What Is Machine Learning Inference?
Machine learning (ML) inference is the process of running live data points into a machine learning algorithm (or “ML model”) to calculate an output such as a single numerical score. This process is called “operationalizing an ML model” or “putting an ML model into production.” When an ML model is running in production, it is often described as artificial intelligence (AI) since it performs functions similar to human thinking and analysis. Machine learning inference entails deploying a software application into a production environment, as the ML model is typically just software code that implements a mathematical algorithm. That algorithm makes calculations based on the characteristics of the data, known as “features” in the ML vernacular.
An ML lifecycle can be broken up into two main, distinct parts. The first is the training phase, in which an ML model is created or “trained” by running a specified subset of data into the model. ML inference is the second phase, in which the model is put into action on live data to produce actionable output. The data processing by the ML model is often referred to as “scoring,” so one can say that the ML model scores the data, and the output is a score.
DevOps engineers or data engineers generally deploy ML or AI inference. Sometimes, the data scientists training the models are asked to own the ML inference process. This latter situation often causes significant obstacles in getting to the ML inference stage, since data scientists are not necessarily skilled at deploying systems. Successful ML deployments are often the result of tight coordination between different teams, and newer software technologies are also often deployed to try to simplify the process. An emerging discipline known as “MLOps” is starting to put more structure and resources around getting ML models into production and maintaining those models when changes are needed.
How Does Machine Learning Inference Work?
To deploy a machine learning inference environment, you need three main components in addition to the model:
- One or more data sources
- A system to host the ML model
- One or more data destinations
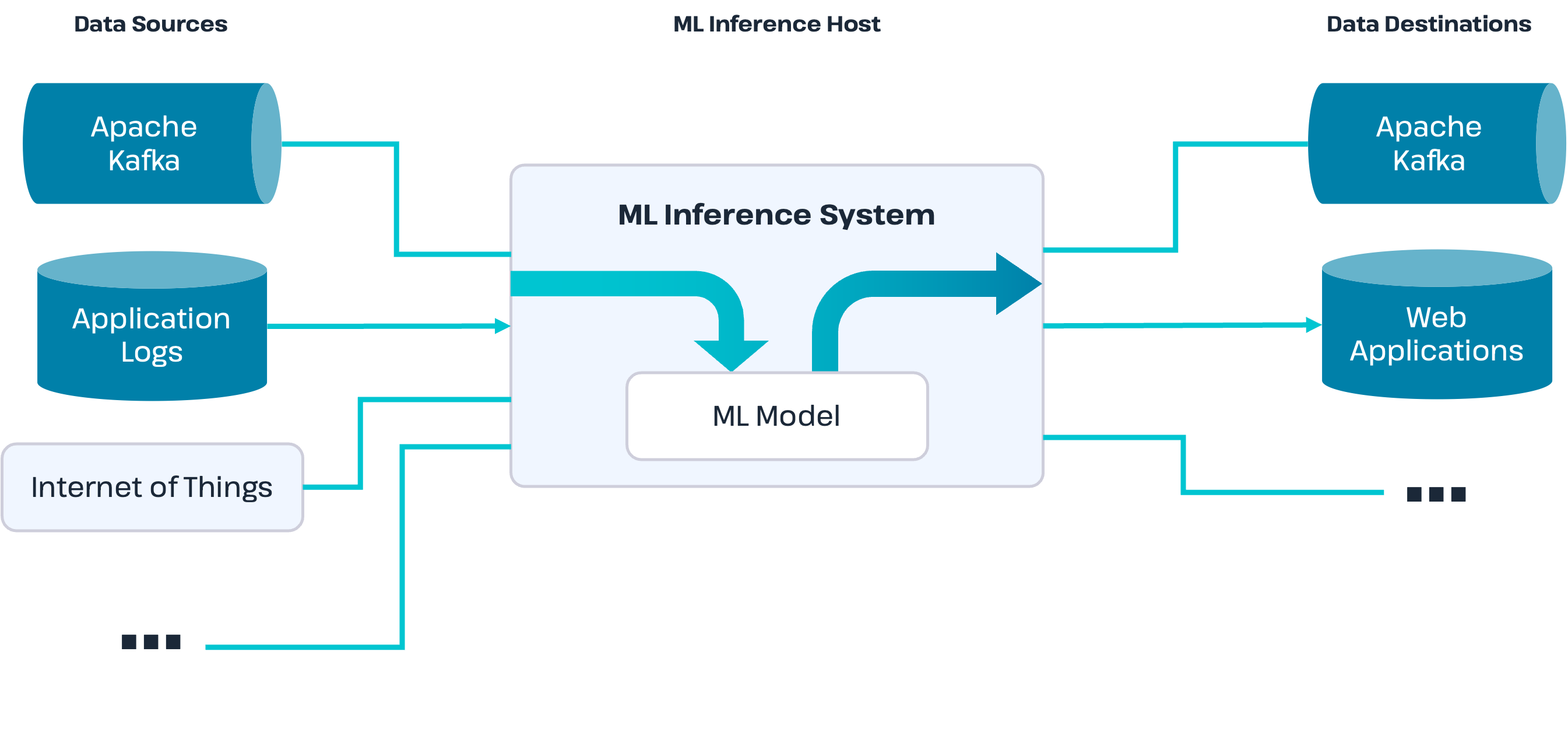
The data sources are typically a system that captures the live data from the mechanism that generates the data. For example, a data source might be an Apache Kafka cluster that stores data created by an Internet of Things (IoT) device, a web application log file, or a point-of-sale (POS) machine. Or a data source might be a web application that collects user clicks and sends data to the system that hosts the ML model.
The host system for the ML model accepts data from the data sources and inputs the data into the ML model. The host system provides the infrastructure to turn the code in the ML model into a fully operational application. After an output is generated from the ML model, the host system then sends that output to the data destinations. For example, the host system can be a web application that accepts data input via a REST interface or a stream processing application that takes an incoming feed of data from Apache Kafka to process many data points per second.
The data destinations are where the host system should deliver the output score from the ML model. A destination can be any data repository like Apache Kafka or a database, and from there, downstream applications take further action on the scores. For example, if the ML model calculates a fraud score on purchase data, the applications associated with the data destinations might send an “approve” or “decline” message back to the purchase site.
Challenges of Machine Learning Inference
As mentioned earlier, the work in ML inference can sometimes be misallocated to the data scientist. If given only a low-level set of tools for ML inference, the data scientist may not be successful in the deployment.
Additionally, DevOps and data engineers are sometimes not able to help with deployment, often due to conflicting priorities or a lack of understanding of what’s required for ML inference. In many cases, the ML model is written in a language like Python, which is popular among data scientists, but the IT team is more well-versed in a language like Java. This means that engineers must take the Python code and translate it to Java to run it within their infrastructure. In addition, the deployment of ML models requires some extra coding to map the input data into a format that the ML model can accept, and this extra work adds to the engineers’ burden when deploying the ML model.
Also, the ML lifecycle typically requires experimentation and periodic updates to the ML models. If deploying the ML model is difficult in the first place, then updating models will be almost as difficult. The whole maintenance effort can be difficult, as there are business continuity and security issues to address.
Another challenge is attaining suitable performance for the workload. REST-based systems that perform the AI or ML inference often suffer from low throughput and high latency. This might be suitable for some environments, but modern deployments that deal with IoT and online transactions are facing huge loads that can overwhelm these simple REST-based deployments. And the system needs to be able to scale to not only handle growing workloads but to also handle temporary load spikes while retaining consistent responsiveness.
When pursuing a machine learning strategy, technology choice is very important to address these challenges. Hazelcast is an example of a software vendor that provides in-memory and streaming technologies that are well-suited for deploying ML inference. Open source editions are available to try out the technology with no commitment.