIs, databases, etc. Once the data enters the stream processing engine (the middle box) it is executed as a directed acyclic graph (DAG) which essentially means data moves through the system in a progressive (and multi-path) process, rather than a looped process. The steps involved in this model are, therefore:
- Ingest: This step entails loading data from many sources into the system.
- Pre-process: The data is scanned and “data preparation” is performed, including activities such as formatting, normalization, and data enrichment using relevant data from corollary sources.
- Group: In this stage, data types are grouped by data sources such as points of sale (POS), ATM, website access, app access, transactional type such as deposit, transfer, payment, etc., customer grouping by product, etc.).
- Combine: Grouped data types are combined to address cross-functional requirements from an operational perspective. This would include distinct, grouped data types within a line of business (a customer with multiple accounts with cross-dependencies, such as a minimum balance of X is maintained in account Y, account Z has service charges waived).
- Compute: The heavy lifting associated with data processing, which includes computations on the data, applied analytics that can tie into legacy or ancillary operational systems, and can be used to (for example) integrate processed data into prediction algorithms.
- Publish: Data that has moved through this process is subsequently sent to downstream operational systems for further processing and analysis, or sent to subscribers, management dashboards, or devices waiting for input (for example, a POS terminal waiting for authorization).
These steps, which are dependent on the reference architecture, typically happen in approximately seven milliseconds. For reference, it takes a human 300 milliseconds to blink. Essentially this all has to happen in less time than it takes to swipe a card through a terminal – which is the most common transactional use case for retail banking.
So given this architecture and the underlying flow of data streaming into the system, what are the top examples of this applied to retail banking?
Fraud detection. This is a top priority for any bank by a comfortable margin, as it affects both customer satisfaction and the bank’s bottom line. Being able to detect fraudulent behavior at the moment (that is, during the < 1-second interval when a card is swiped or read) is a textbook example of processing high-speed streaming data, since it is happening millions of times per second and each transaction requires a real-time response.
From a workflow perspective, it would look like this:
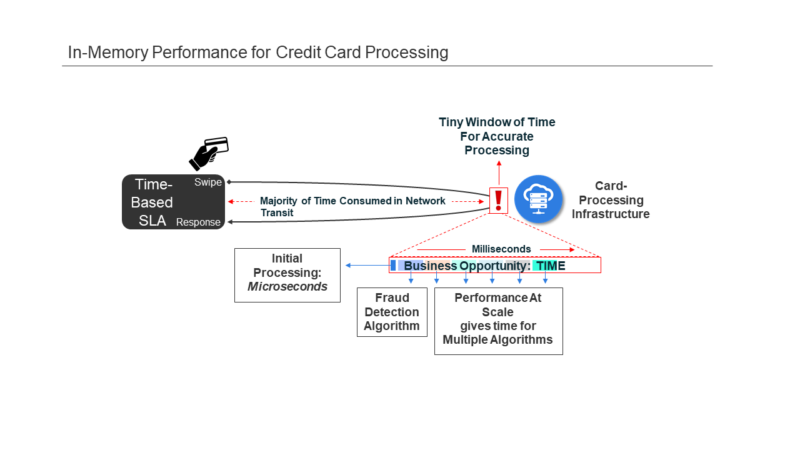
In the above illustration, several variables have aligned to shift execution requirements to a much higher level of performance. The number of “terminals” has exploded as the definition has expanded – e.g. the phone in your pocket is a POS terminal, which can be used to make online purchases. As the ease of access has improved and more devices access the network, transactional volumes have increased to a rate of millions per second. The interval between swiping a card (or hitting “purchase” on a mobile device), to when the transaction is approved (that is, not fraudulent) is measured in a few seconds. During this time, the transaction must:
- Traverse a network and arrive as part of one of many data streams entering the payment processing system (along with millions of other transactions at the same time)
- Pass through multiple fraud detection algorithms
- Receive authorization
- Travel back across the network to the requesting device
All of this must be accomplished alongside millions of other transactions and before the consumer loses patience. These are effectively the six steps outlined earlier, now defined in a specific use case.
The combination of a stream processing engine with an in-memory data grid can provide the speed and processing framework to support not only variables associated with stream processing; multiple streams, varied locations, and multiple device types, but also event details such as currency, which is then tied to specifics of the account (e.g., credit limits, prior history, etc.), most of which is kept in an in-memory data grid. This process is already in place at some of the industry’s largest credit card processors, and the reduction in fraudulent charges is being measured in the high nine figures (and that’s just one bank).
Customer Service. Most bank customers have several accounts and banks are always looking for opportunities to cross or upsell. A large bank can have hundreds of potential products or services, even though no normal consumer needs that level of product. However, if a bank can increase product penetration from 2.5 products to 4 products per customer, this effectively adds millions to their bottom line.
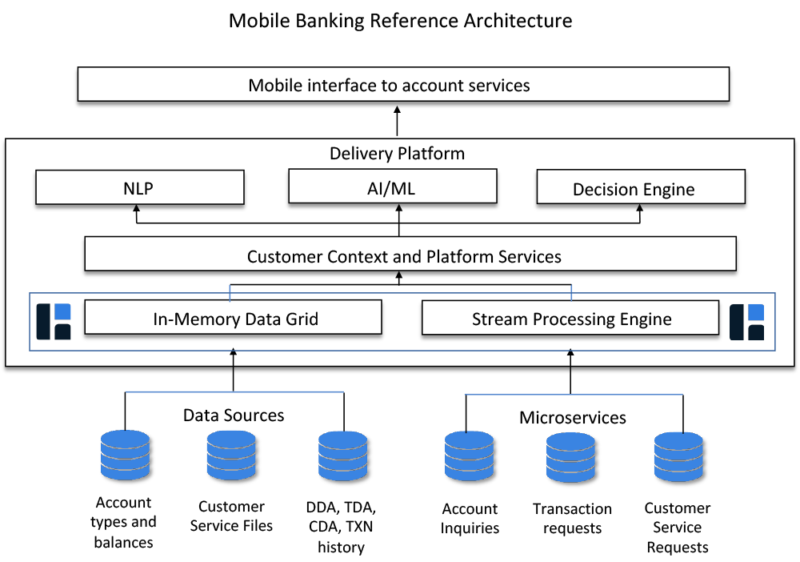
The trick to moving the needle for retail customers is timely context. When the bank’s customer is actively engaged online, via the phone, or in branch, that is the best opportunity to get them interested in new products or services. But for this to happen, the bank needs a comprehensive and contextualized view of that customer, including how many accounts, what’s the transaction history, where are they compared to their cohorts, and more. At any given moment for a large bank, there can be millions of customers accessing various parts of the system; information is streaming in from phones, PCs, customer support lines, and other sources. Similar to the fraud detection example, information streaming into the system is pre-processed before entering the IMDG where historical context can be applied to improve the probability of a cross-sell opportunity. Where this gets interesting is when all this information is used to power machine learning and artificial intelligence (AI) systems (you think you’re talking to a human, and it turns out you’re speaking with a machine). The main advantage of tying an in-memory solution to an AI solution is volume; millions of simultaneous customers calling in can strain even the most significant call center, but not be noticeable to an AI-powered chatbot.
Similar to the risks associated with managing a complex series of data sources that pivot around an individual customer, the same thing applies to an open banking ecosystem, but on a much larger scale. This is where cloud-based solutions enabled by in-memory technologies will move the needle. This type of scenario requires integration across a broad range of sources (where stream processing engines apply), significant speed across a full range of operational and back-end systems, as well as the ability to scale up or down quickly as demand for services shifts. These scenarios are what has driven the success of in-memory technologies within the financial services community, and will continue to do so as the environment becomes increasingly complex. Technology-heavy businesses such as banking are experiencing a dizzying rate of evolution, whether driven by innovation (e.g., IoT and streaming services) or compliance (PSD2). Regardless of the driver, networks are becoming far denser, expectations for immediate remediation are broad and deep, and the competitive environment is entirely different than it was only a few years back. Now is the time to look at what in-memory solutions can deliver; this technology suits today’s always-on, hyper-fast transactional ecosystems. To get a better understanding of what is possible, please click here.


