
By Dale Kim
Sr. Director, Technical Solutions
Dale Kim is the senior director of technical solutions at Hazelcast, and is responsible for product and go-to-market strategy for the unified real-time data platform and the Viridian cloud managed services. His background includes technical and management roles at IT companies in areas such as relational databases, search, content management, NoSQL, Hadoop/Spark, and big data analytics. Dale holds an MBA from Santa Clara, and a BA in computer science from Berkeley.
View all blogs by the authorFeb 1, 2023
Going Beyond Real-Time Analytics
Everyone is jumping on the real-time bandwagon, especially by deploying streaming data technologies like Apache Kafka. But many of us are not taking advantage of real-time data in the fullest ways available. It’s worth assessing what you currently have in place for your real-time initiatives to explore what else can be done to create more value from your data.
Many of us use Kafka (or a similar message bus) to capture data on business events that ultimately can be stored in an analytics database. Information updates on business artifacts such as sales orders, product inventory levels, website clickstreams, etc., all can be transferred to Kafka and then transformed into a format optimized for analytics. This lets analysts quickly and easily find actionable insights from the data that they can pursue. Example actions include creating new promotions, replenishing stock, and adding webpage calls-to-action.
The typical real-time data journey is depicted in the diagram below, which represents a pattern that has long been known as the Kappa Architecture. While that is not a term that’s used as much these days as when it was first defined, it is still an important concept for designing systems that leverage real-time data (i.e., data that was just created).
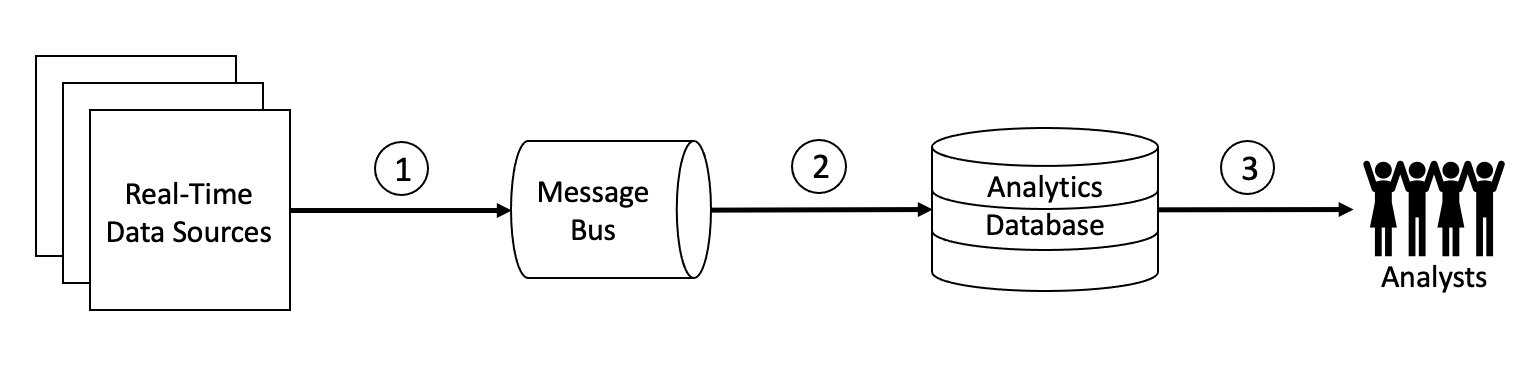
The Real-Time Analytics Data Flow – A Quick Review
There are 3 data stages between the various components in this pattern, as labeled by the circled numerals, that contribute to the “real-timeness” of the data usage. Arrow #1 represents the transmission of data from the source to the message bus (e.g., Apache Kafka). In many cases, the data in this leg of the journey is not significantly modified, so the data loading process typically occurs very quickly. This stage is a simple form of serialization, in which the data is formatted as comma-separated values (CSV) or JSON prior to insertion into the message bus, to simplify or standardize downstream processing. Sometimes the data is filtered or aggregated prior to loading it into the message bus to reduce storage requirements. But in general, keeping all data points intact is a common practice that lets subsequent data processing steps work on the raw data at a granular level.
Arrow #2 represents the most significant step in this pattern, where data must be processed to turn it into a queryable format to store in a database (or any analytical store) and thus make it more usable by human analysts. In this stage, data can be filtered, transformed, enriched, and aggregated, and then inserted into an analytics platform like a database or data warehouse. We know this step to be the extract/transform/load (ETL) step, and many “streaming ETL” technologies designed for data-in-motion can be used to perform this step. Traditional batch-oriented tools can also be used for this step, with the caveat that delays are introduced due to the time intervals of periodic ETL processing, versus continuous ETL processing. Once the queryable data is in the analytics platform, additional processing could be done, including creating indexes and materialized views to speed up queries.
One great thing about step #2 is that you aren’t limited to a single flow. In other words, you can run as many processing jobs as you want on the raw data. This is why the use of Kafka as intermediary storage is important here. Each of your processing jobs can independently read data from Kafka and format the data in its own way. This allows not only the ability to support many distinct types of analytical patterns by the analysts, but also the opportunity to easily fix any data errors caused by bugs in the processing code (also referred to as “human fault tolerance”).
Arrow #3 represents the last mile that entails quickly delivering query results to analysts. The delivery speed is mostly a function of the analytics database, so many technologies in the market today tout their speed of delivering query results.
The faster each of these steps run, the sooner you get data to the analysts, and thus the sooner you can take action. Certainly, the speed of the 3 steps combined is a limiting factor in achieving real-time action, but the main bottleneck is the speed of the human analysts. Fortunately, in most real-time analytics use cases, this is not a major problem, as the relatively slow responsiveness of human analysts is well within any service-level agreement (SLA) that the business has defined.
Adding Real Real-Time Action
At this point, you likely know where we’re going in this blog—that there is a complementary pattern that can add new uses for your real-time data that cannot wait for human responses. This pattern involves the use of stream processing engines to automate a real-time response to your real-time data stored in Kafka.
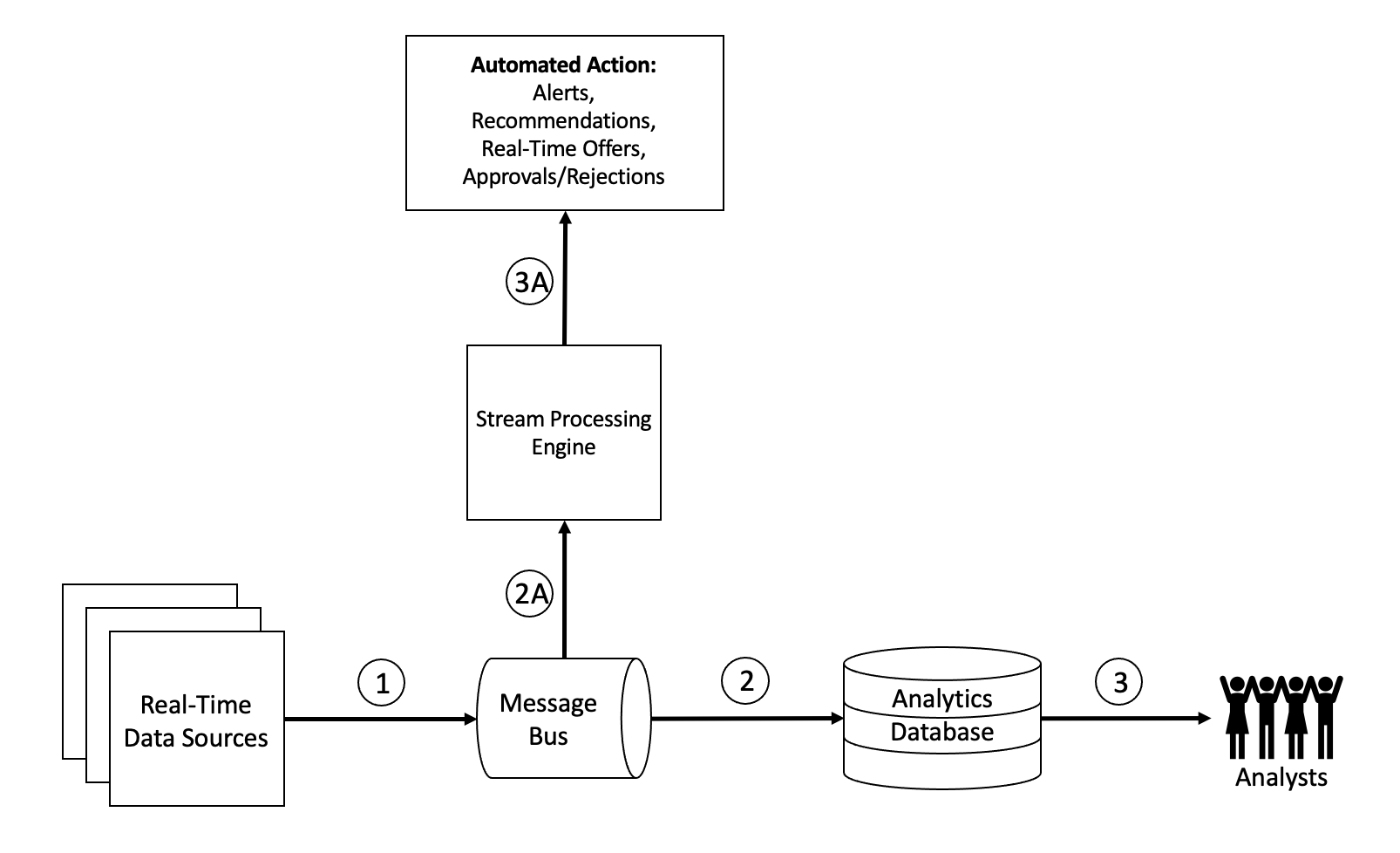
In addition to arrows #2 and #3, you have arrows #2A and #3A in which real-time applications take care of the things that should be completed quickly and automatically without waiting for human intervention. Consider real-time offers while your customers are interacting with you (via shopping, browsing, banking), versus delivering an offer later in the day after they’ve left. Or how about sending your customer an immediate SMS about a potentially fraudulent transaction on their credit card? If the transaction is legitimately initiated by the customer, you won’t inadvertently deny the card swipe, and they won’t use a different credit card, causing you to lose the transaction fee. Or what about any process that involves machine learning (e.g., predictive maintenance, real-time route optimization, logistics tracking, etc.) that needs to deliver a prediction immediately so that quick corrective action can avoid a bigger disaster?
You Already Have the Data, Now Make More Use of It
If you already have a real-time data analytics system that leverages real-time data in Kafka, think about all the other real-time use cases that can help give your business additional advantage. This is where Hazelcast can help. You don’t have to throw out what you’ve already built. You simply tap into the data streams you already have, and automate the actions to create real-time responses.
If you’d like to explore what other real-time opportunities you might have that you are not currently handling, please contact us and we’d be happy to discuss these with you.
