
Principal Architect
With over 30 years of industry experience, Neil has designed, developed, debugged, and supported software systems for numerous customers large and small. Initially, a C and assembler programmer, most of the last 20 years have been Java-based, with a focus on distributed systems, data grids, and stream processing. Neil is an occasional committer to the Hazelcast code base, with special interest on GoLang.
View all blogs by the authorAug 18, 2022
Managing Applications with Multiple Data Centers
Many Hazelcast customers have copies of their data in multiple data centers. This strategy is commonly used for business continuity should the data center suffer an outage. However, there are also geographic reasons should the business have geo-specific data needs (e.g., for users) in different continents and to ensure consistent performance by storing the data as close to the customer as possible.
This blog post will look at how this is managed for applications working with the data.
Background
The crucial part of this is that data centers must be far apart. Regarding geographic reasons, this is pretty obvious, but less so for business continuity. Indeed, there would be several advantages to having them close together — for example, one team could look after both for mechanical tasks like plugging in new hardware. Ultimately, business continuity will dictate, now or in the future, that adjacent data centers are exposed to catastrophic events such as floods.
Although the exact distance is unspecified, in the likes of ISO 27001, a separation above 100 miles / 160 kilometers is a standard guideline.
Why not span data centers?
Clustered applications, such as Hazelcast, need fast communications to operate. Under a millisecond from point to point, constantly. This is unlikely to be achievable over the longer distances mandated above. With two such data centers, there need to be two Hazelcast clusters (two copies of the data) rather than one large Hazelcast cluster spanning the two data centers.
Clients not embedded
The most helpful topology here is the client-server model. Applications are clients of the Hazelcast cluster. They connect to a cluster to load and save data in the same style as connecting to a database. Should that first cluster go offline, it can connect to a different cluster. Users of that application, whether people or other applications are unaware of the change in the data source.
The alternative topology is server only. Here, applications run in the same process as Hazelcast. So if the process goes offline, the application goes offline as well as Hazelcast. Users of that application, people, or other applications are impacted and need to be diverted.
These topologies may be mixed. Streaming analytics run in Hazelcast servers, embedded is appropriate for purely event-driven workload.
Red/black and blue/green
Red/black and blue/green color pairings are frequently used to describe cutover models.
In red/black cutover is total. All workload is sent to one cluster, with the other cluster sitting in reserve. Then all workload is diverted to the reserved cluster. Typically this would be for DR.
In blue/green, the cutover is phased. Again, all workload is sent initially to one cluster. Then, some workload is diverted to the second cluster, but some remains on the first cluster. Typically this is done to validate the new cluster, for example, after a code release, before committing all workload to it.
How
Red/black is handled by failover configuration. Blue/green also need access control.
Automatic failover for Disaster Recovery
For all cutover models, clients are configured with a list of Hazelcast clusters to use.
On start-up, a client will connect to the first cluster in the list.
If that cluster goes offline (red/black), the client will automatically reconnect to the next cluster in the list.
Equally, if the cluster rejects the client (blue/green), the client again will automatically connect to the next cluster in the list.
Diverting clients
Blue/green access control forces selected clients to be disconnected from a cluster.
The Management Center or REST API allows you to specify access control lists for each cluster.
Clients can be given a name, one or more labels, and be identified by their IP address. These can be used as a selector to shunt a client from a cluster.
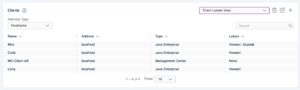
Here we might use a specific label “Szyslak” to select a client to move.
Summary
It would be wise to assume your data center or your cloud provider’s data center may be impacted by a catastrophic event.
If you configure your applications with the locations of two clusters, they will use the first but divert automatically to the second when disaster strikes.
Or you can instruct some or all applications to reconnect from the first to the second cluster if you wish it to happen on demand.