The Company
With $18.3 Billion in annual online sales, this global provider of personal computers and electronics has one of the most highly trafficked eCommerce websites in the world second only to Amazon.com. Burst traffic during new product introductions (NPI) is at an extreme scale, as are sales on Black Friday, Cyber Monday and over holidays. This online retailer is bigger than Staples, Walmart.com and Dell and is admired throughout the world for its high performance and top-notch brand and user experience. This unique combination of world-class brand experience and extreme burst performance scaling led this eCommerce giant to examine In-Memory Computing solutions as a way to achieve the highest possible price performance.
The Challenge
This company faced some unique challenges including heavy normal-day e-commerce traffic, but extreme spikes on key e-commerce days such as black Friday, Cyber Monday and events associated with New Product Introductions (NPI). This company is among the most valuable consumer brands in the world, so they were exceedingly sensitive to server outages and problems with the web user experience.
Proprietary solutions were available; in fact, the company was already using Oracle Coherence under an Unlimited LicenseAgreement (ULA). However, at the end of a ULA agreement term, all usage is counted towards full-priced licenses and the company needed to prepare for 70% increases in traffic year over year, which would have made continuing down that path prohibitively expensive.
The Deadly Impact of Slowness
As anyone who has ever shopped online knows, page load times can impact the overall customer experience, as well as SEO ranking driven by page load speeds when users search in a browser. According to the Aberdeen Group, a one-second delay in page-load time equals 11% fewer page views, a 16% decrease in customer satisfaction, and a 7% loss in conversions. For a company with $18 billion in online sales, the revenue impact could be significant. According to the same study, 47% of customers expect a page to load in two seconds or less. For a company whose brand is all about cutting-edge technology and user experiences, slow sites are inexcusable.
A Perfect Store of a Perfect Storm?
How did the executives at this company come to choose Hazelcast? Their Online Store was caught up in what is the envy of the industry—tremendous growth in visitors and site sales. They had extreme spikes in traffic but with requirements that no matter how big the spikes that the site response would be snappy.All of these things while at the same time lowering the cost of infrastructure.So, growth and revenue goes up—while variable cost goes down? A great challenge.
To summarize some of these requirements:
- World-class brand experience
- Extreme burst-performance requirements for NPI and holiday traffic
- Ability to elastically increase scale by up to 70% per year, yet scale down on lower traffic days
- Complex cache eviction and Time To Live (TTL)
- Ability to cache all page elements including images, product, and pricing
- Requirement for extreme stability of some elements such as pricing. Users cannot experience price changes by refreshing their browser window
- Need to manage reasonable sizes of clusters and take advantage of larger (256Gb) RAM sizes in servers
- Reduced cost of infrastructure U Reduce reliance on a home-built cache abstraction layer which was complex and hard to maintain
- Decrease Proprietary Vendor Lock-In
- Decrease the total number of caching and distributed computing solutions, and reduce the complexity of management and increase the availability and concentration of technical skills needed
These challenges led this supplier to Hazelcast, the leading open-source In-Memory technology.
Background
Reducing Total Cost of Ownership
While Hazelcast provides all of the benefits of open-source heritage, including strong price performance and better ease of ownership, less vendor lock-in and a better vendor relationship, the total cost was reduced by much more than just the cost of the license.
One of the components of Total Cost of Ownership (TCO) is the impact of good software on hardware costs. Thanks to the diminishing cost of RAM, there is a high availability of in-memory resources. By optimizing the use of distributed clustered memory and CPUs, Hazelcast squeezes tremendous performance out of the cluster. Because disk access is about a million times slower than RAM access (literally), the use of Hazelcast enables organizations to buy less hardware and use the hardware they have much more effectively.
Elasticity and the Cloud Factor
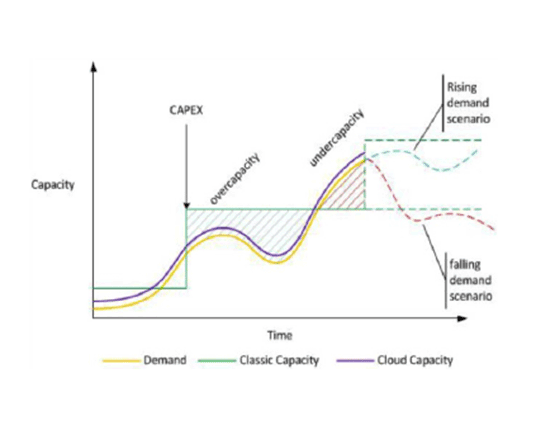
Ben Kepes from Rackspace created the image above which shows how elasticity can change the cost of infrastructure. The speed and cost of provisioning and de-provisioning capacity can directly hit the bottom line due to the impact of overcapacity and undercapacity. Hazelcast’s elasticity allows organizations to scale up and down quickly and dynamically.
Existing Approaches
This eCommerce store was a prodigious user of Oracle Coherence. In addition, multiple other niche products were used for both caching and distributed computing applications including Zookeeper, Memcached and others. As part of an Oracle Unlimited License Agreement (ULA) the team had access to unlimited nodes of Oracle Coherence.
Naturally one of the problems with the Oracle ULA is what happens after the termination period of the ULA, when all nodes are counted and new license fees are incurred based on that usage level.
There were multiple cache implementations including a homebrew cache abstraction layer. For the eCommerce store, the approach was to put a local cache on every single JVM node.
The mixture of Oracle Coherence and homebrew solutions was not aging well, and caused enough pain for the team to start evaluating other options across the gamut of NoSQL and both open source as well as proprietary solutions.
One option for the team was also Couchbase. Couchbase is a unique NoSQL solution because of the history of the solution, which originally stemmed from a combination of CouchDB with Memcached. This allows Couchbase to speak to the use case called “layer consolidation” where they can act as both the database as well as the distributed caching layer. They already were working with Couchbase and so the option to use this solution under that license was also an option. First of all, Hazelcast is a pure in-memory solution which made it a better fit overall for this use case. The support of pure Java APIs including Java.Util.Concurrent and JCache was also very significant in the decision process.
Cache Concurrency, Consistency, and Complexity
One of the problems with maintaining a local cache on every single node is the problem of cache consistency. Cache consistency for certain classes of data in eCommerce is highly sensitive. For example, shopping cart prices should be consistent. Customers don’t want to see prices changing on items they have already placed in their shopping carts upon reloading a browser window, for example.
One of the initial struggles was the fundamental architecture of local caching. With local caching, every new node that is added has to independently load from the database. This actually causes the reverse of the intent of scaling, which is that as you add nodes, you add even more pressure to the database or source of the data. This is why moving to a distributed cache was more effective for them.
In order to propagate a price change across many regions during global product introductions, they would either have to wait or do manual rebooting of instances in order for the caching to be updated. Since some of the caching behavior was automated, assuring that consistency, performance and operations remain stable became a pain point.
Another pain point was managing expectations with different application groups. The caching service was provided by an IT group that was central to the eCommerce store. Even though the eCommerce group itself was part of a business unit, there were still many different application consumers using the caching service.
The Solution
Hazelcast Phase One
The first phase of introducing Hazelcast was just to introduce the open-source product to form the basis for e-commerce caching across multiple application groups within the e-commerce store unit. Instead of using a local cache for every single JVM, Hazelcast was deployed as a distributed cache.
Optimizing Hazelcast for e-Commerce Caching
Hazelcast engineers worked to introduce some new features to support this use case such as time-outs. When you’re asking for data from one node it is possible that the data is somewhere else, so you have to fetch the data from one to another. If the remote node is unresponsive (because of Java Garbage Collection, networking or a kernel issue for example) you may have a wait for several seconds (latency). The time-out feature specially implemented here prevented any wait longer than 100 milliseconds, at which point Hazelcast would simply respond with a time-out, thus freeing the node to continue operations.
Another feature that optimizes Hazelcast for eCommerce is cache invalidation. In order to reduce the number of distributed fetch requests, they began using the distributed map “near cache” feature. The near cache holds local copies of the most frequently used data in the distributed map. In this sense, the local cache provides a nice balance between a fully replicated cache, which never has to do a distributed fetch and a fully distributed cache.
One of the topics that comes up when using the near cache feature is cache invalidation. How do all of the near caches know when the source data has been updated? If you enable invalidate on update, then that means every update will send the message to everybody saying, “if you have it, invalidate that entry because it’s been updated.” This only works if you have an application that mostly reads and not writes. If it were instead “write mostly” you would send millions of invalidations. This produces too much network traffic.
Collaborating with Hazelcast
Hazelcast is in a unique position to work closely with customers to adapt the product to their needs, especially in cases when such work would improve Hazelcast for all users. One of the major benefits of entering into a commercial relationship with Hazelcast is to gain influence over the product roadmap. Obviously getting commercial support for mission-critical systems is a must, but the collaborative relationship is an additional benefit that greatly helped this company.
Extensive Testing
Since eCommerce is the beating heart of the company’s revenue, Hazelcast was subjected to an unprecedented level of testing. Through an external specialist consulting firm, large-scale local tests, then eventually extreme-scale cloud tests in Amazon EC2 and Google Compute Cloud were running 24-7.
The tests involved overflowing and overloading every possible parameter, and stress tests that would never be encountered under normal circumstances. The goal became not for the system to never fail, but how the system could be made to fail in dozens of scenarios with grace and without impacting the mission.
Read and write tests were sent into the cluster that could range from 0 to infinity. These extraordinary tests uncovered some new scenarios that Hazelcast now handles gracefully.
By exceeding the capacity of the cluster, Hazelcast was stressed to even be able to evict unused data fast enough. And how will performance under these extreme conditions be utterly predictable? This is difficult to test because the tests can be made to represent an infinite amount of data...sooner or later you’re bound to run out of memory. Hazelcast passes all of these extreme cases and is in production on mission-critical systems.
Hazelcast Stabilizer
One utility that has made all of the difference to Hazelcast’s ability to handle extreme loads is the Stabilizer.
The Stabilizer is designed to put load on a Hazelcast environment so that we can verify its resilience to all kinds of problems including:
- Catastrophic failure of network. e.g. through IP table changes
- Partial failure of network by network congestion, dropping packets etc.
- Catastrophic failure of a JVM, e.g. by calling kill -9 or with different termination levels
- Partial failure of JVM, e.g. send a message to it that it should start claiming 90% of the available heap and see what happens. Or send a message that a trainee should spawn x threads that consume all CPU. Or send random packets with huge size, or open many connections to a Hazelcast Instance
- Catastrophic failure of the OS (e.g. calling shutdown or an EC2 API to do the hard kill)
- Internal buffer overflow by running for a long time and high pace
Hazelcast uses the Stabilizer internally to ensure that the products are all resilient to the most extreme conditions. The stabilizer is also presently available to selected customers.
Hazelcast Phase Two
Hazelcast was successfully launched inside the e-commerce store and served as the In-Memory solution for a year including multiple New Product Introductions (NPIs) and eventually grew to hundreds of nodes.
At the extremes of scale, it is often advisable to simplify clusters by reducing the number of nodes. An optimal number of nodes balances rates of node failure with the scale needs of the cluster. At extreme scales, it is often necessary to build clusters with fewer, larger machines.
One of the problems that arises when you instantiate Java Virtual Machines (JVMs) onto large machines is the Java Garbage Collection behaves in an unpredictable way. A rule of thumb is that for every GB of heap allocated to a JVM, you can expect Garbage Collection pauses of 1 second. So, for very large Heaps, you can expect the JVM to pause for multiple seconds or even minutes at a time. This is, of course, enough time for the cluster to assume the node is dead, and the cluster continues to operate and rebalance the data. But if a node returns from an extended Garbage Collection pause, this can appear to the cluster as a node rejoining after going down. Hazelcast can handle these situations, but it can affect the predictability of the cluster.
Hazelcast Enterprise
For these reasons, this customer decided to take advantage of the Off-Heap memory feature of Hazelcast Enterprise, the commercially licensed software built on top of the open-source Hazelcast core.
This enabled them to reduce cluster sizes from hundreds down to six servers with one node on each server with two copies of that in the same cluster. Each node will have 28 GB cache space (likely to grow). So, the total cache space will be 6 X 28 = 168GB.
Initially, this configuration will be rolled out to two regional data centers, but eventually this setup will be replicated to eight global data centers.
Beyond just the e-commerce site, these caches will hold all of the catalog information, product information, images and pricing information for multiple web properties. Application servers will be hitting the cache almost all the time, so the databases are not doing much.
Shift in Deployment Topology
In phase one, Hazelcast was deployed in “embedded mode”.That is to say that the Hazelcast JAR library was contained as part of the web application running on the application server.
With the shift to Hazelcast Enterprise, it was determined that a more ideal topology for a “Cache as a Service” would be to have a dedicated cluster of machines for Hazelcast only, and all service consuming applications would be running a Hazelcast client.
This topology is more appropriate for Enterprise Shared Data Services across groups, as you may not want to force all applications to embed Hazelcast JAR library, and it enables the data partitioning to be better controlled. It does not scale linearly with the addition of adding servers in the application tier, but it provides more predictability and manageability to the cluster.
Cache Abstraction: JCache
In the original implementation of the central caching service, there were multiple different implementations. This increased the cost and complexity of IT operations and made for a fragmented set of skillsets.
Both because of these multiple implementations and because they wanted to insulate themselves from vendor lock-in, they built their own Cache Abstraction layer. This allowed multiple caching systems to appear as one. This solved the problem of vendor lock-in but increased the complexity of the solution by creating a new layer of proprietary code to maintain as well as a new nonstandard cache API.
This led the team to focus on the JCache implementation in Hazelcast. JCache is a Java standard for caching, which breaks vendor lock-in but also drives a common skill set across all Java developers. This makes getting developers who know how to use the system much easier.
This new architecture is the new version of the online store. Because this interface that they are using is the standardized JCache it means that anyone could replicate this success with similar results. Because the interface that they are using is the standardized JCache. The servers are proven so they can be replicated. Switching from local to embedded wasn’t difficult. They have their own interface for caching, they just need to rewrite it for Hazelcast. The application still thinks it’s using local, so it doesn’t affect it.
They had been running Hazelcast server with Hazelcast node inside, now they’ll place the same call. Instead of talking to a server API, they’ll be talking to a client API/library. Whether it’s embedded or remote doesn’t make a difference to how Hazelcast runs...it’s the same API. They remove the server jars and input the Hazelcast client jars and they start talking to the caching service remotely. Because they maintained the same caching service wrapper it was easy to switch from local to embedded Hazelcast to JCache.
Conclusion
This project has already been running for several years and has gone through two distinct phases.
In the first phase, the customer scaled up to hundreds of nodes of Hazelcast and entered into a commercial support agreement which resulted in collaboration and success with this first phase of the project.
Having launched, scaled and operated this Hazelcast system for a year, the team then gained an appetite to roll out an even more significant Hazelcast phase two which involved changing the deployment topology to Hazelcast in a dedicated cluster of servers, with distributed clients all connecting to the dedicated cluster. The team also elected to upgrade to Hazelcast Enterprise largely to take advantage of the Off-Heap memory manager feature which enabled them to scale up and build a much smaller cluster with much larger machines, and to gain complete predictability over Garbage Collection pauses.
The customer also moved from a proprietary cache abstraction layer to the Java standard, JCache.
With this in place, the customer was able to meet all of the objectives stated at the beginning, which was to deploy an elastically scalable caching solution based on industry standards that could meet all of their needs while at the same time lowering both licensed software cost as well as hardware, development, operations, switching costs and talent costs.