
By Yuce Tekol
Senior Software Engineer II
Yüce is the tech lead of Hazelcast CLC. In most of his 15+ years of career in software, he worked as a full-stack and backend developer at US-based companies. Yüce worked as a research assistant before his software career and he has several published papers on Computational Intelligence.
View all blogs by the authorOct 3, 2022
Unboxing Hazelcast Go Client v1
Hazelcast has clients for C++, .NET, Java, Python, and Node.js and has top-notch support. Although we also had a Go client, we lacked that level of support until the release of Go client v1 last year.
Hazelcast is an open-source memory-first application platform for stream processing and data-intensive workloads on-premises or as a cloud service for those unfamiliar with what we do.
No doubt, the biggest highlight of this release is support for Hazelcast 4 and 5. Hazelcast 4 has considerable performance improvements over Hazelcast 3, while Hazelcast 5 introduced several new features, such as a new SQL engine. We already support most of those excellent features and will roll out the rest in the coming releases.
Tailored for the Go Ecosystem
At Hazelcast, developer experience is one of our top priorities. We tailored the Go client to fit well in the Go ecosystem with this significant client release. Let’s go over the highlights.
Go Module Support
Module support was introduced in Go 1.11. Before it was introduced, standard tools did not support dependency management, and we had to depend on third-party tools, such as dep and glide.
Enabling go modules for your project is straightforward:
go mod init github.com/myorg/myproject
The command above uses github.com/myorg/myproject as the module name, but you can choose anything else. I highly recommend reviewing the following article for in-depth coverage of Go modules: Using Go Modules.
Once you have a Go module enabled project, adding the Hazelcast Go client to your project is trivial. You can depend on the latest release using:
go get github.com/hazelcast/hazelcast-go-client
Or depend on a specific release, v1.3.0 in this case:
go get github.com/hazelcast/[email protected]
After that, you can import the client in your code as usual:
import "github.com/hazelcast/hazelcast-go-client"
Go Context Support
One of the most wanted features for the new Go client was Go context support in the API. That’s not surprising, since contexts are indispensable when you need to chain calls to several APIs and have a way to break the chain anywhere.
Many articles explain how to use the context package, especially this one from the Go blog: https://blog.golang.org/context.
All Hazelcast Go client functions take context as the first parameter. For instance, we limit the Map set operation to complete in 500 milliseconds or less in the code below:
func mapSetWithTimeout(key, value interface{}) error {
// create a context with timeout of 500 milliseconds
ctx, cancel := context.WithTimeout(context.Background(), 500*time.Millisecond)
// make sure cancel is called at least once
defer cancel()
return myMap.Set(ctx, key, value)
}
Later, we call the sample function:
err := mapSetWithTimeout("my-key", "my-value")
if errors.Is(err, context.ErrCanceled) {
fmt.Println("context is canceled")
} else if errors.Is(err, context.Deadline) {
fmt.Println("context deadline exceeded")
} else if err != nil {
fmt.Println("some other error", err)
} else {
fmt.Println("OK!")
}
In case you don’t want to use a context with Hazelcast Go Client API functions, you can pass context.TODO(). It will act as a reminder to use the correct context later.
Overhauled Configuration
The default configuration works well when you run a Hazelcast Go client on the same machine with the Hazelcast server. That’s very common when testing the client on your laptop. We have the hazelcast.StartNewClient function, which uses the default configuration:
client, err := hazelcast.StartNewClient(context.TODO())
In all other cases, you would need to configure the client. The workflow is simple: you create the default configuration, update it as necessary, then pass it to hazelcast.StartNewClientWithConfig(ctx, config).
Most fields of hazelcast.Config struct are exported, and the default configuration of that struct is zero value. Here’s a sample:
config := hazelcast.Config{}
config.Cluster.Name = "production"
config.Cluster.ConnectionStrategy.Timeout = types.Duration(10*time.Second)
config.Cluster.Network.Addresses = []string{"100.200.300.401:5701", "100.200.300.402:5701"}
// alternatively:
// config.Cluster.Network.SetAddresses("100.200.300.401:5701", "100.200.300.402:5701")
config.Logger.Level = logger.ErrorLevel
This approach makes the configuration API more idiomatic. Also, configuration via JSON is a breeze, as seen below:
{
"Cluster": {
"Name": "production",
"Network": {
"Addresses": [
"100.200.300.401:5701",
"100.200.300.402:5701"
]
},
"ConnectionStrategy": {
"Timeout": "10s"
}
},
"Logger": {
"Level": "error"
}
}
YAML configuration is available using go-yaml too. Note that go-yaml requires fields to be written in lowercase, in contrast with the title case used in the JSON example:
cluster:
name: "production"
network:
addresses:
- "100.200.300.401:5701"
- "100.200.300.402:5701"
connectionstrategy:
timeout: "10s"
logger:
level: "error"
Unsurprisingly, configuration via TOML works well too:
[cluster]
name = "production"
[cluster.network]
addresses = [
"100.200.300.401:5701",
"100.200.300.402:5701"
]
[cluster.connectionstrategy]
timeout = "10s"
[logger]
level = "error"
In the programmatic configuration, you’ll notice that connection timeout is given by casting time. Duration to types.Duration. To be able to use human-readable names, like “10s” in JSON/YAML, etc., we had to create another type for durations in the configuration.
We included some convenience methods to modify the configuration, such as config.Cluster.Network.SetAddresses, which is equivalent to setting config.Cluster.Network.Addresses.
config.Cluster.Network.SetAddresses("100.200.300.401:5701", "100.200.300.402:5701")
Note that some configuration values cannot be marshalled/unmarshalled, such as Portable factories. Those kinds of settings are only accessible using methods.
config.Serialization.SetPortableFactories(&MyPortableFactory{})
Idiomatic Errors
Go errors are simple. In many cases, all one needs to do is return errors.New(“some problem”). If the error should be part of the API, it can be assigned a name:
var ErrSomeProblem = errors.New("some problem")
Errors are created with errors. New are unique, even if they have the same message. So, in your code, you can check for that particular error by using a simple if statement:
if err == ErrSomeProblem { ... }
Error handling gets “interesting” when it should contain more information about the error, such as why it happened. Of course, you can include that information in the error message. But then you can’t assign a name to it, and you won’t be able to check it simply using an if statement. You can always create a new error type (and sometimes you should), but creating a new one just to distinguish between different error types gets tedious.
Fortunately, Go 1.13 introduced a better solution: error wrapping/unwrapping: Working with Errors in Go 1.13 Using the errors. In function, it is straightforward to match the mistakes even if it is wrapped inside other errors. Every error returned from Go Client v1 API supports that usage.
Here’s an example. Index attributes should not have dot prefixes, and trying to use such an attribute with a map.AddIndex results in hzerrors.ErrIllegalArgument:
ic := types.IndexConfig{Attributes: []string{"Foo."}}
ctx := context.Background()
client, _ := hazelcast.StartNewClient(ctx)
m, _ := client.GetMap(ctx, "my-map")
err := m.AddIndex(ctx, ic)
// Output: attribute name cannot end with dot: Foo.: illegal argument error
fmt.Println(err)
// Output: true
fmt.Println(errors.Is(err, hzerrors.ErrIllegalArgument))
The error contains an excellent explanation about the error, and also it is straightforward to check whether it matches a known error.
You can check out https://github.com/hazelcast/hazelcast-go-client/blob/master/hzerrors/errors.go for the list of possible error values.
Even though the error mechanism used internally in the client is more complex, the errors package enabled us to deliver a convenient API for our users.
Other Enhancements
External Smart Client Discovery
The client sends requests directly to cluster members in the intelligent client mode (default) to reduce hops to accomplish operations. Because of that, the client should know the cluster members’ addresses.
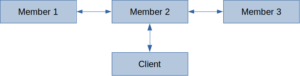
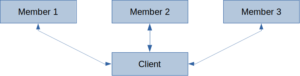
In cloud-like environments or Kubernetes, there are usually two network interfaces, the private facing one and the public-facing one. When the client is in the same network as the members, it uses their private network addresses. Otherwise, if the client and the members are on different networks, the client cannot connect to members using their private network addresses. Hazelcast 4.2 introduced External Smart Client Discovery to solve that issue.
To use this feature, make sure your cluster members are accessible from the network the client resides in, then set config.Cluster.Discovery.UsePublicIP to true. You should specify the address of at least one member in the configuration:
config := hazelcast.Config{}
// public address of the member
config.Cluster.Network.SetAddresses("3.4.5.6:5701")
config.Cluster.Discovery.UsePublicIP = true
This solution works everywhere without further configuration: Kubernetes, AWS, GCP, Azure, etc. as long as the corresponding discovery method is enabled in the Hazelcast server configuration.
Map Locks
Hazelcast provides pessimistic lock support for Maps. With Hazelcast Go client v1, we fully support this API.
When an entry is locked, only the owner of that lock can access that entry in the cluster until it is unlocked by the owner of force unlocked.
See https://docs.hazelcast.com/imdg/latest/data-structures/map.html#locking-maps for details.
Locks are reentrant. A lock owner can acquire the lock again without waiting for the lock to be unlocked. If the key is locked N times, it should be unlocked N times before another goroutine or another client in the cluster can acquire it.
Lock ownership in Hazelcast Go Client is explicit. The first step to owning a lock is creating a lock context, similar to a key. The lock context is a regular context. Context carries a special value that uniquely identifies the lock context in the cluster. Once the lock context is created, it can be used to lock/unlock entries and used with any function that is lock aware, such as Set.
m, err := client.GetMap(ctx, "my-map") // create the unique lock context lockCtx := m.NewLockContext(ctx) // acquire the lock, blocks until it is acquired err = m.Lock(lockCtx, "some-key") // pass lock context to use the locked entry err = m.Set(lockCtx, "some-key", "some-value") // release the lock once done with it, so "some-key" is available for others err = m.Unlock(lockCtx, "some-key")
Check out the lock example. In that example, a map value is incremented by several goroutines using a map lock to prevent data races.
As mentioned before, lock context is a regular context. The context that carries a unique lock ID. You can pass any context. Context to any Map function that takes a lock context. But in that case, the same lock ID is used for those operations, and there is no way to enforce lock ownership when using the same client (lock ownership is still maintained in the cluster). To prevent data races, consider always using the lock context for map operations when using multiple goroutines with the same client.
Conclusions and Pointers
This is a significant milestone for the Hazelcast Go client. But that’s not all: there are more features we didn’t cover in this article, like Near Cache and SQL. We have upcoming articles about those features.
Here are a couple of links you may find helpful:
- Home of the Hazelcast Go Client
- Official repository
- Client documentation
- Hazelcast documentation
- Hazelcast Community Slack channel for Go client help/discussion
- You can start developing Go applications with our client and using our cloud offering right away: Hazelcast Viridian Serverless.
Your feedback is valuable for us to provide the features you want and fix any pain points. Reach out to us on GitHub or Slack for anything related to Hazelcast and the Go client.

