
Vladimir is a product manager with an engineering background and deep expertise in stream processing and real-time data pipelines. Ten years of building internal software platforms and development infrastructure have made him passionate about new technologies and finding ways to simplify data processing. Vladimir co-authored two white papers on the topic: Understanding Stream Processing: Fast Processing of Infinite and Big Data, and A Reference Guide to Stream Processing. His tutorial video on stream processing and real-time data pipelines discusses the building blocks of a stream processing pipeline and demonstrates how developers can write a full-blown streaming pipeline in less than a hundred lines of Java code for a variety of applications. Vladimir is also a lecturer with the Czechitas Foundation, whose mission is to inspire women and girls to explore the world of information technology. Czechitas Foundation teaches coding in various programming languages, software testing, and data analysis.
View all blogs by the authorMay 18, 2018
Don’t over-centralize your Kafka infrastructure
This week, ThoughtWorks released its 18th edition of Technology Radar. As a product manager in a company which develops infrastructure software, I appreciate these overviews as they provide both technical and high-level insight.
The current edition discusses Recreating ESB antipatterns with Kafka, something I have experienced personally.
Going back in time to the early 2000s, Enterprise Service Bus (ESB) promised to reduce the complexity of enterprise systems by introducing a central service bus – a magical pipe which mediated communication, so that system components could talk to the ESB instead of talking directly to each other. It also provided centralized governance, routing, adapters, and data normalization for the seamless orchestration of heterogeneous services into business solutions.
It was all too good to be true…
It turned out that this design led to a centralization of services that should reside within respective applications. As more logic and intelligence was moved into shared infrastructure (ESB in this case), the greater the dependency on the ESB team which resulted in ESB slowing down the speed of software development. Moreover, ESB’s often became monoliths within company architecture.
What lessons did we learn? Software services should only be shared if they correspond to a shared business or organizational service (such as billing or an organization-wide data feed). Otherwise, they tend to introduce superfluous dependencies.
This is exactly what ThoughtWorks points out in its Technology Radar:
… we’re seeing some organizations recreating ESB antipatterns with Kafka by centralizing the Kafka ecosystem components — such as connectors and stream processors — instead of allowing these components to live with product or service teams.
No matter whether you use ESB or Apache Kafka, it seems that with enterprise middleware offering greater functionality, it’s often too tempting not to use the centrally provided and managed feature, instead of an application-specific tool. Whilst centralized management can be desirable for large organizations, it all to often becomes a massive burden for development teams.
Hazelcast is led by ex-ThoughtWorker and in-memory expert Greg Luck, so when we designed Hazelcast Jet all of the above historical mistakes were taken into consideration.
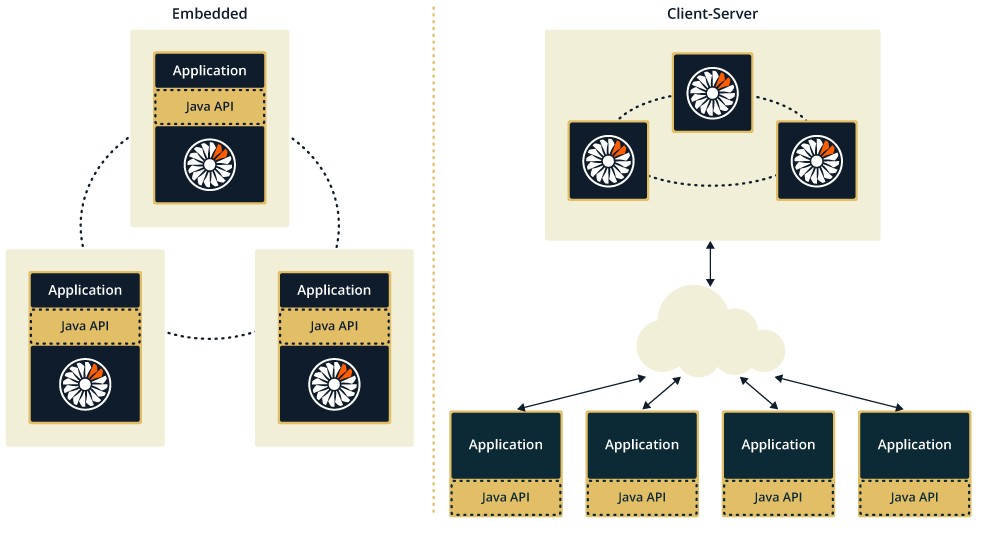
Hazelcast Jet is lightweight and embeddable. It’s a library, so you can build your app around Jet instead of deploying it to an “application server”. With embedded deployment, the data processing remains completely within the application so the product or service team has full control over it. Among others, Jet contains a Kafka connector so data from Kafka topics can be processed in Jet without the need to touch the shared infrastructure (such as Kafka Connect).
Crucially, you can still switch to a traditional server deployment if your product evolves and becomes more suited to a centralized infrastructure model.
Conclusion: Apache Kafka is powerful because it is simple. Raw data is provided to consumers, enabling consumers to manage it. Let’s keep it so and focus on consumer tooling instead of over-centralized middleware.