What Is an Inference Runner?
An inference runner is a component in large-scale software systems that lets you plug in machine learning (ML) algorithms (or “models”) to deliver data into those algorithms and calculate outputs. It enables the ML inference phase of the ML lifecycle. Since an ML model is simply software code that represents the algorithm alone, it needs surrounding application infrastructure to do work (i.e., the aforementioned large-scale software system). An inference runner makes it easier to put a trained ML model into a host system that provides that application infrastructure. This host system could be as simple as a clustered web application that receives data via a REST interface or as comprehensive as a stream processing framework that feeds real-time data directly to the model.
How Does an Inference Runner Work?
The core functionality of an inference runner includes an application programming interface (API) that lets the ML model integrate with the host system. This is how the host system communicates with the model and ensures data is sent in a way that the model will understand. In some cases, extra infrastructure like a virtual machine (VM) is required to run the ML code. The inference runner is responsible for maintaining that infrastructure, which often includes provisions for high availability and security.
Why Is an Inference Runner Necessary?
An inference runner is necessary when the host system is based on a programming language that is different from that of the ML model. For example, if your host is written in Java and your model is in Python, that creates more difficulty in integrating the two. An inference runner provides the interface so that the host can treat the model almost as if it were natively embedded into the host. The ML model is run in a separate process from the host system, and the inference runner manages the interprocess communication, typically through a protocol like RPC. Developers are, therefore, not required to build the communications layer themselves.
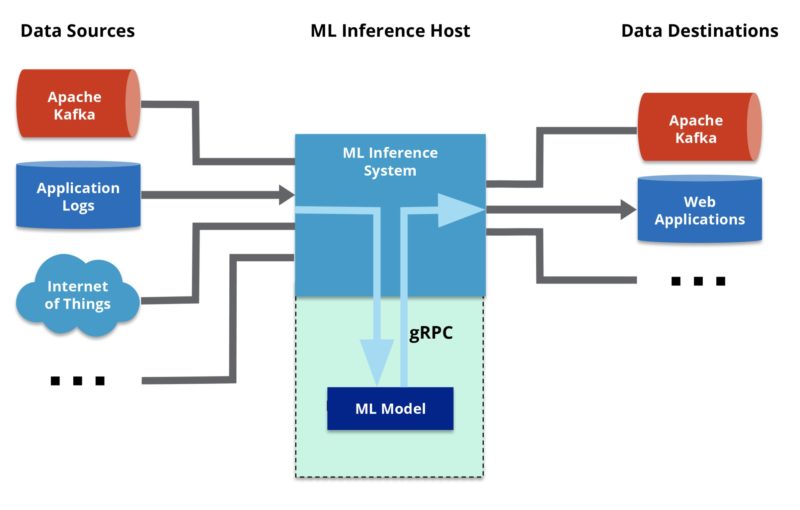
An inference runner for the Python programming language is one of the most useful types of inference runners because Python is the most popular language used by the data scientists who build and train models. At the same time, many data management platforms that can host the ML models are written in Java, creating a language mismatch. In this situation, the inference runner acts as the management layer for running the Python model in a host system based on Java. Since Python is an interpreted language, its code needs to be run inside a Python VM. Therefore, an inference running on a Java host must orchestrate the deployment of Python VMs to let the Python ML models run. Hazelcast Jet is an example of a stream processing engine that supports Python ML models. It uses gRPC to automatically set up and run the Python VMs and send data to the Python code, so DevOps and data engineers do not have to maintain the Python VMs independently.