
By Raj Barua
Raj is a Solution Architect based in India and helps some of the world's largest companies with their mission-critical systems. For 20+ years, he has built and operated software systems for telecom and financial sectors.
View all blogs by the authorFeb 1, 2024
Hazelcast Platform Fault Tolerant Pipelines
When building real-time streaming solutions like payment systems on the Hazelcast Platform, a major aim is preventing duplicate payments, especially during unexpected errors. While Hazelcast Platform offers both EXACTLY_ONCE and AT_LEAST_ONCE processing guarantees, understanding their practical implications is crucial for crafting truly fault-tolerant pipelines. This guide simplifies this understanding and empowers users to build robust payment systems confidently.
As part of this discussion, we would try to understand how EXACTLY_ONCE and AT_LEAST_ONCE guarantees are implemented and explicitly state what is guaranteed to be executed EXACTLY_ONCE and what is not.
1. Pipelines
A data pipeline (also called a pipeline) is a series of steps for processing data consisting of three elements:
- One or more sources: Where do you take your data from?
- Transformers: What do you do to your data?
- At least one sink: Where do you send the last processing stage results?
Pipelines allow you to process data that are stored in one location and send the result to another, such as from a data lake to an analytics database or into a payment processing system.

Pipelines are deployed as Jobs, which are then converted to DAGs and distributed among all members of the Hazelcast Platform cluster.
1.1 Fault Tolerance Against System Failures
Pipelines are fault tolerant to system failures arising out of software, hardware, or network failures. Depending upon configuration, in case of a system error like an unhandled exception in the pipeline, Hazelcast Platform may suspend or fail the job, whereas a node failure due to hardware or network issues may result in the Job being restarted on the remaining nodes. Upon recovery from a suspended or restarted job, Hazelcast Platform will resume the job from the last known successful position and ensure, if configured, that messages are sent to the Sink at least once or exactly once. Such guarantees ensure messages are processed at least once or exactly once, even after a system failure and subsequent recovery. If configured with Hazelcast Platform persistence, pipelines can resume failed jobs even after full cluster failure.
For example, if a pipeline configured with EXACTLY_ONCE processing constantly ingests a stream of payment messages from Kafka and fails after processing several messages, the pipeline will stop processing further messages. Upon restoring the pipeline, the job will start processing the messages from the last known successful position, ensuring that messages are sent exactly once to the Sinks (like a payment gateway).
While this discussion primarily focuses on system failures, Hazelcast Platform pipelines can also tolerate split-brain issues where parts of the cluster lose connection and start believing that the rest of the cluster nodes are unavailable. When configured, Hazelcast Platform ensures that a job can be restarted only in a cluster whose size is more than half of what it ever was.
1.2 Implementing Fault Tolerant Pipelines
Hazelcast Platform implements a variation of the Chandy-Lamport algorithm called Asynchronous Barrier Snapshotting (ABS).
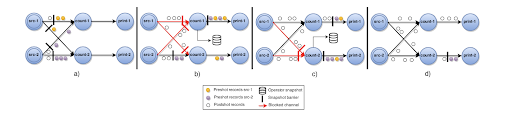
If configured with EXACTLY_ONCE, at regular intervals, the Hazelcast Platform coordinator injects a barrier (sort of a marker) message in the regular event stream in front of the sources. As the barrier reaches the sources, they take a snapshot of the state and the position of the last message read from the external source (for example, Kafka). Each source then broadcasts the barrier to all its outgoing edges. When a Transformer (intermediate) processor receives the barrier in one of its input edges, it blocks that edge until it receives a barrier from all the inputs. Transformers wait for all barriers only when EXACTLY_ONCE is configured, whereas AT_LEAST_ONCE results in weaker propagation without waiting for all barriers. When barriers have been received from all inputs, the Transformer processor takes a snapshot of its current state and broadcasts the barrier to its outgoing edges. When a barrier reaches a Sink, it behaves the same way as the Transformer processor. Some sinks do support 2-Phase Commit (2PC), allowing outputs to be committed to external sinks (like JDBC and Kafka) only when barriers have been received on all their incoming edges. For the sinks that don’t support 2PC, they must flush any state (most often, these are accumulated records that get written in batches instead of single records one by one). When all barriers have crossed all the sinks, the snapshot is said to be complete.
The snapshot is saved in a Map data structure, making use of internal/direct APIs, thereby adding another layer of fault tolerance for the job states. Configuring Persistence of the snapshot map will bring down the chances of total loss of snapshots to near zero.
Such a snapshot marks a specific point in each input stream along with the corresponding state for each processor. A streaming dataflow can be resumed from a snapshot while maintaining consistency by restoring the state of the processors and replaying the messages from the point of the snapshot.
1.3 Recovering from Failure
Upon a job failure, the user can restore the job at the last successful snapshot and resume processing. Hazelcast Platform’s recovery process will discard outputs of partially processed messages and retry them without resulting in duplicate effects (payments). After a failure, Hazelcast Platform restores the whole execution graph and restores the state of each Source and Transformer from the last successful snapshot as the initial state. The job then starts ingesting the messages from the external sources, resuming at the point of the last successful snapshot.
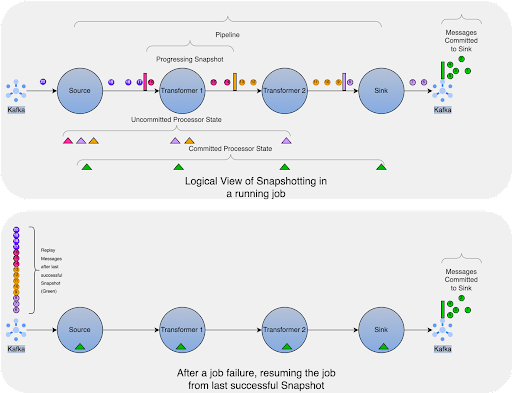
1.4 Processing Guarantees
Hazelcast Platform distributed stream processing engines support EXACTLY_ONCE, AT_LEAST_ONCE, and NONE processing guarantees. If we have replayable or acknowledge sources and sinks that support 2-Phase Commit (2PC), then EXACTLY_ONCE semantics will guarantee that a message will be delivered to the sinks in a job exactly once. At regular intervals (default 10 seconds) Hazelcast Platform stores input stream positions, stores state of stateful processes and commits the sinks. All this data is called a snapshot. In case of a failure, the state of each stateful process is restored to the last saved state, and sources are replayed from the position recorded in the snapshot.
But both these guarantees come at a cost of performance. Things to consider with EXACTLY_ONCE processing:
- A slow processor can delay the completion of a snapshot. For example, a synchronous call to an external web service that takes minutes to complete can delay the completion of a snapshot, which in turn delays the output to the sinks.
- A pause due to Garbage Collection or intermittent network issues can delay the completion of snapshots.
- As transactions at sinks are committed after a snapshot is completed, sinks see higher latency as new messages are only visible to consumers after they are committed. While the messages continue to be written to the sink during the period between snapshots, the messages are committed only at the completion of the snapshot.
- Sink’s configured transaction timeout should be higher than Hazelcast Platform’s snapshot interval. For example, Kafka’s default transaction timeout is one minute, but if the Hazelcast Platform snapshot interval is set to 2 minutes, then messages would always timeout at the sink before they are committed.
- Consumers of Sinks must read committed messages. For example, in Kafka isolation.level=read_committed.
- For JDBC sinks, using UPDATE statements can cause deadlocks between two processors as they try to complete the snapshot.
On the other hand, AT_LEAST_ONCE is a more relaxed guarantee but can result in the same message being delivered more than once to the sinks. This guarantee is more efficient to implement and along with idempotent sinks, can result in better latency than EXACTLY_ONCE. But a few considerations must be made for idempotent sinks:
- Keys must be stable so that the same key is generated for a message irrespective of how often it is processed through the pipeline.
- Even if sinks are not naturally idempotent, they can be made idempotent with additional metadata. For example, if the source is Kafka, then the message offset can be stored along with the final output to avoid duplicate processing of the final output.
- For JDBC sinks, it is recommended to use MERGE statements
It is possible for the Source, Job and Sink to have different processing guarantees but the impact of that depends upon the combination of the three.
1.4.1 Importance of Sources Providing Guarantees
Sources and Sinks play an essential role in providing these processing guarantees. In case of recovery after failure, jobs would read messages from the Sources that may have already been read. To provide either of these guarantees, sources must be replayable or acknowledgeable sources, or in the case of a custom source, must implement the necessary API.
Replayable sources can seek a particular position on the external source and read (or reread) the messages for processing. Such sources save the offsets in the snapshot so that jobs can resume from the offset after recovery.
Acknowledge Sources, like JMS, expect acknowledgments when consumers have successfully processed a message. Upon recovery, deduplication of messages may be carried out against the message IDs stored in the snapshot.
1.4.2 Importance of Sinks Providing Guarantees
Similarly, Sinks must participate in snapshotting via 2PC or must be idempotent. Custom sinks must follow specific guidelines. Idempotent Sinks are preferred as 2PC has many overheads.
1.5 Transformers must not have side effects
An important guideline is to ensure that Transformers (intermediate processors) do not have any side effects. In other words, any modification to data within or outside the Hazelcast Platform must be made via Sinks only. Since transactions are only supported in Sinks and intermediate snapshots only record the state of the processor, therefore in case of a failure, it is impossible to roll back any modifications made by Transformers (intermediate processors).
To illustrate this further, let us consider a naïve payment processing flow:
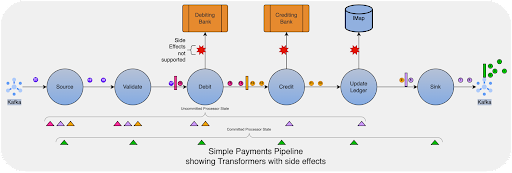
The above flow shows the processing of payment messages from a Kafka source. A single pipeline processes the complete message, for which the pipeline must call the external systems for the debits and credits. The flow also shows a modification to a Hazelcast Platform IMap. But as per the guideline above, we cannot have side effects in a Hazelcast Platform pipeline simply because a processor state held in a snapshot does not know the side effects of the step. For example, “Debiting Bank” may be a stateless API and, therefore, cannot be restored upon restoring a snapshot. Modifying an IMap can have many side effects, like listener events resulting in further actions or another pipeline feeding the map’s journal.
Creating a pipeline like the above is intuitive but can lead to duplicate payments during a failure recovery. Upon recovery, messages may be replayed that can lead to unknown errors at the “Debiting Bank” and the “Crediting Bank.” While the impact of replaying an IMap operation again can be gauged, and a compensation flow can be designed, that increases the complexity of the design.
1.6 What should be the Snapshot interval?
By default, the Hazelcast Platform takes a snapshot every 10 seconds. The best interval depends on the use case, as we must consider factors like latency requirements, network delays, frequency of input messages, transaction timeout of the external sinks, snapshot size of windowed aggregations, etc. Too large an interval will increase latency at the sink, but too small an interval will keep Hazelcast Platform busy with snapshots. An interval of less than 10 seconds and greater than 2 seconds may be a good starting point.
2. Key points
This article explains Hazelcast Platform pipelines and processing guarantees, helping developers build robust, fault-tolerant stream processing systems.
- Pipelines: Real-time stream or batch processing consisting of sources, transformers, and sinks. These can be configured for fault tolerance.
- Fault Tolerance: Hazelcast Platform pipelines can recover from system failures and resume processing from the last known successful state.
- Processing Guarantees: Three options for configuring processing guarantees are discussed:
- EXACTLY_ONCE: Ensures each message is sent to the sinks exactly once, even after system failures. Comes with performance costs.
- AT_LEAST_ONCE: More performant, but messages may be sent to sinks multiple times. Requires idempotent sinks.
- NONE: No guarantees provided.
- Implementing Fault Tolerance: Achieved through asynchronous barrier snapshots.
- Recovering from Failure: Pipelines can be restored from snapshots, and messages may be replayed.
- Sources and Sinks: Play a crucial role in processing guarantees. Sources must be replayable or acknowledgeable; Sinks must participate in snapshotting or be idempotent.
- Transformers: Must not have side effects as their state only captures internal processing, not external modifications.
