
Principal Architect
With over 30 years of industry experience, Neil has designed, developed, debugged, and supported software systems for numerous customers large and small. Initially, a C and assembler programmer, most of the last 20 years have been Java-based, with a focus on distributed systems, data grids, and stream processing. Neil is an occasional committer to the Hazelcast code base, with special interest on GoLang.
View all blogs by the authorJun 3, 2021
Intelligent WAN Synchronization
One of the features of Hazelcast Enterprise is the ability to share data between multiple Hazelcast clusters, whether geographically distant or adjacent.
In this blog, we’ll look at the practicalities of keeping the data in multiple clusters synchronized.
Business continuity wins
There are two conflicting needs here.
Data replication happens fastest the nearer the clusters are to each other. A good network helps too.
Business continuity dictates (ISO22301 etc) to keep the clusters as far apart as possible.
Business continuity wins every time here. Even if your data centers are currently close in proximity, a DR review may move one elsewhere or to the cloud.
WAN replication, store, and forward
What is needed is a mechanism that is tolerant of high network latency between the clusters, occasional loss of networking, and the clusters being temporarily offline.
Hazelcast uses a “store & forward” mechanism based around sending deltas.
For example, clusters in London and New York may wish to share data. A data change applied to the London cluster is saved to a delivery queue on the London cluster. This delivery queue sends to the New York cluster whenever connectivity is in place, and as fast as the network can transmit. Once received in New York the change is applied to New York, bringing the two clusters back into line.
If New York is offline for an hour due to maintenance, the change sits in London’s delivery queue until New York comes online again.
Should London have a surge of updates, it may take a while to deliver them all across a slow network.
Inconsistent normally
What’s important to understand is this asynchronous delivery mechanism introduces an eventual consistency model. Immediate consistency isn’t possible over large geographic distances.
If, as above, New York is offline for an hour, the clusters will differ for an hour.
When the connection is slow and London has a surge of updates, it may take a few minutes or seconds for all updates to be propagated.
If the delivery queues are empty, the clusters are consistent. If the queues are not empty, one cluster has had an update that the other cluster has yet to have.
Consistent here does not necessarily mean identical. Unlike disk replication which copies everything, Hazelcast’s WAN replication may be configured to only send a subset. Replication is in a consistent state when all data that should be replicated has been replicated.
Inconsistent abnormally
In the real world, we need to recognize and cope with the problems that can occur.
For example, the delivery queues have a configurable but unsurprisingly finite capacity.
If New York is offline for longer than their SLA, the London delivery queues may fill up. London can be configured to drop excess changes, meaning more changes are applied to London than saved to apply to New York, so New York would deviate permanently.
There are other scenarios also, you may choose to clear the delivery queue.
The crucial part here is there are scenarios where you know or suspect (either is bad) that the two clusters have got out of line and this needs to be addressed.
In such scenarios what is important is to get them back into a known state quickly.
Re-synching
Hazelcast’s WAN replication transmits deltas. If two clusters start in step, and all deltas are applied, they stay in step.
Re-synchronization is available if they have, or are suspected to have, become out of line.
This can be a simple bulk copy operation. Copy all data from London to New York, guaranteeing alignment. While it’s easy and intuitive, it may not perform well. London and New York are 3500 miles / 5500 kilometers apart. If there’s terabytes of data that might take a while to copy, and “a while” is not a popular phrase when recovering from system issues.
The alternative is to use Merkle Trees, the topic of the remainder of this blog.
Merkle Trees
This varies per application, but it’s typical that system issues result in a small percentage of data records deviating. Rather than bulk copy, it would be more efficient to identify the culprits and fix only those.
So the problem is how to (quickly) compare two datasets that are geographically separated without bringing one to another.
Example – Game of Cards
By way of an example, consider two packs of standard playing cards in two different locations.
We can quickly and easily count the cards, and also quickly and easily transmit this information. One side might report 52 cards, and if the other has 51 cards we know there is a problem.
Next, we might report 26 black cards (13 Clubs and 13 Spades). If the other side also has 26 black cards, we know the deviation is with the red cards.
Then we might report 13 Diamonds. From here we can deduce if it is Diamonds or Hearts where the problem lies, and so on.
In essence, this is how Merkle Trees work. Hazelcast internally creates a binary tree of the data space that enables deviating subsections to be identified quickly.
The idea from there is only the deviating subsection needs transmitted, the smallest possible chunk.
Intelligent WAN synchronization
This is the meaning of “Intelligent WAN synchronization” in the title. Hazelcast can deduce which subsets of data are different and only send those.
This is more intelligent and elegant than a bulk copy, but which is best depends on the run time. If they’re far out of line then the simplistic bulk copy spends less time thinking and more time doing.
Example – Game of Cards
Let’s try this with an example.
We will have two Hazelcast clusters, named “london” and “newyork“, and in them we will try to store 52 playing cards.
Data Model
The data model is this:
public class Card {
private String suit;
private String rank;
}
“suit” field holds strings such as “Hearts” and “Clubs“.
“rank” field holds strings such as “Ace“, “10” and “Jack“.
Configuration
The significant part of the configuration is this:
hazelcast:
wan-replication:
'my-wan-publisher-group':
batch-publisher:
'${remote.cluster.name}':
queue-capacity: 50
queue-full-behavior: DISCARD_AFTER_MUTATION
target-endpoints: '${remote.cluster.addresses}'
sync:
consistency-check-strategy: MERKLE_TREES
We have a queue publisher we have named “my-wan-publisher-group” that replicates changes to one other cluster.
Publishing is actually a 1:many relationship. We have “london” sending changes to “newyork” (a 1:1) but it could easily be set to send the same changes to “hongkong” also.
As you’ll see, the remote cluster name is plugged in from the environment variable, “${remote.cluster.name}“, so we use the same configuration for both london” and “newyork“, changing only their system properties.
Also note, “queue-capacity: 50“. We have set the delivery queue size to a deliberately small value.
Start London and load data
The first thing to do is start the London cluster. At the current time, New York is not running.
Now, we will inject 52 data records representing each of the 52 playing cards.
We have configured the delivery queue size for 50 and try to inject 52 data records. The configuration “queue-full-behavior: DISCARD_AFTER_MUTATION” dictates what to do in this situation. In this case the configuration is to allow London to be changed even if those changes cannot be queued for New York.
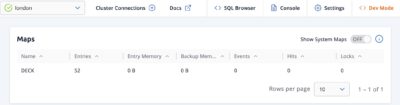
If we look in the Management Center, we will see 52 records stored in London and 50 to go to New York.
In the logs for London, we’ll see a note of the problem too, as the last 2 inserts are dropped from the delivery queue:
16:00:54.945 [hz.127.0.0.1.partition-operation.thread-9] ERROR com.hazelcast.enterprise.wan.impl.replication.WanBatchPublisher - [127.0.0.1]:6701 [london] [5.0-SNAPSHOT] Wan replication event queue is full. Dropping events. Queue size : 50
Start New York
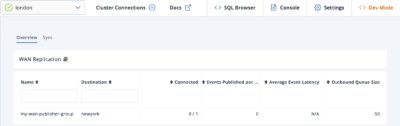
Next, we start the New York cluster.
London has the New York cluster’s IP addresses pre-configured, and will periodically try to find it. When New York comes online, London will connect and deliver the 50 data records it has.
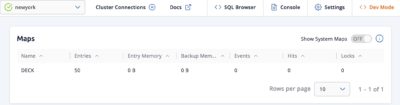
Sync
The last step to resolution is to request the synchronization.

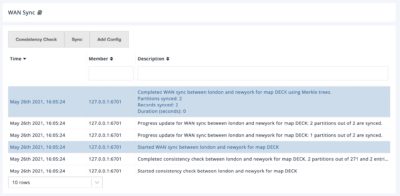
2 differences are found and resolved.
Summary
Ideally, your delivery queues should be configured with sufficient capacity to avoid dropping records. You should know the allowed outage time for data-center maintenance and the rate at which your data changes. But it’s not inconceivable that maintenance overruns the allowed outage time.
Re-synchronization is a fallback or may be the preferred mechanism. What’s important when clusters are suspected of deviation is to quickly get to a position where the deviation is known to be resolved.
Merkle trees are one way to do this if the deviation is small.
Bulk copy is equally applicable if the deviation is large.
Which will be best will depend on your application. The time to reach alignment is what matters, not the mechanism.
Do not forget idempotency. If a re-sych sends data to a cluster, listeners and observers will fire on the receiving cluster. These need to be able to detect duplicates.