
By Rafal Leszko
Cloud Software Engineer
Rafał is a passionate software engineer, trainer, conference speaker, and author of the book, Continuous Delivery with Docker and Jenkins. He specializes in Java development, cloud environments, and continuous delivery. Prior to joining Hazelcast, Rafał worked with a variety of companies and scientific organizations, including Google, CERN, and AGH University of Science and Technology.
View all blogs by the authorNov 23, 2020
Build Your Kubernetes Operator with the Right Tool
You want to build a Kubernetes Operator for your software. Which tool to choose from? Operator SDK with Helm, Ansible, or Go? Or maybe start from scratch with Python, Java, or any other programming language? In this blog post, I discuss different approaches to writing Kubernetes Operators and list each solution’s pros and cons. All that to help you decide which tool is the right one for you!

You can find the source code for this blog post here.
Introduction
Kubernetes Operator is an application that watches a custom Kubernetes resource and performs some operations upon its changes.
This definition is very generic because the operators themselves can do a great variety of things. To make it more digestible, let’s focus on one example that we will use throughout this blog post. This example will be a Hazelcast Operator used to create and scale a Hazelcast cluster. Let’s imagine that a user wants to manage the Hazelcast cluster via a custom Kubernetes resource hazelcast.yaml.
apiVersion: hazelcast.my.domain/v1 kind: Hazelcast metadata: name: hazelcast-sample spec: size: 1
Upon applying this declarative configuration, a user wants to see a Hazelcast cluster with one Hazelcast member created.
$ kubectl apply -f hazelcast.yaml
Then, a user wants to be able to modify this resource configuration (i.e., change its size to 3), apply it again, and the Hazelcast cluster should resize automatically.
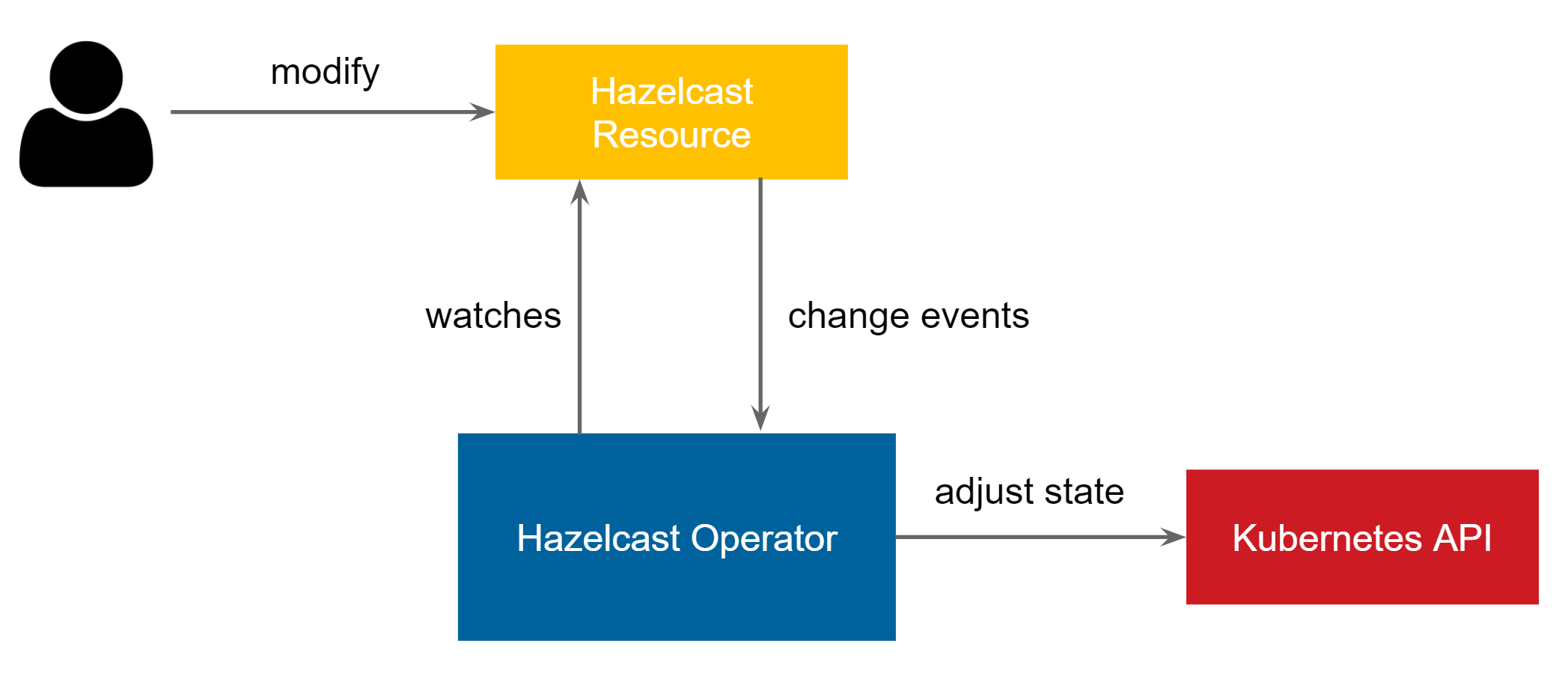
Hazelcast Operator is the application that watches the Hazelcast resource and interacts with Kubernetes API to create (or update) deployment with the given number of Hazelcast pod replicas.
This example is pretty simple, but in real life, a change in hazelcast.yaml could result in more complex operations. For example, cleaning data in the Hazelcast cluster, upgrading the Hazelcast version, sending metrics/logs to an external system, setting up WAN geo-replication, or creating some additional Kubernetes resources. There is no limit here; the point is that an operator observes your resource and performs any operation you want.
Operator Similarities
Since an operator is simply an application, technically, you can write it in any programming language or framework. What’s more, Kubernetes exposes a REST API, so you can really use any language to watch for Kubernetes events and to interact with the Kubernetes cluster. Nevertheless, no matter what implementation method you choose, operators have some similarities in how you build, install, and use them.
To create, install, and use an operator, you always have to:
- Implement the operator logic (in your preferred language/framework)
- Dockerize your operator and push it to the Docker registry
$ docker build -t <user>/hazelcast-operator . && docker push <user>/hazelcast-operator
- Create CRD (Custom Resource Definition), which defines your custom resource
$ kubectl apply -f hazelast.crd.yaml
- Create RBAC (Role and Role Binding) to allow an operator to interact with Kubernetes API
$ kubectl apply -f role.yaml $ kubectl apply -f role_binding.yaml
- Deploy the operator into your Kubernetes cluster
$ kubectl apply -f operator.yaml
- Create your custom resource
$ kubectl apply -f hazelcast.yaml
Note that only the first point looks differently depending on the operator tool. All other steps are always exactly the same. That is why in the next sections we focus on implementing Hazelcast Operator using different techniques and for points 2-6, you can use the following source files: hazelcast.crd.yaml, role.yaml, role_binding.yaml, operator.yaml, hazelcast.yaml.
Tools for building Operators
Let’s start with the most popular tool for building operators, Operator SDK. It offers 3 approaches: Helm, Ansible, Go. Then, we’ll take a look into other operator frameworks, to close with the bare programming language implementation.
Operator SDK: Helm
Helm is a package manager for Kubernetes. It allows you to create a set of templated Kubernetes configurations, package them into a Helm chart, and then render using parameters defined in values.yaml. Helm is very simple to use because creating a Helm chart requires no more knowledge than defining standard Kubernetes configuration files.
In our example, to create a Helm-based Hazelcast Operator, we need first to create the Hazelcast Helm Chart.
$ helm create chart
Then, in chart/templates we can create deployment.yaml.
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "hazelcast.fullname" . }}
spec:
replicas: {{ .Values.size }}
selector:
matchLabels:
app: hazelcast
template:
metadata:
labels:
app: hazelcast
spec:
containers:
- name: hazelcast
image: "hazelcast/hazelcast:4.1"
Our only user parameter is the cluster size and we put it into chart/values.yaml.
size: 1
Hazelcast Helm Chart is ready. Now we can generate an operator from it.
$ operator-sdk init --plugins=helm $ operator-sdk create api --group=hazelcast --version=v1 --helm-chart=./chart
That’s it! The operator is ready. If you want to build, install, and use it, execute the common steps for all operators.
$ docker build -t leszko/hazelcast-operator . && docker push leszko/hazelcast-operator $ make install # create Hazelcast CRD $ make deploy IMG=leszko/hazelcast-operator # create operator RBAC and install operator deployment $ kubectl apply -f config/samples/hazelcast_v1_hazelcast.yaml # create Hazelcast resource
Note that you need to change leszko to your Docker Hub account name and make your Docker registry public.
A few comments about the “Operator SDK: Helm” approach:
- Operator implementation is declarative and therefore simple; it requires no more knowledge than the standard Kubernetes configurations
- If you already have a Helm chart for your software, then creating an operator requires no work at all
- Your operator functionality is limited to the features available in Helm
- All operator configuration files (hazelcast.crd.yaml, role.yaml, role_binding.yaml, operator.yaml hazelcast.yaml) are automatically generated, so you don’t need to maintain them separately
Operator SDK: Ansible
Ansible is a very powerful tool for IT automation. Its nature is declarative and, thanks to a number of plugins, you can write simple YAML files to perform complex DevOps tasks. Ansible has a plugin called community.kubernetes.k8s dedicated to interacting with Kubernetes API. What’s more, Operator SDK supports generating operators from Ansible roles.
To create an Ansible-based Hazelcast Operator, we need first to scaffold the Ansible operator project.
$ operator-sdk init --plugins=ansible $ operator-sdk create api --group hazelcast --version v1 --kind Hazelcast --generate-role
Then, we can add the operator logic into roles/hazelcast/tasks/main.yml.
---
- name: start hazelcast
community.kubernetes.k8s:
definition:
kind: Deployment
apiVersion: apps/v1
metadata:
name: hazelcast
namespace: '{{ ansible_operator_meta.namespace }}'
spec:
replicas: "{{size}}"
selector:
matchLabels:
app: hazelcast
template:
metadata:
labels:
app: hazelcast
spec:
containers:
- name: hazelcast
image: "hazelcast/hazelcast:4.1"
Finally, we can add operator default parameters into roles/hazelcast/defaults/main.yml.
--- size: 1
Note that all the implementation logic looks very similar to the standard Kubernetes configuration and therefore, similar to the Helm-based operator. A significant difference is, however, that now all the configuration is interpreted by the community.kubernetes.k8s plugin, only later passed to Kubernetes API, while the Helm configuration was a direct Kubernetes configuration.
Steps to install, build, and use an Ansible-based operator are the same as for the Helm-based operator.
$ docker build -t leszko/hazelcast-operator . && docker push leszko/hazelcast-operator $ make install # create Hazelcast CRD $ make deploy IMG=leszko/hazelcast-operator # create operator RBAC and install operator deployment $ kubectl apply -f config/samples/hazelcast_v1_hazelcast.yaml # create Hazelcast resource
A few comments about the “Operator SDK: Ansible” approach:
- Ansible allows implementing operator in a declarative form which is concise and human-readable
- Ansible operator is similar to the pure Kubernetes configuration but executed via the
community.kubernetes.k8splugin - Ansible is a very powerful tool and it lets you express almost any logic you may want
- Similar to Helm-based operator, all configuration files (hazelcast.crd.yaml, role.yaml, role_binding.yaml, operator.yaml hazelcast.yaml) are automatically generated, so no need for any additional maintenance
Operator SDK: Go
Go is a general-purpose programming language, so you can technically write any operator logic you could ever imagine. What’s more, the Kubernetes environment itself is written in Go, so the Kubernetes client library (interacting with Kubernetes API) is second to none. Operator SDK (with embedded Kubebuilder) supports implementing operators in Go, so you get a lot of scaffolding and code generation for free.
To create a Go-based Hazelcast Operator, we need first to execute a few commands to scaffold the project.
$ operator-sdk init --repo=github.com/leszko/hazelcast-operator $ operator-sdk create api --version v1 --group=hazelcast --kind Hazelcast --resource=true --controller=true
Then, we are ready to implement the operator logic inside the function Reconcile() of the file controllers/hazelcast_controller.go.
// +kubebuilder:rbac:groups=hazelcast.my.domain,resources=hazelcasts,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=hazelcast.my.domain,resources=hazelcasts/status,verbs=get;update;patch
// +kubebuilder:rbac:groups=apps,resources=deployments,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=core,resources=pods,verbs=get;list;watch
func (r *HazelcastReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
ctx := context.Background()
log := r.Log.WithValues("hazelcast", req.NamespacedName)
// Fetch the Hazelcast instance
hazelcast := &hazelcastv1.Hazelcast{}
err := r.Get(ctx, req.NamespacedName, hazelcast)
if err != nil {
if errors.IsNotFound(err) {
log.Info("Hazelcast resource not found. Ignoring since object must be deleted")
return ctrl.Result{}, nil
}
log.Error(err, "Failed to get Hazelcast")
return ctrl.Result{}, err
}
// Check if the deployment already exists, if not create a new one
found := &appsv1.Deployment{}
err = r.Get(ctx, types.NamespacedName{Name: hazelcast.Name, Namespace: hazelcast.Namespace}, found)
if err != nil && errors.IsNotFound(err) {
// Define a new deployment
dep := r.deploymentForHazelcast(hazelcast)
log.Info("Creating a new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name)
err = r.Create(ctx, dep)
if err != nil {
log.Error(err, "Failed to create new Deployment", "Deployment.Namespace", dep.Namespace, "Deployment.Name", dep.Name)
return ctrl.Result{}, err
}
return ctrl.Result{Requeue: true}, nil
} else if err != nil {
log.Error(err, "Failed to get Deployment")
return ctrl.Result{}, err
}
// Ensure the deployment size is the same as the spec
size := hazelcast.Spec.Size
if *found.Spec.Replicas != size {
found.Spec.Replicas = &size
err = r.Update(ctx, found)
if err != nil {
log.Error(err, "Failed to update Deployment", "Deployment.Namespace", found.Namespace, "Deployment.Name", found.Name)
return ctrl.Result{}, err
}
return ctrl.Result{Requeue: true}, nil
}
// Update the Hazelcast status with the pod names
// List the pods for this hazelcast's deployment
podList := &corev1.PodList{}
listOpts := []client.ListOption{
client.InNamespace(hazelcast.Namespace),
client.MatchingLabels(labelsForHazelcast(hazelcast.Name)),
}
if err = r.List(ctx, podList, listOpts...); err != nil {
log.Error(err, "Failed to list pods", "Hazelcast.Namespace", hazelcast.Namespace, "Hazelcast.Name", hazelcast.Name)
return ctrl.Result{}, err
}
podNames := getPodNames(podList.Items)
// Update status.Nodes if needed
if !reflect.DeepEqual(podNames, hazelcast.Status.Nodes) {
hazelcast.Status.Nodes = podNames
err := r.Status().Update(ctx, hazelcast)
if err != nil {
log.Error(err, "Failed to update Hazelcast status")
return ctrl.Result{}, err
}
}
return ctrl.Result{}, nil
}
// deploymentForHazelcast returns a hazelcast Deployment object
func (r *HazelcastReconciler) deploymentForHazelcast(m *hazelcastv1.Hazelcast) *appsv1.Deployment {
ls := labelsForHazelcast(m.Name)
replicas := m.Spec.Size
dep := &appsv1.Deployment{
ObjectMeta: metav1.ObjectMeta{
Name: m.Name,
Namespace: m.Namespace,
},
Spec: appsv1.DeploymentSpec{
Replicas: &replicas,
Selector: &metav1.LabelSelector{
MatchLabels: ls,
},
Template: corev1.PodTemplateSpec{
ObjectMeta: metav1.ObjectMeta{
Labels: ls,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{{
Image: "hazelcast/hazelcast:4.1",
Name: "hazelcast",
}},
},
},
},
}
// Set Hazelcast instance as the owner and controller
ctrl.SetControllerReference(m, dep, r.Scheme)
return dep
}
// labelsForHazelcast returns the labels for selecting the resources
// belonging to the given hazelcast CR name.
func labelsForHazelcast(name string) map[string]string {
return map[string]string{"app": "hazelcast", "hazelcast_cr": name}
}
// getPodNames returns the pod names of the array of pods passed in
func getPodNames(pods []corev1.Pod) []string {
var podNames []string
for _, pod := range pods {
podNames = append(podNames, pod.Name)
}
return podNames
}
We also need to add the size field to the Hazelcast resource structure in api/v1/hazelcast_types.go.
type HazelcastSpec struct {
Size int32 `json:"size,omitempty"`
}
You can already see that we had to write way more code and that this code is much more complex than the previous Operator SDK solutions. That’s all because we came from the declarative Kubernetes configurations to the imperative programming language. That means that now it’s not enough to change the size in the configuration, but we need to provide the code flow (with the proper error handling). That’s definitely more difficult! On the other hand, programming language gives you the flexibility to program anything you want. The declarative Kubernetes configuration no longer limits you and your operator can perform any logic you could ever imagine.
One thing to note is the list of comments above the Reconcile() function. They are used by Operator SDK to generate role.yaml for the operator.
Steps to install, build, and use a Go-based operator are the same as for any other Operator SDK operator.
$ docker build -t leszko/hazelcast-operator . && docker push leszko/hazelcast-operator $ make install # create Hazelcast CRD $ make deploy IMG=leszko/hazelcast-operator # create operator RBAC and install operator deployment $ kubectl apply -f config/samples/hazelcast_v1_hazelcast.yaml # create Hazelcast resource
A few comments about the “Operator SDK: Go” approach:
- You implement your operator in an imperative code, which requires more work and caution
- Go language is well integrated with Kubernetes
- Writing an operator in the real programming language as Go means no limits on the functionality you want to implement
- Operator SDK helps to scaffold the Go operator project as well as generating boilerplate configuration files (hazelcast.crd.yaml, role.yaml, role_binding.yaml, operator.yaml, hazelcast.yaml)
Operator Framework: KOPF
Operator SDK is the most popular tool for creating operators, but it’s not the only one. You can find some other interesting solutions for most programming languages, for example, Java Operator SDK or Kubernetes Operator Pythonic Framework (KOPF). The former one gained some traction because its implementation was started inside the Zalando company.
To start creating the KOPF-based Hazelcast Operator, we first need to manually prepare all the boilerplate files: Dockerfile and hazelcast.crd.yaml, role.yaml, role_binding.yaml, operator.yaml, and hazelcast.yaml. Then, we’re ready to write the operator logic in the operator.py file.
import kopf
import pykube
import yaml
@kopf.on.create('hazelcast.my.domain', 'v1', 'hazelcasts')
def create_fn(spec, **kwargs):
doc = create_deployment(spec)
kopf.adopt(doc)
api = pykube.HTTPClient(pykube.KubeConfig.from_env())
deployment = pykube.Deployment(api, doc)
deployment.create()
api.session.close()
return {'children': [deployment.metadata['uid']]}
@kopf.on.update('hazelcast.my.domain', 'v1', 'hazelcasts')
def update_fn(spec, **kwargs):
api = pykube.HTTPClient(pykube.KubeConfig.from_env())
deployment = pykube.Deployment.objects(api).get(name="hazelcast")
deployment.replicas = spec.get('size', 1)
deployment.update()
api.session.close()
return {'children': [deployment.metadata['uid']]}
def create_deployment(spec):
return yaml.safe_load(f"""
apiVersion: apps/v1
kind: Deployment
metadata:
name: hazelcast
spec:
replicas: {spec.get('size', 1)}
selector:
matchLabels:
app: hazelcast
template:
metadata:
labels:
app: hazelcast
spec:
containers:
- name: hazelcast
image: "hazelcast/hazelcast:4.1"
""")
Python itself is quite a concise language and, thanks to using Python decorators, the code looks short, clean, and tidy. However, similar to Go-based implementation, you need to cover each operation (create and update) separately because we write the imperative code. One difference compared to Go is that the Python Kubernetes client is not as well integrated with Kubernetes as the Go Kubernetes client. Python uses YAML Kubernetes configurations and manipulates them, while Go operates on Kubernetes structures.
Steps to install, build, and use a KOPF-based operator are similar to what we saw before.
$ docker build -t leszko/hazelcast-operator:kopf . && docker push leszko/hazelcast-operator:kopf $ kubectl apply -f hazelcast.crd.yaml # create Hazelcast CRD $ kubectl apply -f role.yaml # create operator RBAC $ kubectl apply -f role_binding.yaml # create operator RBAC $ kubectl apply -f operator.yaml # install operator $ kubectl apply -f hazelcast.yaml # create Hazelcast resource
A few comments about the “Operator Framework” approach:
- Operator Frameworks for specific languages are less developed and popular than Operator SDK
- While Operator SDK provides project scaffolding and boilerplate code generation, Operator Frameworks usually leave this work to a developer
- Kubernetes clients for Python, Java, or other languages are always slightly worse choice than the native Go Kubernetes client
- Programming in any general-purpose language like Python or Java means that there is no limit on the functionary your operator provides
Bare Programming Language: Java
Operators are nothing more than dockerized applications, so technically you can write them in any programming language. Such a solution means, however, that you’re on your own. Nothing helps you in generating all the boilerplate code or configurations. On the other hand, you can choose the language you already use for other projects in your enterprise, decreasing the learning curve. A blog post Writing a Kubernetes Operator in Java describes how to implement an operator with Java, using Quarkus to increase the performance by building Docker native images. Let’s take a similar approach and create a Java-based Hazelcast Operator.
We need first to manually prepare all the boilerplate files: hazelcast.crd.yaml, role.yaml, role_binding.yaml, operator.yaml, and hazelcast.yaml. We can then scaffold a Quarkus project using quarkus-maven-plugin or just clone the source repository for this blog post. Finally, we can implement the operator logic in a few classes.
public class ClientProvider {
@Produces
@Singleton
@Named("namespace")
private String findNamespace() throws IOException {
return new String(Files.readAllBytes(Paths.get("/var/run/secrets/kubernetes.io/serviceaccount/namespace")));
}
@Produces
@Singleton
KubernetesClient newClient(@Named("namespace") String namespace) {
return new DefaultKubernetesClient().inNamespace(namespace);
}
@Produces
@Singleton
NonNamespaceOperation<HazelcastResource, HazelcastResourceList, HazelcastResourceDoneable, Resource<HazelcastResource, HazelcastResourceDoneable>> makeCustomResourceClient(
KubernetesClient defaultClient, @Named("namespace") String namespace) {
KubernetesDeserializer.registerCustomKind("hazelcast.my.domain/v1", "Hazelcast", HazelcastResource.class);
CustomResourceDefinition crd = defaultClient
.customResourceDefinitions()
.list()
.getItems()
.stream()
.filter(d -> "hazelcasts.hazelcast.my.domain".equals(d.getMetadata().getName()))
.findAny()
.orElseThrow(
() -> new RuntimeException(
"Deployment error: Custom resource definition \"hazelcasts.hazelcast.my.domain\" not found."));
return defaultClient
.customResources(crd, HazelcastResource.class, HazelcastResourceList.class, HazelcastResourceDoneable.class)
.inNamespace(namespace);
}
}
@ApplicationScoped
public class DeploymentInstaller {
@Inject
private KubernetesClient client;
@Inject
private HazelcastResourceCache cache;
void onStartup(@Observes StartupEvent _ev) {
new Thread(this::runWatch).start();
}
private void runWatch() {
cache.listThenWatch(this::handleEvent);
}
private void handleEvent(Watcher.Action action, String uid) {
try {
HazelcastResource resource = cache.get(uid);
if (resource == null) {
return;
}
Predicate ownerRefMatches = deployments -> deployments.getMetadata().getOwnerReferences().stream()
.anyMatch(ownerReference -> ownerReference.getUid().equals(uid));
List hazelcastDeployments = client.apps().deployments().list().getItems().stream()
.filter(ownerRefMatches)
.collect(toList());
if (hazelcastDeployments.isEmpty()) {
client.apps().deployments().create(newDeployment(resource));
} else {
for (Deployment deployment : hazelcastDeployments) {
setSize(deployment, resource);
client.apps().deployments().createOrReplace(deployment);
}
}
} catch (Exception e) {
e.printStackTrace();
System.exit(-1);
}
}
private Deployment newDeployment(HazelcastResource resource) {
Deployment deployment = client.apps().deployments().load(getClass().getResourceAsStream("/deployment.yaml")).get();
setSize(deployment, resource);
deployment.getMetadata().getOwnerReferences().get(0).setUid(resource.getMetadata().getUid());
deployment.getMetadata().getOwnerReferences().get(0).setName(resource.getMetadata().getName());
return deployment;
}
private void setSize(Deployment deployment, HazelcastResource resource) {
deployment.getSpec().setReplicas(resource.getSpec().getSize());
}
}
@ApplicationScoped
public class HazelcastResourceCache {
private final Map<String, HazelcastResource> cache = new ConcurrentHashMap<>();
@Inject
private NonNamespaceOperation<HazelcastResource, HazelcastResourceList, HazelcastResourceDoneable, Resource<HazelcastResource, HazelcastResourceDoneable>> crClient;
private Executor executor = Executors.newSingleThreadExecutor();
public HazelcastResource get(String uid) {
return cache.get(uid);
}
public void listThenWatch(BiConsumer<Watcher.Action, String> callback) {
try {
// list
crClient
.list()
.getItems()
.forEach(resource -> {
cache.put(resource.getMetadata().getUid(), resource);
String uid = resource.getMetadata().getUid();
executor.execute(() -> callback.accept(Watcher.Action.ADDED, uid));
}
);
// watch
crClient.watch(new Watcher() {
@Override
public void eventReceived(Action action, HazelcastResource resource) {
try {
String uid = resource.getMetadata().getUid();
if (cache.containsKey(uid)) {
int knownResourceVersion = Integer.parseInt(cache.get(uid).getMetadata().getResourceVersion());
int receivedResourceVersion = Integer.parseInt(resource.getMetadata().getResourceVersion());
if (knownResourceVersion > receivedResourceVersion) {
return;
}
}
System.out.println("received " + action + " for resource " + resource);
if (action == Action.ADDED || action == Action.MODIFIED) {
cache.put(uid, resource);
} else if (action == Action.DELETED) {
cache.remove(uid);
} else {
System.err.println("Received unexpected " + action + " event for " + resource);
System.exit(-1);
}
executor.execute(() -> callback.accept(action, uid));
} catch (Exception e) {
e.printStackTrace();
System.exit(-1);
}
}
@Override
public void onClose(KubernetesClientException cause) {
cause.printStackTrace();
System.exit(-1);
}
});
} catch (Exception e) {
e.printStackTrace();
System.exit(-1);
}
}
}
Additionally, we need to add the Kubernetes configuration file src/main/resources/deployment.yaml, used in the Java code.
apiVersion: apps/v1
kind: Deployment
metadata:
name: hazelcast
ownerReferences:
- apiVersion: apps/v1
kind: Hazelcast
name: placeholder
uid: placeholder
spec:
replicas: 1
selector:
matchLabels:
app: hazelcast
template:
metadata:
labels:
app: hazelcast
spec:
containers:
- name: hazelcast
image: "hazelcast/hazelcast:4.1"
Apart from the code above, we need to add additional Java boilerplate classes: HazelcastResource, HazelcastResourceDoneable, HazelcastResourceList, HazelcastResourceSpec. Yes… the combination of using Java and not using any Operator Framework must result in a lot of code. A lot of code to write and a lot of code to maintain. Java is verbose; Java Kubernetes client is verbose. That’s it. For details of the code above, I recommend reading Writing a Kubernetes Operator in Java. You can also check there the tweaks you need to make to build the Docker native image.
We can build the application in two ways: Java Docker image or Docker native image. The second approach is better for the performance but requires a few tweaks in code, so for the purpose of this blog post, let’s just build a standard Docker image (and then install and use it),
$ mvn package $ docker build -f src/main/docker/Dockerfile.jvm -t leszko/hazelcast-operator:java . && docker push leszko/hazelcast-operator:java $ kubectl apply -f hazelcast.crd.yaml # create Hazelcast CRD $ kubectl apply -f role.yaml # create operator RBAC $ kubectl apply -f role_binding.yaml # create operator RBAC $ kubectl apply -f operator.yaml # install operator $ kubectl apply -f hazelcast.yaml # create Hazelcast resource
A few comments about the “Bare Programming Language” approach:
- Creating an operator from scratch means writing more code
- There is no limit on the logic you want to deliver
- Before starting to write an operator in your preferred language, you can check if it provides a good and mature Kubernetes client library
- The only good reason to write an operator from scratch is using a single programming language inside your project/organization/enterprise
Summary
You can look at the code snippets above and decide which operator implementation is the right one for you. However, that’s just a part of the story. Let me give you an example. I’m a Java developer, so for me using pure Java is the simplest approach. Still, I would never choose Java for writing an operator. Why? Most developers do not write operators in Java. So, I’d be alone in it! Alone with bugs, alone with new features, alone with my questions on StackOverflow. And programming is a collaborative work!
Then, what operator tool do others use? Let’s look at the data from OperatorHub.io.
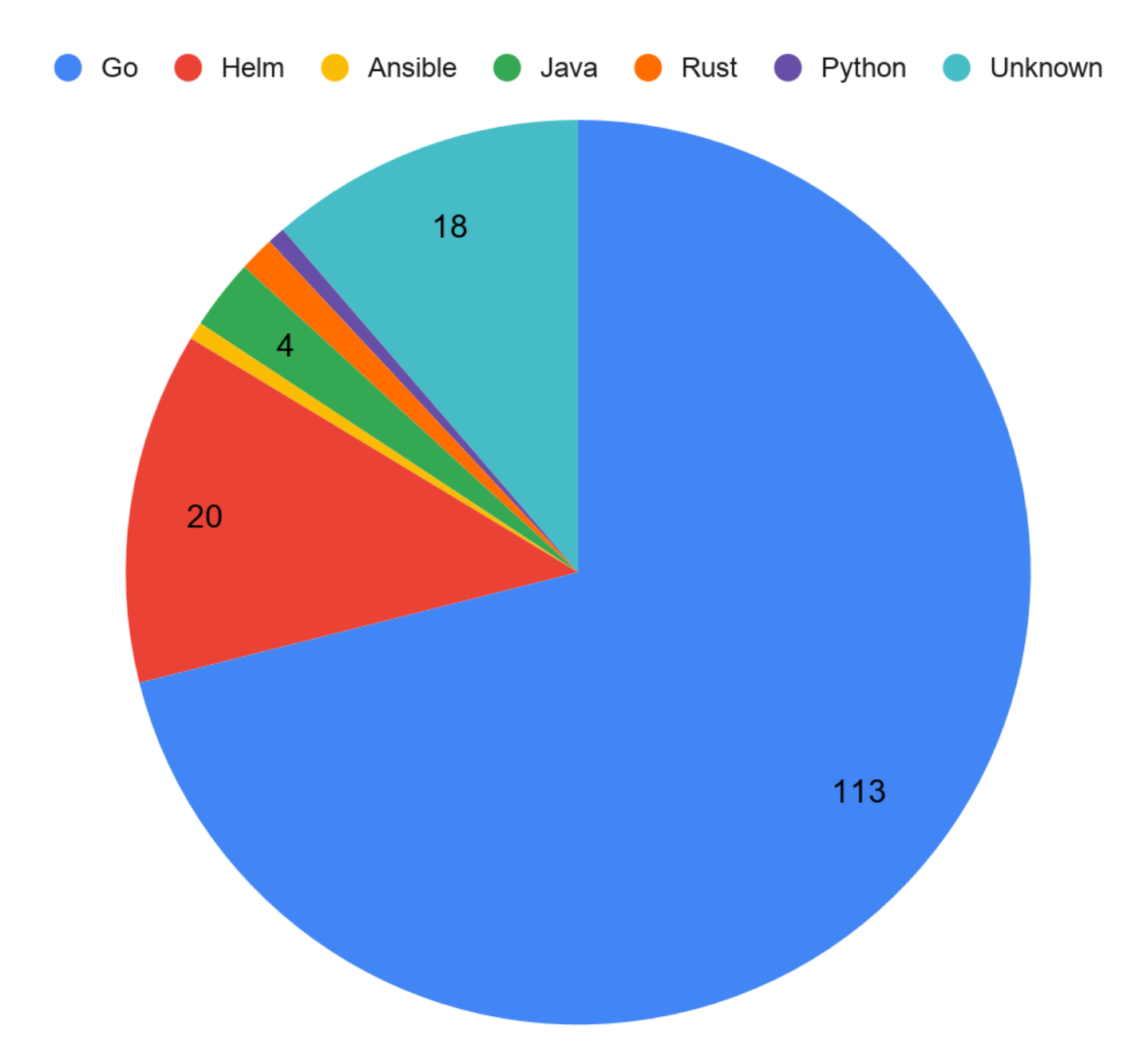
Go-based operators are by far the most popular. You may find the data slightly biased because the operators published at OperatorHub are only those operators that are built and distributed for others, so you won’t find any internal operators there. But still, if you decide to develop your operator in Go, you’re in good company!
So, which operator implementation is the right one for you? The choice is yours, but let me give you some hints.
- Hint 1: If you already have a Helm chart for your software and you don’t need any complex capability levels => Operator SDK: Helm
- Hint 2: If you want to create your operator quickly and you don’t need any complex capability levels => Operator SDK: Helm
- Hint 3: If you want complex features or/and be flexible about any future implementations => Operator SDK: Go
- Hint 4: If you want to keep a single programming language in your organization
- If a popular Operator Framework exists for your language or/and you want to contribute to it => Operator Framework
- If no popular Operator Framework exists for your programming language => Bare Programming Language
- Hint 5: If none of the above => Operator SDK: Go