
By Greg Luck
Chief Technical Officer
Greg Luck is a leading technology entrepreneur with more than 15 years of experience in high-performance in-memory computing. He is the founder and inventor of Ehcache, a widely used open source Java distributed cache that was acquired by Software AG (Terracotta) in 2009, where he served as CTO. Prior to that, Greg was the Chief Architect at Australian start-up Wotif.com that went public on the Australian Stock Exchange (ASX:WTF) in 2006. Greg is a current member of the Java Community Process (JCP) Executive Committee, and since 2007 has been the Specification Lead for JSR 107 (Java Specification Requests) JCACHE. Greg has a master's degree in Information Technology from Queensland University of Technology and a Bachelor of Commerce from the University of Queensland.
View all blogs by the authorApr 29, 2019
Hazelcast Responds to Redis Labs’ Benchmark
UPDATE (9/4/19): I posted a new blog that showcases how we believe Redis achieves the performance in its benchmarks.
Due to its underlying architecture and many years of optimization, Hazelcast is extremely fast and dramatically outperforms Redis Labs (and Redis open source), especially at scale.
Last year, Redis Labs published a very misleading benchmark against Hazelcast. We have closely investigated Redis Labs’ test and discovered many misleading aspects of the benchmark. As a result, we have reproduced the test with these issues corrected.
The Facts
It is difficult to avoid the conclusion that Redis Labs knew it was manipulating the desired outcome. Here are the facts:
- ZERO TRANSPARENCY: Firstly, the benchmark configuration was closed source. There are some snippets in the blog post, but not the full configuration used for the test. Hazelcast publishes its source code and configuration for competitors and customers to reproduce the benchmark.
- INTENTIONALLY DIFFERENT TOOLS: Redis Labs’ benchmark compares the performance of memtier_benchmark driving C++ clients against Redis Enterprise versus RadarGun driving Java clients against Hazelcast open source. This is invalid. You must use the same benchmarking tool and the same programming language; otherwise, you’re comparing apples and oranges, which is the case with the Redis Labs benchmark.
- INTENTIONALLY OVERLOADING GARBAGE COLLECTION: The dataset size was 42GB, run on three Hazelcast nodes. With Hazelcast defaults, this would typically mean 84GB of data. Heap size per JVM would, therefore, have to be at least 30GB (28GB of storage and 2GB of working space). Hazelcast recommends the use of Hazelcast Enterprise HD instead of running large heap sizes, due to the limitations of garbage collection (GC), when running on a smaller number of nodes. GC alone would be enough to make Hazelcast run slowly. Note that as an alternative and to alleviate GC issues, Hazelcast Open Source can run on more nodes each with smaller heap configurations. Redis Labs had options on how to configure the data within Hazelcast; they chose not to use them.
- SKEWING OF DATA SIZES: The sample data sizes were different between the two benchmarks. With memtier_benchmark Redis Labs used a random distribution of value lengths between 100 bytes and 10KB. RadarGun uses fixed size values of 10KB and is not able to generate a random distribution. So the Redis Labs benchmark, on average, will use 5KB values, while the Hazelcast benchmark will use 10KB values. This means that the Redis Labs benchmark is using half the network bandwidth compared to the Hazelcast benchmark. After correcting this, Hazelcast performance doubled.
- INTENTIONALLY LOW THREAD COUNT: The benchmark uses a single thread per client. We found this very strange as it does not reflect production reality. In production, Hazelcast and presumably Redis Labs have clients connecting to it running many threads.
- COMPARING PIPELINING WITH SINGLE CALLS: Redis has pipelining where multiple commands are set and executed on the server. Hazelcast has async methods, which operate similarly. Both approaches result in higher throughput, but Redis Labs used Pipelining for Redis Labs Enterprise but did not use async for Hazelcast.
Redis Labs Refused To Grant a License Key
To reproduce the benchmark we wanted to test the proprietary Redis Labs Enterprise version, seeing as they chose to use that version against Hazelcast (as opposed to open source Redis). Not surprisingly, Redis Labs kept things in the dark.
For the flawed benchmark, Redis Labs used Redis Enterprise with a license for 48 shards. Since its downloadable trial license is limited to 4 shards, we reached out to them with the proper license request.
We contacted Keren Ouaknine, the Redis Labs performance engineer who published the benchmark, and requested both the configuration source and a trial license of Redis Enterprise to let us reproduce the test. Neither request was granted. We then asked the same from Yiftach Shoolman, CTO of Redis Labs. No reply was received.
Redis Labs Versus Redis Open Source: No Faster
Stuck with only the 4-shard trial license, we decided to examine the performance of Redis Open Source vs. Redis Labs Enterprise running with 4 shards.
We benchmarked Redis Labs Enterprise 5.2.0 and Redis Open Source 4.0.11 and found no performance difference.
Re-running Redis Labs’ Benchmark
We re-ran their benchmark, after correcting for its “errors” and have published the following:
The things we corrected were:
- We used Java clients for both. The original benchmark used C++ with Redis. We added Redis with the Lettuce client to RadarGun. Java is by far the most popular client for Hazelcast.
- We used the same benchmarking tool with the same test configuration for each. The original benchmark uses memtier_benchmark. We added Redis support to RadarGun, the tool they used to test Hazelcast.
- We used Hazelcast Enterprise HD 3.12, our latest version. The original benchmark used open source Hazelcast 3.9 with a 40GB heap which caused serious garbage collection problems.
- We used the same payload size distribution for each. The original benchmark used fixed 10KB values with Hazelcast due to the limitations of RadarGun and 5KB average payload sizes for Redis; thus we added variable payload size support to RadarGun.
- We used pipelining for both. The original benchmark used pipelining for Redis but not Hazelcast. In IMDG 3.12, Hazelcast now supports pipelining. We added it to RadarGun.
- We used async backup replication for both. The original benchmark used async for Redis and sync for Hazelcast.
- We used Redis Open Source 5.0.3 because we could not get a license for Redis Labs Enterprise. We tested both and saw no performance difference at the 4 shard level, so consider Redis Open Source to be a good proxy.
Again, note that this benchmark is at very low thread count, which is not typical of operational deployments. Regardless, with the above corrections we found that, in our benchmark, we were slightly faster than Redis Labs Enterprise.
Put differently, Redis Labs carefully manipulated this benchmark to show off the benefits of pipelining. We agree pipelining is good, and when the benchmark configures it in both products the results are clear.
There are lots of ways of doing benchmarks. Ultimately, we recommend users take their workload and benchmark against it to honestly figure out what solution works.
However, since this topic is now open, there are two very important additional areas that come up a lot around performance:
- How does the system perform at scale?
- IMDGs all have near caches. NoSQL, including Redis, does not. How does that affect performance?
Hazelcast Outperforms Redis at Scale
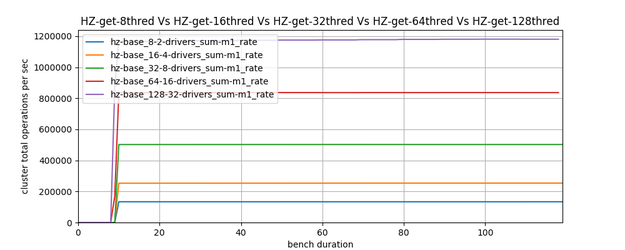
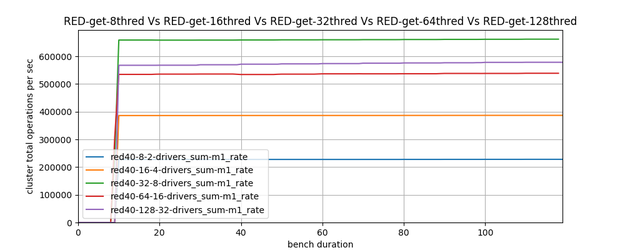
A simple out-of-the-box connection and perform “n” operations in a loop, also known as a single threaded test, shows that Redis is faster (see blue lines in the two charts below). However, if you scale those threads up, continually faster and extends its lead over Redis. At 128 threads Hazelcast has almost double the throughput of Redis (purple lines below).
Hazelcast Scaling Behavior
Redis Scaling Behavior
Plotted differently, the view is very clear: Hazelcast demonstrates near-linear scaling while Redis hits its limit at only 32 threads. In our experience with the world’s largest customers, Redis’ thread limitation is extremely problematic and either fails to meet the proof-of-concept requirements or fails to accommodate load growth over time.
Relationship of Scale to Threads
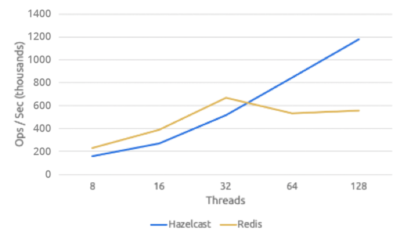 Hazelcast scalability is easy to explain: It’s rooted in the fact that Hazelcast is multi-threaded in the client and server, utilizing an approach known as Sequenced Event Driven Architecture (SEDA). This allows high-scale and efficiency with large numbers of threads. On the other hand, Redis clients, including Redis open source and Redis Labs Enterprise, are single-threaded and use blocking IO. This is a very simple approach that is fast for a single thread, but not for multi-threaded applications. Dealing with large numbers of threads is found in production environments.
Hazelcast scalability is easy to explain: It’s rooted in the fact that Hazelcast is multi-threaded in the client and server, utilizing an approach known as Sequenced Event Driven Architecture (SEDA). This allows high-scale and efficiency with large numbers of threads. On the other hand, Redis clients, including Redis open source and Redis Labs Enterprise, are single-threaded and use blocking IO. This is a very simple approach that is fast for a single thread, but not for multi-threaded applications. Dealing with large numbers of threads is found in production environments.
As an aside, Redis Labs claims that Redis Labs Enterprise is multi-threaded. In computer science terms this is not true; they have a per-machine load balancer per server which farms requests out to Redis processes on that server. Each Redis Labs Enterprise process is single-threaded, just like Redis open source. Compared to Hazelcast multi-threading, this again explains the scalability difference.
Hazelcast has Near Cache: Redis Doesn’t
A near cache is an LRU cache that sits in the client, with an eventually consistent data integrity guarantee. These are great for read-heavy caching workloads. All in-memory data grids have this feature. NoSQL databases do not.
To implement this, you need to have a sophisticated client. Hazelcast’s Java client is multi-threaded and has a sophisticated and highly performant near cache. It can store data off-heap and it can reload the last keys it held on restart.
With near cache, Hazelcast data access speeds are in high nanoseconds.
How much benefit you get from a near cache depends on the workload. Many are Pareto distributions so that a near cache of 20% can speed up access times by 80%.
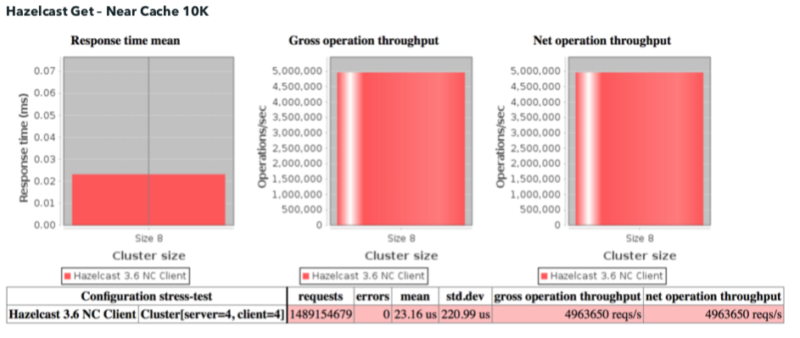
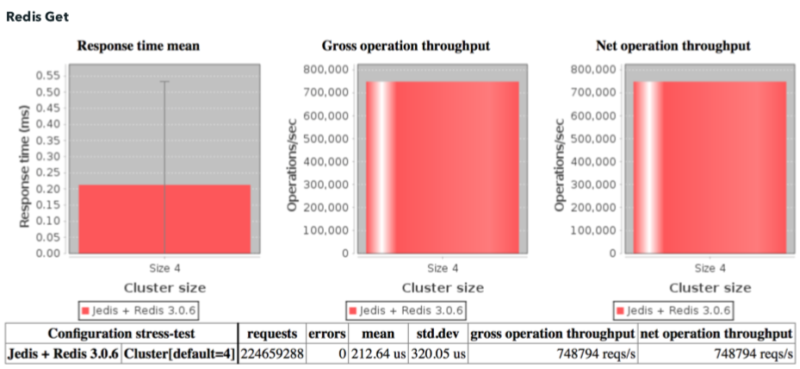
In our first benchmark against Redis several years ago, we demonstrated the effect of adding a near cache. Hazelcast performed 5 million get requests per second versus Redis at 750,000.
Conclusion
Hazelcast is by far the fastest in-memory solution in the market, particularly when requirements get complicated. This capability is the result of a sustained, multi-year effort, working with some of the world’s most demanding customers. It’s vital that businesses make decisions based on accurate and transparent information, which is why we took Redis Lab’s benchmark, fixed its inherent flaws and proved we were as fast in low thread counts. We then proceeded to show how we perform far better at scale, and the effect near cache can have on performance.
To ensure customers and users have the most accurate information, we do our best to publish our test configurations and code used in GitHub. This is so that customers and users can take these tools to reproduce the results and adapt them to their scenarios.
It is difficult to conclude anything other than Redis Labs deliberately created a misleading and unrepresentative benchmark, thinking this would satisfy its enterprise customers and prospects. Redis Labs continually peddle a myth in the marketplace that they are the fastest in-memory store; this blog proves unambiguously that is not true.
Redis Labs markets itself as a better Redis open source. From a performance perspective, we find they are basically equal. Anyone is free to replicate that test; the details are in the body of the benchmark.
We invite Redis Labs to enter into a dialogue with Hazelcast on a fair benchmark, including giving Hazelcast a license key for 48 shards, as previously requested.