See Hazelcast in Action
Sign up for a personalized demo.
What is Sharding?
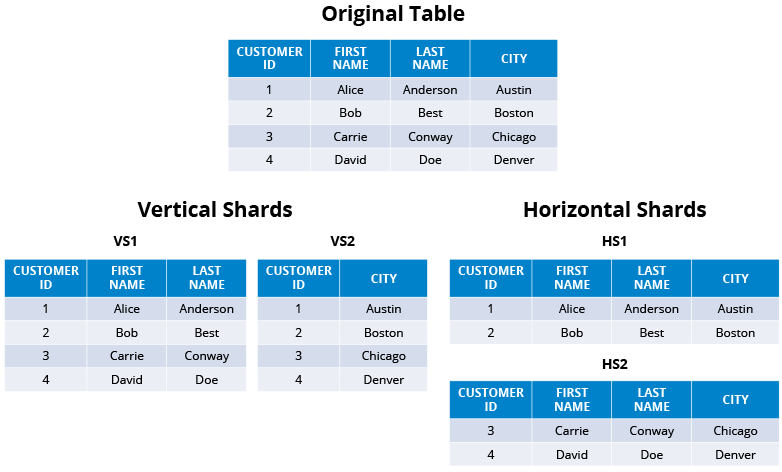
Sharding is the practice of optimizing database management systems by separating the rows or columns of a larger database table into multiple smaller tables. The new tables are called “shards” (or partitions), and each new table either has the same schema but unique rows (as is the case for “horizontal sharding”) or has a schema that is a proper subset of the original table’s schema (as is the case for “vertical sharding”)
Why Is Sharding Used?
Sharding is a common concept in scalable database architectures. By sharding a larger table, you can store the new chunks of data, called logical shards, across multiple nodes to achieve horizontal scalability and improved performance. Once the logical shard is stored on another node, it is referred to as a physical shard.
When running a database on a single machine, you will eventually reach the limit of the amount of computing resources you can apply to any queries, and you will obviously reach a maximum amount of data with which you can efficiently work. By horizontally scaling out, you can enable a flexible database design that increases performance in two key ways:
- With massively parallel processing, you can take advantage of all the compute resources across your cluster for every query since each node can be working on separate shards or separate parts of the database.
- Because the individual shards are smaller than the logical table as a whole, each node has to scan fewer rows when responding to a query.
Horizontal sharding is effective when queries tend to return a subset of rows that are often grouped together. For example, queries that filter data based on short date ranges are ideal for horizontal sharding since the date range will necessarily limit querying to only a subset of the servers (physical or virtual).
Vertical Sharding is effective when queries tend to return only a subset of columns of the data. For example, if some queries request only names, and others request only addresses, then the names and addresses can be sharded onto separate servers.
Also, sharded databases can offer higher levels of availability. In the event of an outage on an unsharded database, the entire application is unusable. With a sharded database, only the portions of the application that relied on the missing chunks of data are unusable. In practice, sharded databases often further mitigate the impact of such outages by replicating backup shards on additional nodes.
Database Sharding vs Partitioning
Sharding and partitioning are both about breaking up a large data set into smaller subsets. The difference is that sharding implies the data is spread across multiple computers while partitioning does not. Partitioning is about grouping subsets of data within a single database instance. In many cases, the terms sharding and partitioning are even used synonymously, especially when preceded by the terms “horizontal” and “vertical.” Thus, “horizontal sharding” and “horizontal partitioning” can mean the same thing.
Hazelcast, by tradition, uses the term partitions for its different segments of data. Hazelcast’s partitions provide all the advantages of shards in terms of scalability as well as providing excellent data redundancy for business continuity through replication of the partitions across nodes in the Hazelcast cluster.
So, in general:
Database Sharding
- Involves dividing a database into smaller, autonomous units (shards), typically distributed across multiple servers
- Each shard contains a subset of the data and is responsible for specific data ranges or attributes
- Often employed in distributed systems to improve scalability and performance
- Requires a mechanism to route queries and transactions to the appropriate shard
Database Partitioning
- Divides a database into smaller logical units, but these units are not necessarily autonomous like shards
- Partitions can be located on the same server or within a single database
- Aims to organize data for better manageability and performance, often based on attributes like date, region, or key ranges
- Does not involve distributing partitions across multiple servers as a fundamental requirement but that is often done to preserve data in case of the loss of individual nodes
In summary, while both Sharding and Partitioning aim to organize data, Sharding specifically focuses on distribution across multiple servers for scalability though partitioning often does the same thing.
Types of Sharding
There are different criteria you can use to separate your data into various shards. The criteria you use may depend on your application, the structure of your data, your system architecture, geography, and your desires for scalability. Here are four major types of Sharding:
1. Range-Based Sharding (sometimes called Dynamic Sharding)
Range-based Sharding involves dividing data based on specific data ranges or intervals, such as a range of dates, numeric values, or alphanumeric identifiers. This method is suitable when data exhibits a natural ordering, and queries often target specific ranges. For instance, an e-commerce application may use range-based Sharding to distribute order data by date ranges.
Advantages of range-based sharding:
- Efficient for range queries because data is distributed in an orderly manner
- Facilitates data archiving and purging by dropping entire shards.
- Suitable for time-series data and historical records
Challenges of range-based sharding:
- Imbalanced shard sizes if data distribution is uneven
- Challenges in handling skewed data distribution
- Limited flexibility when dealing with non-uniform data access patterns
2. Hash-Based Sharding (also called Algorithmic or Key-based Sharding)
Hash-based Sharding involves using a hash function to determine which shard a particular piece of data belongs to. The hash function takes some or all of the data's attributes and maps them to a shard identifier. This method is often used when there is no natural ordering of data or when even data distribution is essential. Hazelcast Platform uses a hashing algorithm to distribute data across its partitions (or shards).
Advantages of hash-based sharding:
- Evenly distributes data, preventing hotspots or imbalanced loads.
- Suitable for situations where the order of data is not important.
- Scalable and easy to implement.
Challenges of hash-based sharding:
- Retrieving a specific range of data can be complex.
- Shard rebalancing can be challenging as data volume grows.
- Adding or removing shards may require reshuffling data.
3. Directory-Based Sharding
Directory-based Sharding, also known as metadata-based Sharding, employs a separate service or metadata store to maintain a mapping of data to shards. Each piece of data contains metadata or attributes that describe which shard it belongs to. Directory-based Sharding offers flexibility in distributing data based on a variety of criteria, including business logic and data attributes.
Advantages of directory-based sharding:
- Flexible and adaptable to complex distribution needs.
- Eases the process of shard management and rebalancing.
- Supports dynamic changes to data distribution rules.
Challenges of directory-based sharding:
- Adds complexity with the need for a separate metadata service.
- Performance overhead due to metadata lookups.
- Potential single point of failure in the metadata service.
4. Geo-Based Sharding
Geo-based Sharding is particularly relevant for distributed systems and applications with global reach. In this method, data is divided based on the geographical location or proximity of the data sources or users. It ensures that data closer to the users is stored in nearby shards, reducing latency and improving performance. Geo-based Sharding is commonly used in content delivery networks (CDNs) and global-scale applications.
Advantages of geo-based sharding:
- Reduced latency and improved user experience for global applications.
- Efficient for geospatial queries and location-aware applications.
- Geographic redundancy for disaster recovery and fault tolerance.
Challenges of geo-based sharding:
- Complex to implement due to the need to determine data location.
- Maintaining consistent data distribution across geographical regions can be challenging.
- Sensitive to changes in user distribution and access patterns.
Benefits of Sharding
Database sharding offers several key benefits:
- Scalability: Sharding allows databases to scale horizontally by distributing data across multiple servers. As data volume and user load increase, additional shards can be added to accommodate the growth, ensuring system performance remains stable.
- Improved Performance: By distributing data and workloads, Sharding can significantly enhance query performance and reduce response times. Users experience quicker access to data because requests are spread across multiple shards.
- Fault Tolerance: Sharding provides built-in fault tolerance. If one shard or server fails, the system can continue to operate, as other shards are still operational. This ensures high availability and data durability.
- Efficient Resource Utilization: Sharding optimizes resource usage by distributing data and workloads evenly. This reduces the risk of resource bottlenecks and maximizes hardware utilization.
- Data Isolation: Sharding can isolate data, making it easier to manage and secure. Different shards can have their access control policies and security settings.
Challenges of Sharding
Sharding also comes with its share of challenges:
- Complexity: Sharding introduces complexity to database architecture. It requires careful planning, monitoring, and maintenance. Additionally, choosing the right Sharding key and method can be challenging.
- Data Distribution Issues: Ensuring even data distribution across shards can be tricky, especially when dealing with skewed data access patterns. Poor data distribution can lead to imbalanced shard sizes.
- Shard Management: Managing a large number of shards can become cumbersome. Shard creation, deletion, and rebalancing require careful coordination and automation.
- Data Consistency: Maintaining data consistency across multiple shards is challenging. Distributed transactions and ensuring strong data consistency can be complex and may impact performance.
- Query Complexity: Some queries may span multiple shards, requiring a coordination mechanism to retrieve, merge, and present data coherently. Complex queries can impact query performance.
- Single Points of Failure: Some Sharding architectures may introduce single points of failure, particularly when using directory-based Sharding with a centralized metadata service. Ensuring high availability becomes crucial.
How to Implement Sharding?
Implementing Sharding in a data management system involves several key steps:
- Data Modeling: Determine the Sharding key, which is the attribute or combination of attributes used to determine how data is distributed across shards. The choice of sharding key greatly influences performance and data distribution.
- Shard Creation: Create and provision the shards where data will be distributed. Shards can be physical servers, virtual machines, or containers, depending on the system architecture.
- Data Migration: Move existing data into the shards based on the chosen sharding key. Data migration tools and scripts can simplify this process.
- Query Routing: Develop a query routing mechanism that directs user queries and transactions to the appropriate shard based on the Sharding key. This often involves a middleware layer responsible for routing.
- Shard Management: Implement tools and processes for shard management, including adding or removing shards, rebalancing data, and handling shard failures.
- Monitoring and Maintenance: Implement monitoring and maintenance processes to ensure the health and performance of the Sharded database. This includes monitoring for imbalanced shard sizes, high query latencies, and hardware failures.
Sharding in Real-World Applications
Sharding is widely used in various real-world applications and industries to address scalability and performance requirements. Some notable examples include:
- Social Media Platforms: Social media companies use Sharding to manage massive amounts of user-generated content, such as posts, photos, and videos. Sharding ensures fast access to user data and high availability.
- E-commerce: Online retailers employ sharding to handle large catalogs of products and accommodate high website traffic. Sharding is essential for managing order data and inventory.
- Gaming: Online gaming platforms use Sharding to distribute game state data and player profiles. Sharding ensures low-latency gaming experiences, even in globally distributed multiplayer games.
- Financial Services: Financial institutions rely on Sharding to manage vast amounts of transaction data, customer records, and financial histories. Sharding enhances performance and data security.
- Content Delivery Networks (CDNs): CDNs utilize geo-based sharding to cache and deliver web content efficiently to users worldwide. Data is distributed to edge servers close to end users to reduce latency.
- IoT and Telemetry: Internet of Things (IoT) platforms leverage sharding to manage the massive influx of data generated by sensors and devices. Sharding helps process and analyze telemetry data in real-time.
Conclusion
Sharding is a powerful technique for enhancing the scalability and performance of database systems. By dividing data into smaller, manageable units and distributing them across multiple servers or storage systems, sharding enables large-scale applications to handle extensive data volumes, user loads, and concurrent operations.
Understanding the different types of sharding, such as range-based, hash-based, directory-based, and geo-based, is crucial for selecting the most suitable approach for a given application. While sharding offers many benefits, it also introduces complexities and challenges that require careful planning, monitoring, and management. When implemented effectively, sharding is a key enabler for high-performance, distributed systems in the digital age.
Sharding is a method of splitting and storing a single logical dataset in multiple databases. By distributing the data among several machines, sharding allows for horizontal partitioning, effectively boosting the performance of applications that rely on massive databases.