
Chief Product Officer
David has travelled the world, helping people make sense of low-latency, in-memory technology solutions. With 30 years in the IT industry, he began his career as a Cobol programmer before moving into investment banking IT as a java developer and architect. During this time, David developed a deep interest in distributed systems research, focusing on consensus and reliability. Today, David is Chief Product Officer at Hazelcast where he is helping expand the portfolio from its core In-Memory Data Grid offering to address new use cases such as Stream Processing, Cloud Managed Services & Digital Integration.
View all blogs by the authorMar 14, 2019
In-Memory Data Grids Popularity Trend Continues Upward
The past year has seen in-memory data grids (IMDG) continue to gain traction with the development community and large organisations alike. As you’ll see in the 2019 IMDG LinkedIn Survey results below, adoption of IMDG as a skill in LinkedIn profiles has risen by 43% YoY. Companies are turning to IMDGs as replacements for RDBMS and NoSQL solutions that struggle to perform at scale. The trend sees IMDGs used as a cornerstone for projects related to Digital Transformation strategies. A key driver for adoption is the ease in which IMDGs drop into new deployment platforms, such as Kubernetes and Cloud, an area in which traditional processing data stores struggle. IMDGs are a viable option over a NoSQL solution for varied technical reasons.
Easier to scale out
Cluster members co-ordinate amongst themselves for their share of partitioned data. There is no third party coordination as is the case with most NoSQL solutions. Each member of an IMDG cluster handles a portion of primary data partitions and a similar number of replica partitions. There is no concept of master or replica processes.
A better option for varied data retrieval
Some NoSQL solutions like Redis require knowledge of the key; there is no facility to query data based on a property. Instead, users have to maintain multiple data structures with the property as a key, known as reverse indexes. IMDGs offer key-based retrieval and SQL like queries where only properties are known, in much the same way as a relational database operates.
Faster data retrieval
IMDGs have a facility called near caches, which allow frequently read data to be stored in a cache within the client to the cluster. This means that once read, the value will stay in the client process memory space until the value changes in the central cluster, at which time the cluster sends an invalidation message to the client. Popular NoSQL solutions do not offer this. General data retrieval from the cluster to a client is also faster, and everything is stored in-memory.
More efficient under mixed workloads
IMDGs are multi-threaded, whereas most NoSQL stores, like Redis, are single threaded. Single threads impact performance under varied workloads, for example, when a Redis Lua Script is being run for a compute job in the cluster no other transactions within that process can proceed. This can be particularly problematic if the script is long running. For IMDGs throughput can be maintained with multiple compute jobs and data retrieval operations at the same time. MongoDB does not offer a distributed compute facility at all.
Are much more than just a Data Store
IMDGs are not only an excellent choice as an elastic and resilient in-memory data store. They can also be used as a framework to build your own Distributed Systems. Most IMDGs now provide various atomic and lock APIs that aid in the building of services, pair this with the excellent event callbacks available for data mutations and IMDGs become a valuable tool for building microservice architectures.
Embeddable
The IMDGs reviewed in this blog are Java-based libraries. This means you can embed a cluster and the data structures directly within your applications. With NoSQL, you are forced to use a Client-Server architecture.
2019 IMDG LinkedIn Survey Results
The survey is a search for jobs and profiles based on the keyword of the IMDG product. It’s simple enough to verify the results found here independently. Some open source projects identify themselves differently than their commercial product namesakes, such as Pivotal Gemfire and Apache Geode. Where there are two names, I have searched for both and combined the results. This may lead to a double count in some instances, so for these products the results may be artificially increased. Other products, such as Hazelcast, carry the same name for their open source and commercial versions.
I’ve chosen what I consider to be the top 5 IMDGs, four of them are open source and one, Oracle Coherence is proprietary closed source.
- Hazelcast
- Oracle Coherence
- Gemfire / Apache Geode
- GridGain / Apache Ignite
- JBoss Data Grid / Infinispan
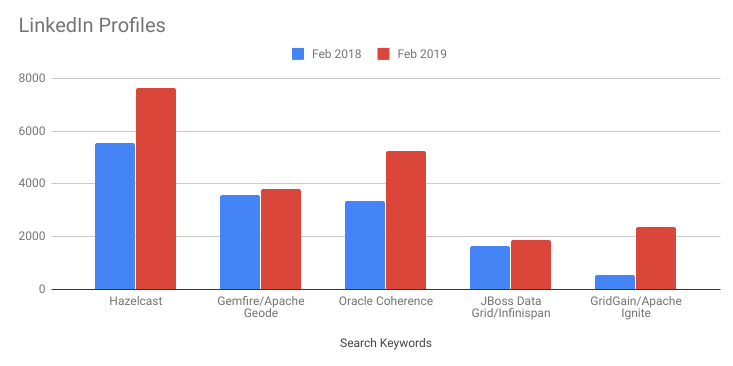
IMDG Products mentioned in LinkedIn Profiles.
People mentioning an IMDG as a skill in their LinkedIn profile has grown by 43% YoY over 2018. A vital statistic and useful indicator of IMDG popularity with engineers and businesses alike. This is an indicator of the available talent pool, an important consideration when weighing up IMDG products against each other. This metric alone can have a strong influence on IMDG product selection within businesses.
| Search Keywords | Feb 2019 |
|---|---|
| Hazelcast | 7,623 |
| Oracle Coherence | 5,261 |
| Gemfire/Apache Geode | 4,031 |
| GridGain/Apache Ignite | 2,376 |
| JBoss Data Grid/Infinispan | 1,891 |
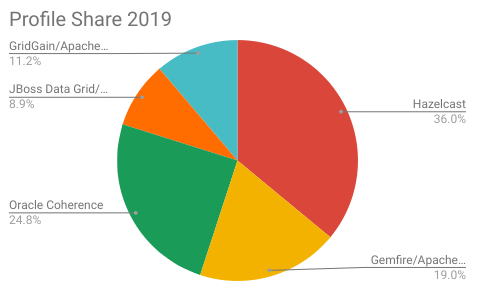
All of the IMDGs listed here increased their profile count, Hazelcast maintained and expanded the lead it held in 2018. Second and Third places were swapped, with Oracle Coherence surprisingly pulling ahead of Pivotal Gemfire. Apache Ignite has pulled itself off from the bottom of the table with Infinspan dropping to take the wooden spoon.
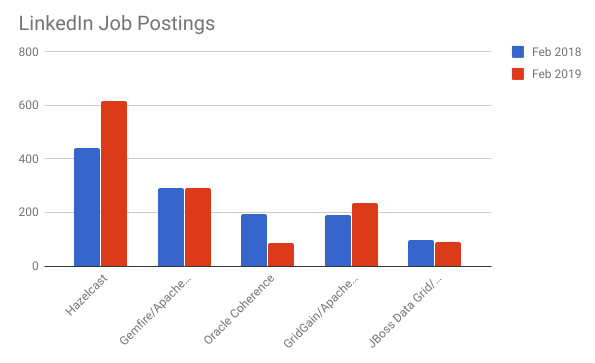
IMDG Product Job Listings
Job listings are another great indicator of IMDG popularity and as mentioned, this metric is up from 2018 for all of the IMDG products we searched except for Oracle Coherence. No movement at the top, with Hazelcast staying in place as the IMDG with most job opportunities. Hazelcast has twice as many job openings as the second nearest, Pivotal Gemfire. 2018 saw a significant drop in requirements for Oracle Coherence positions.
| Search Keywords | Feb 2019 |
|---|---|
| Hazelcast | 617 |
| Gemfire/Apache Geode | 290 |
| GridGain/Apache Ignite | 235 |
| JBoss Data Grid/Infinispan | 91 |
| Oracle Coherence | 85 |
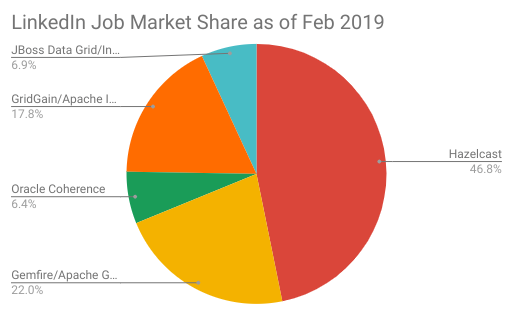
Search conducted on 11th February 2019
Conclusion
The Trend for IMDGs is most definitely increasing as evidenced by the data above, that said, they’re still a relatively unknown resource. IMDGs can take their place alongside NoSQL and RDBMS in a multi-faceted solution. More and more architects realize that a NoSQL solution on its own will not solve their future data storage and processing requirements. A wider variety of more adaptable data solutions are required and for this architects are turning to IMDGs. Many IMDGs have been developing complementary solutions based on the core IMDG platform, for example, Hazelcast Jet which is an in-memory streaming platform that provides stream processing at ingestion rates far exceeding competing disk bound solutions such as Apache Flink or Apache Kafka Streams. Once again these solutions come with the added benefit of out-of-the-box cluster coordination. No extra processes are required, such as a Zookeeper instance.
The original version of this blog can be found at davebrimley.com.