
By Fawaz Ghali
Director of Developer Experience
Fawaz Ghali is the Director of Developer Experience at Hazelcast with more than 22 years of experience in DevRel, cloud, enterprise software development and deployment, ML/AI and real-time intelligent applications, management and leadership. He holds a PhD in Computer Science and has worked in the private sector as well as academia and research. He has published over 45 scientific peer-reviewed papers in the fields of ML/AI, data science and cloud computing on Google Scholar. Fawaz is a renowned expert with 200+ talks and presentations at global events and conferences.
View all blogs by the authorAug 29, 2022
Real-Time Stream Processing Using the Hazelcast .NET Client, SQL and Kafka
The Hazelcast .NET client provides essential features for scaling .NET applications when speed and performance are needed. We previously discussed how to get started with the Hazelcast .NET client. This blog post will demonstrate how to process real-time streams using the Hazelcast .NET client, SQL, and Kafka. In order to explain our demo and setup, we will assume that you have already installed Hazelcast and run it locally, as well as running the Kafka server and ZooKeeper. The following diagram explains our demo setup; we have a Kafka topic called trades which contains a collection of trades that will be ingested into a Hazelcast cluster. Additionally, a companies map represents companies’ data stored in the Hazelcast cluster. We create a new map by aggregating trades and companies into ingest_trades map.
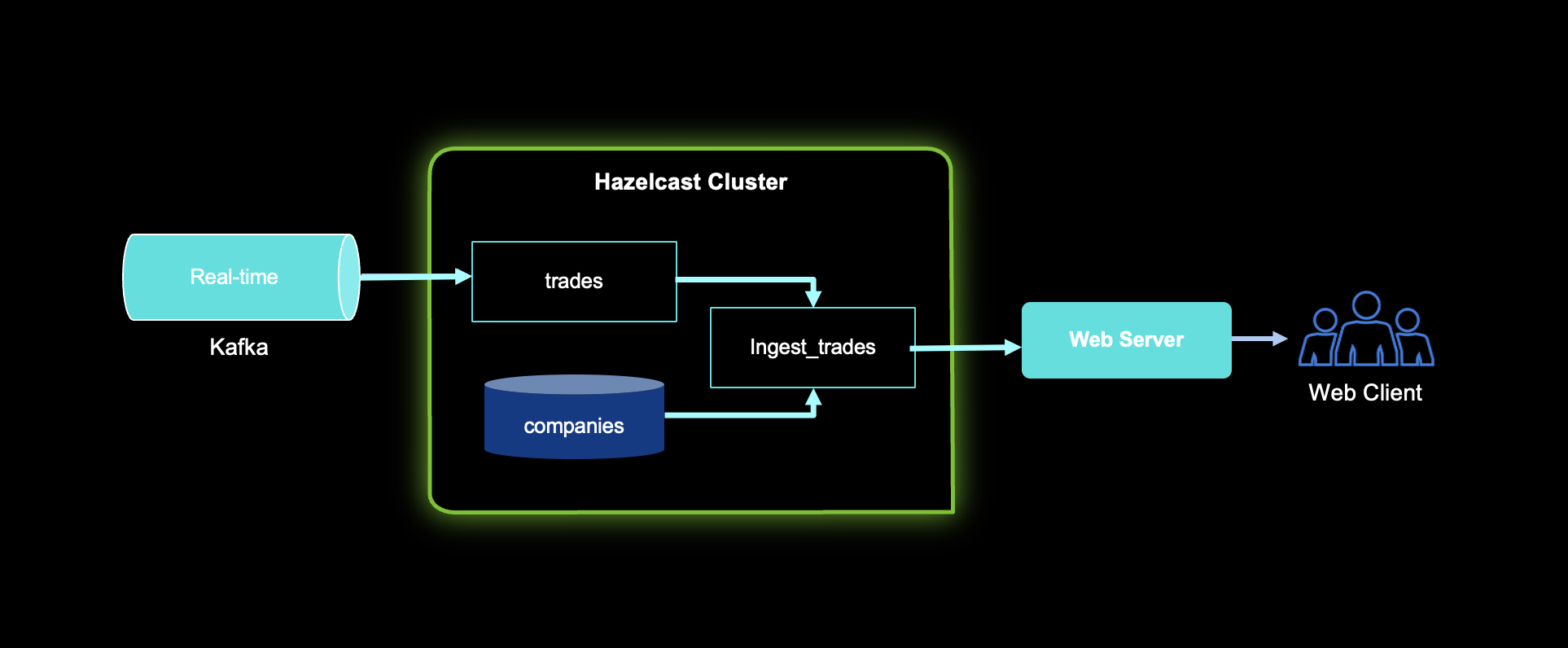
Demo Source
You can access the demo source code at: https://github.com/zpqrtbnk/hazelcast-dotnetstockdemo
Demo Setup
The application demo has the following steps:
- Define a Hazelcast map named companies and contain static data about companies (such as their ticker, name, market capitalization, etc.)
- Define a Hazelcast mapping named trades and targeting a Kafka topic
- Define a Hazelcast JET job that runs a SQL query joining trades and companies and feeding the result into a Hazelcast map named trades_map
- Queries that trades_map periodically and update a web UI via SignalR
The trades Kafka mapping is a streaming mapping, which means that a SQL query over that mapping does not complete but instead returns new rows as they come. Therefore, the JET job keeps running and constantly inserts rows into the trades_map as rows are received from Kafka. In real-life, rows would be pushed to the Kafka topic by a totally independent service. However, for the sake of the demonstration, a background task pushes rows to Kafka periodically. This is the only reason for the demo to access Kafka: a typical application would only access Hazelcast, and Hazelcast itself does all the Kafka-related work. From an application perspective, the demo is a background worker within a .NET 6 MVC application. The worker queries the trades_map periodically and pushes updates to a SignalR hub, which refreshes the UI in real-time. The only thing that is not true real-time is the trades_map query, as Hazelcast maps are batch SQL sources: a SQL query over a map returns the requested rows and completes; it does not run continuously as the query of the Kafka mapping does.
Packaging the Demo
Although the demo can run on the local host (via a simple dotnet run command), we have decided to bundle it as a Docker image and run it as a container. For that purpose, a Dockerfile file is at the demo directory’s root. The demo image has been pushed to the public Docker repository. This is all achieved through the following commands (where zpqrtbnk is the Docker user name):
docker build -t zpqrtbnk/dotnetstockdemo -f Dockerfile .
docker tag zpqrtbnk/dotnetstockdemo:latest zpqrtbnk/dotnetstockdemo:1.0.0
docker login --username=zpqrtbnk
docker push zpqrtbnk/dotnetstockdemo:latest
docker logout
Running the Demo
The demo is entirely composed of Docker containers because that is the simplest way to run Kafka and Hazelcast. The actual demo could run on a local machine but again, for the sake of simplicity, we run it in a Docker container. The containers are operated via the docker-compose tool, which can create a complete set of containers from one single YAML description file. The file is docker-compose.yml at the root of the demo directory for this demo.
Kafka Service
Kafka requires a pair of services to operate: the ZooKeeper service and the Kafka broker itself. Their configuration is entirely defined in docker-compose.yml and mainly consists in defining the networking setup. ZooKeeper runs on port 2181 within the Docker network (not exposed to the host). Kafka operates on port 29092 within the Docker network (not exposed to the host) and on port 9092 which can be exposed to the host. Note: when port 9092 is exposed to the host, the KAFKA_ADVERTISED_LISTENERS line in docker-compose.yml must be updated so that the EXTERNAL listener points to the actual IP of the host.
Hazelcast Service
Hazelcast is one service that operates on port 5701 within the Docker network (and can be exposed to the host). Its configuration is entirely defined in docker-compose.yml and consists in determining the Hazelcast cluster name for the cluster via an environment variable.
Demo Service
The demo itself is one single service. Its configuration is entirely defined in docker-compose.yml. It consists in:
- Mapping port 7001 (the demo port) from host to service
- Defining some environment variables which specify how to reach the Kafka and Hazelcast services within the Docker network
The demo service will connect to the Kafka and Hazelcast services within the Docker network and serve a web UI on port 7001.
Running the Demo
The complete demo can be started by running the following command on a Docker host within the directory containing the docker-compose.yml file.
docker-compose up -d
And then directing a browser to http://<host>:7001/ where <host> is the name of the host that is running the Docker containers.
Note that docker-compose supports various options such as stop and down to stop everything, ps to list running containers, etc. In some rare cases, the demo can hang due to timing issues when starting the containers. It is possible to fix this by restarting the demo container with docker-compose restart dotnetstockdemo. Note: this means that any user can reproduce the demo by simply fetching the docker-compose.yml file, adjusting settings in the file, and using docker-compose.
Running on AWS
The demo currently runs on AWS, using an EC2 Linux instance as a Docker host. This means that we connect to the instance via SSH, copy the docker-compose.yml file, and run the docker-compose commands there. There is a way to run docker-compose locally, target AWS ECS (Elastic Container Service) and even possibly run the contains on AWS Fargate, i.e., without any EC2 instance. However, this first requires a complex configuration on the AWS side (in terms of permissions and networking…) and we have not used it for the demo.
Next steps
If you are interested, you can change the Kafka source to any source; even if not implemented in Hazelcast, you can create your own source. This is also applicable to Hazelcast sinks as well. Furthermore, we only demonstrated combining the Kafka stream with IMap but it is possible to do complex SQL queries or create advanced data pipelines.
Summary
This demo demonstrated how you could connect your .NET application to Hazelcast using the .NET client. The application ingests trades from Kafka topic into Hazelcast and aggregates the trades into a new IMap. The aggregation results are sent back to the .NET clients and displayed in the web browser. It is possible to change your input to any of the following sources and your output to any of the following sinks. If you found this helpful post, or you have any feedback or question about the setup or demo, you can reach out to us at [email protected].