
By Dale Kim
Sr. Director, Technical Solutions
Dale Kim is the senior director of technical solutions at Hazelcast, and is responsible for product and go-to-market strategy for the unified real-time data platform and the Viridian cloud managed services. His background includes technical and management roles at IT companies in areas such as relational databases, search, content management, NoSQL, Hadoop/Spark, and big data analytics. Dale holds an MBA from Santa Clara, and a BA in computer science from Berkeley.
View all blogs by the authorNov 30, 2022
Differences Between Hazelcast and Your Database
Over the years, Hazelcast has made some significant changes to its technology, evolving from its in-memory roots to a broader real-time data processing platform that now plays a bigger role in today’s IT infrastructures. Due to added capabilities in the past several versions such as tiered storage and SQL, Hazelcast is looking more like a database management system. But don’t view it as just another database, because like many special-purpose databases today, there is significant value in using a database that was architected for your specific use cases.
We’ve all learned over the years that there is no such thing as a general-purpose database. You might have tried to use some databases in a general-purpose capacity, and depending on the workload, it might have been a short-lived effort. For example, you wouldn’t use your relational database for storing event data, or your data warehouse for OLTP workloads, as you want to use the right database capabilities to solve the technical challenges you face.
An Admittedly Oversimplified View of Databases
Your database is particularly good for two data-related functions – querying and storage. Put more simply, your database is great at reading and writing data. You write applications on your database so that you don’t have to worry about the intricacies of optimizing I/O workloads on your computer, especially when non-functional requirements like performance, scale, consistency, reliability, and security are critical.
If you tell your database to save data, it figures out the best way to write the data to storage media so that you can later query it very quickly. And if you submit a query to your database, it gives you the answer without you knowing how it found the answer. This is the “declarative” aspect of SQL, where you simply tell the database what to do without describing how to do it. And that, is your database in a nutshell.
 Databases are reading and writing machines.
Databases are reading and writing machines.
You might assert that databases are good for transforming data, and I would only partially agree considering that data transformations, including those that are done with SQL, are typically a “business logic” effort. In other words, it’s a human engineer who is good with transforming data, not the database itself. The database is merely a vehicle for transforming data, and the real workload that your database handles is the reading and writing.
You might also assert that databases (specifically RDBMSs) are powerful because of features like triggers and stored procedures. But again, these are really just transformations per above, so they’re about reading and writing data. You don’t actually build applications with these features. You use these features to make sure your data is stored in the way you want, thus preparing them for use by your applications.
Of course, I’m not saying that your databases are very limited. The complex work that runs behind the scenes in your database is extraordinary. I’m just saying that there are other capabilities you have to consider when trying to build an innovative infrastructure that drives the competitive advantage that your business seeks.
The Differences Enable New Types of Applications You Can Build
The two main components in the Hazelcast Platform that make it different from your databases are the stream processing engine and the distributed processing core. While these two components are related, they offer distinct advantages in the Hazelcast Platform.
The stream processing engine is useful for performing work on incoming streams of data, especially those that are stored in message buses like Apache Kafka and Apache Pulsar. This engine was built to run business-critical, production environments that require high levels of reliability (yes, we have features to support exactly-once processing) and extremely low latency, even at scale. Our documented benchmark shows that we can analyze one billion events per second with millisecond latency using a publicly available benchmark suite (NEXMark, created at Portland State University). This shows that we put a lot of effort into the efficiency and linear scalability of our engine to handle even the most demanding requirements.
The distributed processing core in Hazelcast makes it easy for you to write applications that take advantage of the collective CPU power of the hardware servers in your Hazelcast cluster. Other database clusters are dedicated to serving up the data, and applications are generally run on other hardware servers. With Hazelcast, your application code is submitted as a job to run near the data (“data locality”) while also automatically handling the parallelizable aspects of your applications to get the most performance out of your code. This greatly simplifies the effort in writing high-performance, distributed applications since you don’t have to worry about coordinating processes across servers. Hazelcast handles that complexity for you.
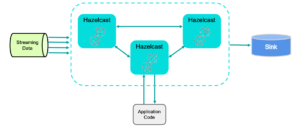
Hazelcast stream processing in a distributed architecture.
Where do the Hazelcast database-like capabilities fit in, you ask? In any real-time processing environment, you need to have large volumes of data available for data enrichment and other quick lookups, to create the proper context for your data streams. By embedding database functionality into the Hazelcast Platform, you remove the complexity of integrating separate, complex technology clusters. You get distributed processing and data storage in one cluster, with no need to bolt separate pieces together. Hazelcast lets you store growing volumes of historical data while also allowing you to query it, all within the framework of a real-time system.
Conclusion
So now you can conclude that you should not view the Hazelcast Platform as merely a new type of database. Instead, you should explore how you can take advantage of the data streams you are storing in Kafka/Pulsar (or in any of the many messaging buses available today) and leverage Hazelcast to build real-time applications that take action on data immediately. Contact us for a quick chat to see how we might be able to help.