Distributed Task Coordination with Hazelcast
Mike Pilone recently published a blog post entitled, “Distributed Task Coordination with Hazelcast“. In the post, Mike presents a method for using Hazelcast to coordinate tasks across a small deployment, with minimal additional hardware or software required, while supporting flexible task allocation and management.
The Problem
Every small to large scale application has some number of tasks that run in the background to perform various functions such as batch processing, data export, reconciliation, billing, notifications, etc. These tasks need to be managed appropriately to not only ensure that they run when expected, but to ensure that they run in the correct environment on the correct nodes. In modern applications, microservice architectures are becoming more popular as an alternative to monolithic applications deployed in heavyweight application servers.
At the hardware level, virtual machine deployments, containerization, and multiple region/zone support are desired to support failover, scaling, and disaster recovery. Coordinating tasks in these multi-service, multi-machine, multi-zone environments can be challenging even for small scale projects.
While there are existing solutions to coordination, scheduling, and master election problems, many require additional hardware or database architectures that may not be reasonable for all applications. This document presents a method for using Hazelcast, an open source in-memory data grid, to coordinate tasks across a small deployment with minimal additional hardware or software required while supporting flexible task allocation and management.
Use Cases
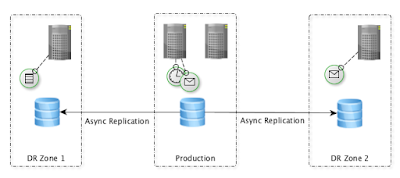
In many applications, there will be multiple production nodes to support load balancing and fail-over as well as one or more off-site standby nodes to support disaster recovery. Depending on the application, background tasks may be needed to perform scheduled operations such as exporting data, sending notifications, cleaning up old data, generating billing invoices, data reconciliation, etc. To avoid issues such as double billing or emailing a customer twice, jobs should be executed once and only once across the cluster. It may be desirable to run some jobs, such as report generation, at a warm/read-only standby site to reduce the load on the production system. During maintenance periods, it may be desirable to pause specific tasks to avoid errors or to reduce load.
Managing these tasks across the cluster requires some kind of distributed or shared coordinator that can allocate the tasks appropriately. While the description sounds rather simple, successfully implementing and handling master elections, availability, network partitioning, etc. is extremely challenging and shouldn’t be approached lightly. Reusing an existing, tested, proven solution is very valuable.
Existing Solutions
Coordinating an application across multiple services, nodes, and zones is not a new problem and there are existing solutions; however these solutions have a number of drawbacks that may cause them to not be usable in the existing application architecture or require additional hardware or software beyond what the project is already using. For small scale projects, some of these solutions may double the amount of hardware required to simply coordinate which node should run a nightly cleanup job. That being said, it is important to not reinvent the wheel if one of the existing solutions would fit into the application’s existing hardware and software architecture so it is wise to review the options. A few of the more common options are presented here but this is by no means an exhaustive list.
Single Master Election
In the simplest scenario, a cluster can elect a master node using a master election algorithm such as the Rift Consensus Algorithm. Once a master is elected, that node is responsible for executing all tasks to ensure that the task only runs on a single node. This approach is relatively simple, especially if an existing implementation of a master election algorithm can be used; however it offers very little in the way of flexibility. There is no way to run tasks on different nodes or to pre-allocate tasks to specific zones such as running reporting tasks on a warm-standby site. There can also be an issue if the master is elected as a site that is in a warm-standby mode with a read-only database or other such limiting configuration. If the application requirements are simple enough that a single master running all tasks will work, it is a reasonable and well understood approach to take.
Shared Database
One of the simplest ways to coordinate across services may be to use the application’s existing database to enumerate configuration information, lock names, or task schedules. As long as this database is accessible to all the nodes in the system, this method works well. For example, a single “locks” table could be used with each node performing a “select for update” operation to acquire the lock. If the locks are timed, they can be automatically released in the event that a node crashes.
While this approach is very common and can work in many scenarios, there are some drawbacks. First, all the nodes must access a common database or a synchronous replica. If asynchronous replication is in use, there is a chance that two nodes accessing two different databases are allowed to acquire the same lock. Depending on the task being executed, this could be very problematic. Second, depending on the database replication support, some nodes may be read-only (warm standby) replicas which do not allow updating and therefore do not allow the nodes using those databases to acquire locks. When using the shared DB solution, a dependency between the DB replication scheme and task allocation develops which may not be desirable. Third, and finally, not all applications are using relational style databases that make the “select for update” operation easy or even possible. Some append only databases or in-memory database solutions may not work well for mutual exclusion/row locking type of functionality by preferring performance and eventual consistency over synchronous locking.
Zookeeper and the Like
ZooKeeper is an Apache project that enables distributed coordination by maintaining configuration information, naming, providing distributed synchronization, and providing group services. It is a well proven solution that should be considered when looking for a task coordination solution. There are also many similar alternatives such as Eureka, etcd, and consul that each offer their own pros and cons. While ZooKeeper and the like are powerful solutions, they can be complex to configure properly and may require additional hardware. For a large devops team with a large deployment footprint, these additional requirements may not be an issue. However take an example of a two node application production cluster and an additional one node disaster recover site. ZooKeeper’s three node minimum could double the hardware required for this small deployment depending on the configuration.
Some of the related solutions offer distributed key/value pairs which allow for ultimate flexibility but also require additional logic to be implemented in the application by providing the bare minimum master election and data replication logic. Depending on the application language, some of these solutions may be difficult to integrate or maintain by requiring additional runtimes or configurations. Again, for larger projects this may be well worth the investment but for smaller projects it could add to the overall project deployment and maintenance costs.
Quartz and Scheduling
Quartz, a popular Java task scheduling library, supports cluster scheduling to coordinate the execution of a task once and only once in a cluster. However this solution, and many solutions like it, simply fall back to using one of the other solutions such as a shared DB, ZooKeeper, etc. to perform the heavy lifting. Therefore a “clustered” scheduler is not a solution in itself, but simply builds on an existing distributed coordination solution.
Enter Hazelcast
Hazelcast is an open-source in-memory data grid that offers a number of compelling features including:
- Distributed data structures
- Distributed compute
- Distributed query
- Clustering
- Caching
- Multiple language bindings
- Easily embeddable in a Java application
This feature set makes Hazelcast a multi-use tool in an application. It can be used for simple messaging, caching, a key/value store, and, as described in the remainder of this document, a task coordination service. Unlike some of the other services previously described, Hazelcast can be leveraged to solve multiple problems in an application besides just distributed configuration and coordination. Being designed as a distributed memory-grid from the beginning, Hazelcast solves many of the hard underlying problems such as master election, network resiliency, and eventual consistency. A full description of Hazelcast, its features, and configuration are beyond the scope of this document so it is recommended to read the reference manual for more details. A basic understanding of Hazelcast or in-memory data grids is assumed for the remainder of this document.
The general concept of the Hazelcast task coordination solution is to store semaphore/lock definitions in-memory and to coordinate the allocation of semaphore permits to nodes based on criteria such as the node name, the zone name, and the number of permits available. To handle a node dropping out of the cluster, the semaphore permits support time based expiration in additional to explicit release. All of the clustering, consistency, and availability requirements will be delegated to Hazelcast to make the solution as simple as possible.
Semaphore Definitions and Permits
Hazelcast exposes the in-memory data through the well known Java data structure interfaces such as List, Map, Queue, and Set. While Hazelcast does expose a distributed implementation of a Semaphore, this solution introduces the concept of a SemaphoreDefinition and SemaphorePermit to allow for more complex permit allocations and expiration.
SemaphoreDefinition
To support functionality such as multiple permits per semaphore, node (acquirer) name pattern filtering, and zone (group) name pattern filtering, a SemaphoreDefinition class is used. The class is a basic structure that tracks the definition configuration. There is one such definition for each semaphore or task that is to be controlled. For example, there may be a definition for a “billing reconciliation” task or a “nightly export” task. The semaphore definition is composed of the following fields:
- Semaphore Name: The name clients will use when requesting a semaphore permit.
- Group Pattern: A regular expression that must match the group name reported by the client. If the group doesn’t match, the permit will be denied. Groups can be used to control zone/environment/site access to permits.
- Acquirer Pattern: A regular expression that must match the client name reported by the client. If the acquirer doesn’t match, the permit will be denied. Acquirers can be used to control individual node access to permits.
- Permits: the number permits that can be allocated for a given semaphore. In some cases it is desirable to issue multiple permits while in others a single permit can be used to enforce exclusivity.
- Duration: the amount of time the client can hold the permit before it will automatically release. The client must re-acquire before this time or risk losing the permit.
In the current implementation, the definitions are loaded into Hazelcast after a fixed delay to allow other nodes to come on-line and synchronize. Therefore if the definitions are already loaded, they are visible to the new client or member without reloading them from configuration. It would also be possible to use Hazelcast’s support for data persistence to permanently store and recover the definitions once loaded.
The Gatekeeper
With the semaphore definitions loaded into a Hazelcast data structure, clients can begin to request permits for specific semaphore names. The “gatekeeper” is responsible for enforcing the rules of the semaphore definition when a permit is required. There are a number of ways to implement the gatekeeper depending on the Hazelcast configuration selected for the application. For example, if each microservice in the application is a full Hazelcast data member or a client, the gatekeeper could be implemented as a shared library to be included in each component. However if the Hazelcast data is exposed as an independent service in the application using the existing application communication architecture (e.g. JMS, REST, etc.), the gatekeeper may be a top-level service in the application that receives requests for permits and issues replies.
The key is that there is some part of the application responsible for implementing the permit allocation logic. When a client makes a request for a permit, either through a library or application service, the gatekeeper is responsible for the following logic:
- Check if there is a definition matching the requested name. If no, return denied.
- Check if the acquirer’s group name matches the definition by applying the regex. If no, return denied.
- Check if the acquirer’s node name matches the definition by applying the regex. If no, return denied.
- Check if the acquirer already holds a valid permit. If yes, simply refresh the expiration and return success.
- Check if there is free permit available. If yes, allocate it to the acquirer and return success.
- Return denied.
The gatekeeper is also responsible for periodically releasing permits once the expiration date expires. This ensures that nodes that may be removed from the cluster due to crashing or being shutdown cannot hold resources indefinitely.
Pessimistic Permit Acquisition
To coordinate the allocation of a permit across the cluster, a Hazelcast Lock can be used to control access to a Map of semaphore names to granted permits. When a request comes in for a permit, the gatekeeper can acquire the lock, examine the existing permits, and make a decision on allocating the requested permit. Once the decision is made, the Map of semaphore permits can be updated and the lock released. This pessimistic approach makes use of Hazelcast’s distributed lock support to ensure a single reader/writer to the existing permits.
final static String KEY_PREFIX = "gatekeeper";
ConcurrentMap definitionMap = hazelcast.getMap(KEY_PREFIX + ".semaphoreDefinitions");
ConcurrentMap permitMap = hazelcast.getMap(KEY_PREFIX + ".semaphorePermits");
Lock gatekeeperLock = hazelcast.getLock(KEY_PREFIX + ".lock");
if (gatekeeperLock.tryLock(LOCK_WAIT_PERIOD, TimeUnit.SECONDS)) {
try {
// Logic:
// - Lookup the definition
// - Check the group and acquirer pattern
// - Check for an available permit
// - Issue the permit
}
finally {
if (gatekeeperLock != null) {
gatekeeperLock.unlock();
}
}
}
This approach is simple to implement and with a limited number of semaphores and requesting clients it should be plenty fast enough. One issue that was found during testing with this approach is that occasionally if a Hazelcast member held the lock and dropped out of the cluster, the lock would not be released on the remaining members. This issue may be related to the specific Hazelcast version (now out-dated) but it is a scenario to test thoroughly.
Optimistic Permit Acquisition
To coordinate the allocation of a permit across the cluster, the replace(…) method can be used on a Hazelcast ConcurrentMap implementation of semaphore names to granted permits. When a request comes in for a permit, the gatekeeper can retrieve the existing permits and make a decision on allocating the requested permit. Once the decision is made, the Map of semaphore permits can be updated using the replace operation to ensure that the permits for the semaphore in question were not changed since the request began. This optimistic approach does not require a distributed lock but rather relies on Hazelcast’s implementation of the replace(…) operation to detect concurrent modification of the existing permits.
final static String KEY_PREFIX = "gatekeeper";
ConcurrentMap definitionMap = hazelcast.getMap(KEY_PREFIX + ".semaphoreDefinitions");
ConcurrentMap permitMap = hazelcast.getMap(KEY_PREFIX + ".semaphorePermits");
// Logic:
// - Lookup the definition
// - Check the group and acquirer pattern
// - Check for an available permit
// - Issue the permit
if (!permitMap.replace(semaphoreName, origPermits, updatedPermits)) {
throw new OptimisticLockingFailureException("Conflict "
+ "while updating semaphore permits.");
}
This approach is again simple to implement and depending on the permit request/allocation pattern of the application, it does not require any external lock management. Because there is no locking required, when a permit is denied (which will be the more common case because only a single node will usually get the permit), there is little to no coordination cost across the cluster. If the replace operation fails, the permit map can be reloaded from Hazelcast and the operation can be performed again.
The Gatekeeper Semaphore
With the gatekeeper controlling access to the permits and using Hazelcast to coordinate and track permit acquisition across the cluster, the remaining piece of the solution is the client side request to acquire permits. A semaphore is implemented by passing requests to the gatekeeper while exposing an API consistent with existing Java Semaphores. Unfortunately there is no standard Semaphore interface in Java, but the basic acquire(…), tryAcquire(…), and release(…) method names can be used to remain consistent. Additional methods such as getExpirationPeriod(…) and refresh(…) can be added to expose the concept of an expiring semaphore if desired.
public boolean tryAcquire(int timeout) {
SemaphorePermit permit = new SemaphorePermit(semaphoreName, groupName,
acquirerName, null);
// Delegate to the gatekeeper which enforces the permit rules based
// on the semaphore definition. The gatekeeper might be a local library
// or a call to a remote service.
permit = gatekeeperGateway.tryAcquire(permit);
Date expirationDate = permit.getExpirationDate();
if (expirationDate == null) {
// We didn't get the permit. Either sleep or expire the attempt.
// ...
}
else {
// We got the permit. Return true.
// ...
}
}
The gatekeeper semaphore implementation uses the gatekeeper either via a shared library or a service request to acquire a permit. The permit request is composed of the following fields:
- Semaphore Name: The name of the semaphore for which to get a permit.
- Group Pattern: The name of the group that the client is in. Normally this is used for different environments or zones such as “production”, “dr-site”, “east-coast”, or “west-coast”
- Acquirer Pattern: The name of the acquiring node. Normally this is the hostname and it is used to select specific machines to run a task such as “app1”, “app2”, “db1”, or “db2”.
Services that need to execute tasks simply acquire a permit from the semaphore just like in any multi-threaded context. The permit request is handed off to the gatekeeper and a decision is made at the Hazelcast cluster level across all nodes and zones. The semaphore can be hidden within the scheduling framework itself so the end user doesn’t need to use it directly. For example, the Spring Framework TaskScheduler could be implemented to wrap Runnable tasks in a class that attempts to acquire a permit before executing the target task.
Controlling and Moving Tasks
The gatekeeper on top of Hazelcast combined with the gatekeeper semaphore implementation effectively coordinates and controls tasks execution across the cluster; but a static configuration isn’t entirely useful as the tasks may need to migrate around the system to support maintenance activities, fail-over, or disaster recovery. With the semaphore definitions stored in Hazelcast, they can be edited in-memory to cause tasks to migrate by adjusting the group pattern, acquirer pattern, permits, and duration fields. The editing functionality can be built into the gatekeeper service or it can be done by an external tool by directly modifying the semaphore definition data in the cluster. The screenshot below demonstrates how the definitions could be edited live with an example user interface. The user can edit any of the semaphore definitions to restrict it to a specific acquirer or group in the cluster. As the permits expire or are released, the new acquirers will be restricted and the tasks will migrate to the appropriate group and/or acquirer automatically. By using a group name that doesn’t exist, such as “no-run”, tasks can be effectively paused indefinitely.

Another powerful feature is mass migration from one group/zone to another. For example, in the event of an emergency or large scale maintenance, a simple script could update the semaphore definitions in a batch to change the group pattern effectively moving all the tasks to a different zone. Because Hazelcast handles data replication and availability, the change to the definitions can be made on any member in the cluster and it immediately becomes visible to all members.
In addition to the semaphore definition UI, the gatekeeper can periodically dump state information to a log file to help with debugging and monitoring. The example output below shows the type of information that can be easily displayed and searched by any log management tools.

Limitations
Hazelcast is designed to prefer availability over consistency; therefore in a split-brain, network partition scenario, Hazelcast will remain available on each side of the network partition and could potentially allow more than one node to acquire a semaphore permit. Depending on your network structure, acquirer and group patterns, and sensitivity to duplicate executions in these scenarios, a quorum solution may be more appropriate. One approach may be to use Hazelcast’s Cluster information to implement a quorum check as part of the gatekeeper logic.
It is important to note that there may be a delay from when a semaphore definition is updated to when the task can start on the new node/group depending on if the existing permit owner releases the permit or simply lets it expire. For tasks that may run every few minutes or hours this probably isn’t an issue. However if the application has strict task failover or migration time requirements, allowing permits to expire at a fixed duration may not be acceptable.
Wrapping Up
The solution presented is not a turnkey library or framework but it shows how Hazelcast can be used to perform task coordination and control with just a little custom code. For more complex applications or larger deployments, an existing tool such as ZooKeeper or etcd may be more appropriate but a simpler approach may make sense for a number of use cases including:
- The application is already using Hazelcast for caching, distributed computing, or messaging.
- More flexibility/customization for task coordination is needed than an existing solution offers.
- There is no shared database or the task coordination scheme is incompatible with the database replication scheme.
- The solution should be embedded in the existing application/services rather than requiring additional hardware or processes.
If you’re looking for a powerful and flexible communication, coordination, and control mechanism for your application, checkout the Hazelcast documentation and see if it can work for you. As a distributed in-memory grid exposing basic data structures and distributed computing functionality, it can take over or be the foundation for many of the more complex requirements of microservices architectures.