
Developer Advocate, Hazelcast
Nicolas Fränkel is a Developer Advocate with 15+ years experience consulting for many different customers, in a wide range of contexts (such as telecoms, banking, insurances, large retail and public sector). Usually working on Java/Java EE and Spring technologies, but with focused interests like Rich Internet Applications, Testing, CI/CD and DevOps. Currently working for Hazelcast. Also double as a teacher in universities and higher education schools, a trainer and triples as a book author.
View all blogs by the authorMar 4, 2021
Beyond “Hello World” – Zero-Downtime Deployments with Hazelcast on Kubernetes
Today, I’d like to offer an approach that will allow most organizations to proceed with zero-downtime deployments with help from the Hazelcast platform.
Applications are not stateless!
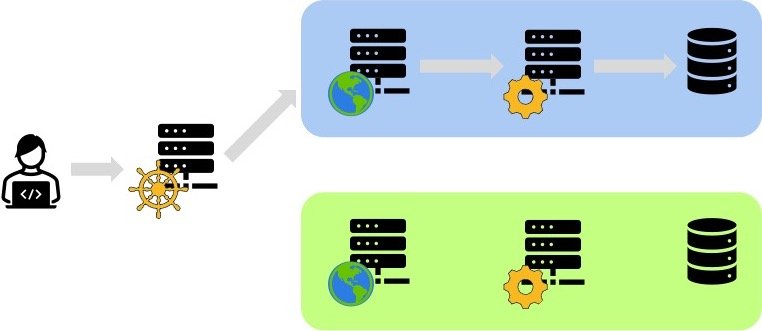
A couple of years ago, I became interested in Continuous Deployment as the natural extension of my deep interest in Continuous Integration. Among the CD patterns, Blue-Green deployment was the first. Here’s a sample architecture:
The idea is that a router component directs the requests to one environment; by convention blue. This environment contains all the necessary components for the application to achieve its task. Meanwhile, Ops can deploy a new version of the application in the green environment. When all is ready, they can switch the router to direct all the requests to the new green environment.
Unfortunately, this ideal scenario suffers from several drawbacks, all related to the state. Though we would like our applications to be stateless, most of them are not. Let’s chase the devil where it lies.
Sessions (and cookies) are ubiquitous in nearly all web applications. In general, developers use sessions when data are both is small and required frequently. When that happens, fetching data from the database is too expensive. A simple use-case of session usage is to display the logged-in user’s name on each screen in a web app.
Problems start to happen when the node which hosts the session dies. The data is lost. I believe this is a solved problem now, thanks to session replication. By the way, did you know that Hazelcast has many different session replication approaches: Jetty, Tomcat, WebFilter-based, and even Spring Sessions?
You should store data that don’t fit the session use-case in external databases. It looks like it solves the issue from a bird’s eye view, but it doesn’t. You need to migrate data in the blue environment when you switch to the green environment. In real-world applications, it’s bound to take time.
Imagine an e-commerce web application where we store users’ carts in the database. When the switch from blue to green starts, we need to move users to the latter. Their session is migrated to the green application server, which uses the green database. We somehow need to migrate the data as well. Unfortunately, we face a quandary: we cannot redirect the user before migrating the data, but we cannot migrate the data while still using the blue environment.
The obvious escape route is to:
- Direct new users to the green environment
- Wait until an existing user has stopped using the application (by checking session expiries) and then move their data
- When all user sessions on blue have expired, transfer the remaining data
This process is lengthy and error-prone. It won’t be feasible to migrate several times a day.
A tentative solution, the shared database
The most straightforward solution to cope with the above problem is not to migrate but to use a database (or cluster) shared between the two environments.
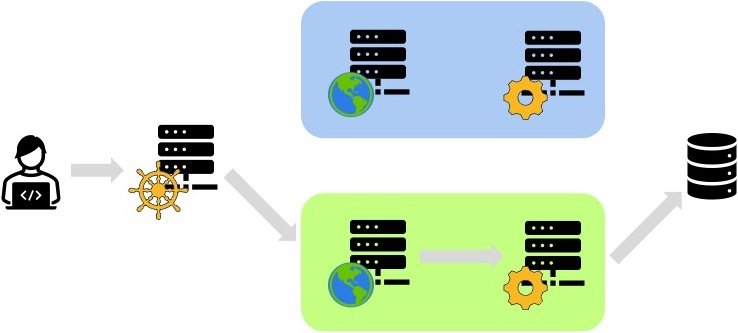
I wrote about this approach in the past. Please find here the abridged version.
The biggest downside of sharing the database is that some application deployments require a database schema change. But some changes are not backward-compatible. Hence, because we need to be able to roll back the deployment while keeping the data, we need to split a breaking change into a series of side-by-side compatible changes. This way, version x.0 of the application could still work with version x.1 of the database schema.
This holds whether the database enforces schema-on-write (as most SQL databases do) or the application needs to apply schema-on-read (à la NoSQL).
The split of changes makes the deployment process manual and fragile. Moreover, we still need to migrate data from one form to another, even in the same database. We can achieve it through different channels: the application code that touches the data, triggers, etc.
The final nail in the coffin boils down to how our process manages. It manages the “hot” ones, but what about the “cold” ones? As in the previous approach, data that isn’t touched during the migration process still needs to be migrated.
Embracing data migration
Whether we design the deployment architecture around a database in each environment or a single shared one, we still need to migrate the data anyway. Hence, it’s much better to embrace migration instead of pushing it aside and treating it as a second-class problem.
The problem behind data migration is not the migration itself but how we manage it. Batch jobs are the standard way to implement data migration. From a very general perspective, one plans a batch to run at specified intervals, read data that meets specific criteria from a source, transform the data, and finally write the transformed data into a sink. When the job has finished its task, it stops.
Batches come with several drawbacks:
- What if data has not yet arrived when the job finishes?
- How to hold the whole data to process in memory?
- What if the batch fails mid-way?
- What if the batch runs so long it oversteps its next schedule, e.g., an hourly batch that takes more than 60 minutes?
The good thing is that the batch model has been with us so long that we have devised ways to cope with those drawbacks. For example, we can handle the data in chunks, keeping a cursor to the last processed chunk to restart from this point if we need to.
The only way to cope with the “data has not yet arrived” problem is to process it at the next run, which may be in the next hour. For data migration, this is not possible. We don’t want to wait another hour to process the latecomers’ data and finish the migration. The issue stems from the bounded nature of the batch model. It starts… and it ends.
What if we started a never-ending job and it would process data as soon as it comes in?
Stream processing and Change-Data-Capture to the rescue
This never-ending approach has a name: stream processing (or data streaming). Stream processing answers all of the previous drawbacks of the batch approach through an event-driven paradigm.
- What if data has not yet arrived when the job finishes: the job never completes; it processes data when they become available
- How to hold the whole data to process in memory: data arrive in small chunks, so the memory consumption of one data item is relatively small
- What if the batch fails mid-way: most stream processing engines, such as Hazelcast Jet, are distributed
- What if the batch runs so long it oversteps its next schedule: one doesn’t schedule stream processing jobs; they can run forever until you stop them
We need a way for the database to emit such data events. Fortunately, it exists through Change-Data-Capture and one of its implementation, Debezium. In short, Debezium works by reading the append-only log file that SQL databases leverage to provide fail-over. When the primary node receives a write statement, it writes it down into this append-only log. Both the primary and all secondary nodes read that file and apply the statement. This way, they always maintain the same state, and if the primary node fails, one of the secondary nodes can take over from the same state.
Hazelcast Jet leverages Debezium as a library to read the append-only log.

To read more about the details on how Hazelcast Jet and Debezium, please refer to the documentation.
A blue-green deployment on Kubernetes in 6 steps
Now that we have all the pieces in place, we can finally start designing the solution. I’ll be using Kubernetes because it’s a pretty popular platform, but there’s nothing Kubernetes specific about the solution. It could run on any infrastructure.
Note that when one reads about Kubernetes, it’s easy to think that its rolling upgrade feature allows for seamless continuous deployment of containers. That’s correct, up to a point. While it’s a no-brainer to deploy stateless applications, it doesn’t concern itself with the state. We are the ones to take care of it.
- The starting point for our blue-green deployment is an application in a Kubernetes
Deploymentwith a replica count of 3 and aRollingUpdatestrategy. They all use the same database pod located in the existing blue environment. We configure all application pods with session replication.

- The next step is to schedule the new database pod in the now-empty green environment. It can take as long as necessary; the application pods won’t use it until later.

- This the critical step: we schedule the data migration job pod (labeled forward in the next diagram). As soon as an application pod executes a write to the blue database pod, the forward job captures it, reads its data, transforms them according to the new schema in the green database pod, and writes them there. Hence, while the blue database is the source of truth, you can consider the green one as derived data. Moreover, it’s kept in sync with the former – not in real-time, as even light doesn’t travel instantaneously, but close enough for our needs.

- Now is the time to schedule the new version of the application. We just tell Kubernetes about the new image in the
Deployment. It’s its job to achieve that via the rolling update. With session replication and both databases closely in sync, we can seamlessly move users from a v1 app pod that uses the blue database pod to a v2 app pod that uses the green database pod.

- At some point, all users will have migrated from the blue environment to the green environment. At this point, no writes happen in the blue environment. The green environment has become the active one.

- It’s time to do some cleanup. We can stop the forward job and unschedule its pod(s). Later, we can do the same with the blue database pod.

Note that for the sake of simplicity, we described only the nominal path. In real-world scenarios, you should prepare a backward job that reads from the green database and writes back to the blue one. If you need to rollback, you’ll stop the forward job, schedule the backward job, and downgrade your application pods again to move users back to the original blue environment.
Conclusion
In this post, I described the core problem of upgrading an application: state. The state is in two places, applications themselves with user sessions and databases. Session replication is a solved problem, database migration not so much.
With data streaming and Change-Data-Capture, we have a foolproof process to migrate data from databases to update an application while serving users at the same time.
Please find the associated Git repository that illustrates the post.