What is In-Memory Computation?
In-memory computation (or in-memory computing) is the technique of running computer calculations entirely in computer memory (e.g., in RAM). This term typically implies large-scale, complex calculations which require specialized systems software to run the calculations on computers working together in a cluster. As a cluster, the computers pool together their RAM so the calculation is essentially run across computers and leverages the collective RAM space of all the computers together.
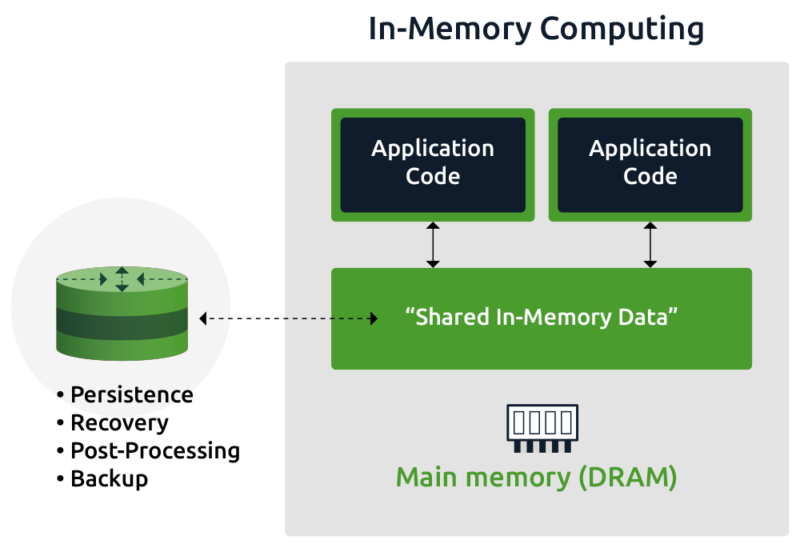
This term is mostly synonymous with in-memory computing and in-memory processing, with perhaps a slightly nuanced difference where in-memory computation is a specific type of task dealing with calculations, that falls under the umbrella of in-memory computing. In-memory processing can be considered a different type of task that also falls under in-memory computing.
How Does In-Memory Computation Work?
In-memory computation works by eliminating all slow data accesses and relying exclusively on data stored in RAM. Overall computation performance is greatly improved by removing the latency commonly seen when accessing hard disk drives or SSDs. Software running on one or more computers manages the computation as well as the data in memory, and in the case of multiple computers, the software divides the computation into smaller tasks which are distributed out to each computer to run in parallel. In-memory computation is often done in the technology known as in-memory data grids (IMDG). One such example is Hazelcast IMDG, which lets users run complex computations on large data sets across a cluster of hardware servers while maintaining extreme speed.
Example Use Cases
One use case of in-memory computing is the modeling of complex systems using a large set of related data points. For example, the modeling of weather data is used to help understand the current trends around events such as storms. Millions or even billions of data points are captured to represent various weather-related measurements, upon which calculations are run to identify the likely patterns the storms will take. With so much data to process, eliminating slow disk accesses will help run the calculations in a much shorter time window.
Another example use case is running data-intensive simulations. For example, in a Monte Carlo simulation (or Monte Carlo method), a number of possible events, all of which have some effect on a final outcome, are first assigned a probability. Then as a first pass, the computation will designate whether each event occurred, and perhaps to what level, using random selections based on the assigned probability of each event. This process is repeated multiple times, and each outcome is aggregated into a summary of all the possible outcomes, and the likelihood of each. Banks, for example, use this simulation technique to measure counterparty risk (i.e., the risk associated with doing business with another entity), which is dependent on many different possible events, including an increase in interest rates. As a simple example of an outcome, a bank could run the simulation to see how likely the third-party they are negotiating with will still be in business in 5 years, as well as how likely the third-party will default on a contract. Such a simulation requires a lot of data and many calculations for each run of the simulation, so it needs to be run in an environment that was designed for speed and scale.