
Senior Software Engineer
Andrey's been involved in design and development of various web apps and systems for many years and always enjoyed it. Came a long road from a greenhorn junior developer in a small product team to a solution architect in a large company. Some time ago joined Hazelcast engineering team and started working on the company's products, including Node.js client library. Apart from that, Andrey is a part of the Node.js core collaborators team, constantly learns new stuff from others and shares his experience with the community.
View all blogs by the authorOct 1, 2020
Hazelcast Node.js Client 4.0 is Released

Hazelcast Node.js client 4.0 is now available! Let’s see what are the main changes in this new release.
Hazelcast Client Protocol 2.0
Node.js client now uses Hazelcast Open Binary Client Protocol 2.0, which has a number of enhancements and serialization improvements when compared with 1.x. For the end-user, it means that the client now supports IMDG 4.0+. Also, note that you cannot use a 4.0 client with IMDG 3.x members.
Ownerless Client
In Hazelcast 3.x, clients were implicitly assigned to an owner member responsible for cleaning up their resources after they leave the cluster. Ownership information had to be replicated to the whole cluster when a client joined the cluster. The “owner member” concept is now removed and Node.js client 4.0 acts as an ownerless client, which is a simpler solution for the problem allowing to remove the extra step.
Configuration Redesign and API Cleanup
Programmatic configuration in client 4.0 has become simpler and does not require boilerplate code anymore. The configuration itself is now represented with a plain JavaScript object.
Programmatic configuration (old way):
const { Client, Config } = require('hazelcast-client');
// Create a configuration object
const clientConfig = new Config.ClientConfig();
// Customize the client configuration
clientConfig.clusterName = 'cluster-name';
clientConfig.networkConfig.addresses.push('10.90.0.2:5701');
clientConfig.networkConfig.addresses.push('10.90.0.3:5701');
clientConfig.listeners.addLifecycleListener(function (state) {
console.log('Lifecycle Event >>> ' + state);
});
// Initialize the client with the given configuration
const client = await Client.newHazelcastClient(clientConfig);
Programmatic configuration (new way):
// No need to require Config anymore
const { Client } = require('hazelcast-client');
// Initialize the client with the configuration object (POJO)
const client = await Client.newHazelcastClient({
clusterName: 'cluster-name',
network: {
clusterMembers: [
'10.90.0.2:5701',
'10.90.0.3:5701'
]
},
lifecycleListeners: [
(state) => {
console.log('Lifecycle Event >>> ' + state);
}
]
});
The “shape” of the configuration is kept close to the old declarative configuration API and to the Java client’s YAML/XML configuration. So, the user experience is the same across other Hazelcast clients, but it is also native to JavaScript and Node.js runtime.
The old declarative configuration API was removed as it does not make a lot of sense now, considering these changes.
The 4.0 release also brings a number of changes aimed to make the API more idiomatic for JavaScript and familiar to Node.js developers.
CP Subsystem Support
In Hazelcast 4.0, concurrent primitives moved to CP Subsystem. CP Subsystem contains new implementations of Hazelcast’s concurrency APIs on top of the Raft consensus algorithm. As the name of the module implies, these implementations are CP with respect to the CAP principle and they live alongside the AP data structures in the same Hazelcast IMDG cluster. They maintain linearizability in all cases, including client and server failures, network partitions, and prevent split-brain situations.
Node.js client 4.0 supports all data structures available in the CP Subsystem, such as AtomicLong, AtomicReference, FencedLock, Semaphore, and CountDownLatch. Here is how a basic FencedLock usage looks like:
// Get a FencedLock called 'my-lock'
const lock = await client.getCPSubsystem().getLock('my-lock');
// Acquire the lock (returns a fencing token)
const fence = await lock.lock();
try {
// Your guarded code goes here
} finally {
// Make sure to release the lock
await lock.unlock(fence);
}
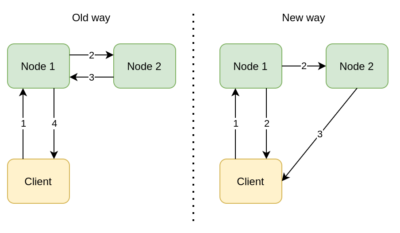
Backup Acknowledgments
In previous versions, the client was waiting for the sync backups to complete on the member. This was causing 4 network hops to complete a client operation with sync backup. Since sync backup configuration is our out-of-the-box experience, we improved its performance. Backup acknowledgments (a.k.a. boomerang backups) design decreases network hops to 3, thus improving the throughput up to 30%.
Improved Performance
We did a number of experiments and optimizations leading to improved performance for writes by 5-10%.
Other Changes
You can see the list of all changes in this version in the release notes.
What’s Next?
We believe the Node.js client has the capabilities to cover most of your use cases. Next, we are planning to work on integrations with well-known Node.js libraries! Here are the top items in our backlog:
- Hazelcast session store for popular Node.js web frameworks: A session store backed by Hazelcast IMDG.
- Hazelcast cache adapters for popular ORMs: Hazelcast integration with the Sequelize framework, a promise-based Node.js ORM for SQL databases.
- Blue/Green Deployments: Ability to divert the client automatically to another cluster on demand or when the intended cluster becomes unavailable.
- Full SQL support: Once the SQL feature in Hazelcast graduated from the beta status, we are going to add it to Node.js client.
You can always check the Hazelcast Node.js client roadmap for an up-to-date list of features in our backlog.
Hazelcast Node.js client 4.0 is available on npm. We look forward to hearing your feedback on our Slack, Stack Overflow, or Google groups. If you would like to introduce some changes or contribute, please visit our Github repository.

