
Mehmet is a software engineer working on the Management and Monitoring team. Since joining Hazelcast as an intern, he has worked on projects including client APIs, ML integrations, and monitoring applications.
View all blogs by the authorDec 5, 2023
Supercharging real-time machine learning pipelines with feature stores
At the core of translating machine learning concepts into practical applications lies the essential role of machine learning pipelines. These data pipelines serve as the backbone, facilitating the conversion of raw data into actionable insights. They string together a series of crucial stages, encompassing data preprocessing, feature engineering, model training, validation, and deployment. In this process, feature stores play a pivotal role. A feature store is a platform designed to manage data storage and access for both historical and live feature data, offering advanced features like the creation of point-in-time datasets. These feature stores seamlessly integrate with machine learning pipelines to enhance the efficiency and consistency of the entire workflow.
Feast, for instance, provides both offline and online feature stores. The offline feature store contains historical datasets and features primarily utilized for training models. For instance, in a credit card fraud management scenario, the offline feature store might incorporate features generated from combined transaction and customer datasets.
On the other hand, the online feature store houses the most recent data and features, ideal for real-time machine learning inference. In the same fraud detection example, the online feature store could supply the necessary data to calculate features like the number of transactions in the last 60 minutes, which is crucial for immediate fraud identification.
Incorporating feature stores into machine learning pipelines bridges the gap between data engineering and machine learning. By ensuring consistent and efficient access to features across different stages, organizations can streamline the transition from raw data to valuable insights, ultimately enhancing the effectiveness of their machine learning applications.
Online features are either generated in real-time or at periodic intervals, often derived from the offline feature store. In this blog post, our focus will be on understanding online feature stores through the lens of the “fraud detection” tutorial available at Feast’s documentation (https://docs.feast.dev/tutorials/tutorials-overview/fraud-detection). This tutorial will help elucidate the distinction between online and offline feature store concepts and shed light on the role played by Hazelcast Platform as an online feature store in this context.
A primary advantage of leveraging online feature stores is the notable reduction in inference latency. Particularly in credit card fraud management, where responsiveness is critical and results need to be generated within 50 milliseconds, the presence of online features stored in a low-latency repository like Hazelcast Platform becomes pivotal. This choice greatly aids in meeting stringent performance benchmarks.
It’s important to emphasize that feature stores are not databases; they rely on underlying systems for data storage. Feast, a widely used open-source feature store, offers support for various databases such as DynamoDB, Redis, PostgreSQL, among others, as the foundational storage mechanism for “features.” Opting for an in-memory data platform for the “online feature store” significantly enhances performance by eliminating the reliance on disk-based storage. Notably recognized for its fast data store, Hazelcast Platform is now integrated as an online feature store within the Feast ecosystem.
Using Hazelcast Platform with Feast
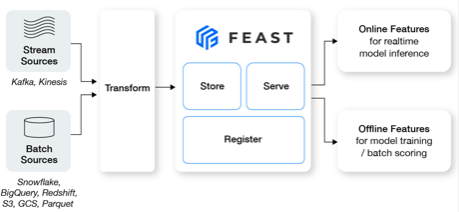
Feast is a standalone, open-source feature store that organizations use to store and serve features consistently for offline training and online inference. To explain how to use Hazelcast Platform with Feast, we will go through the Fraud Detection tutorial prepared by Feast and configure Hazelcast as the online store. In this tutorial, a machine learning model evaluates transactions’ potential for fraud in real-time while the users carry out the transaction. To achieve the real-time response, we need to generate a prediction at low latency.
Install Feast
First, we need to install Feast with the Hazelcast Platform client package included.
pip install ‘feast[hazelcast]’
Initialize Feature Store
Now we can initialize a feature store. Feature store initialization creates the configuration and registry files for us. Inside the initialized feature repository, we can define entities, feature sets, and data storage connections.
feast init FEATURE_STORE_NAME -t hazelcast
This command starts the Hazelcast Platform template wizard for Feast where you can create a feature store with Hazelcast Platform configured as the online store. The template wizard asks the connection secrets such as cluster name, address. You can choose to connect Hazelcast Viridian Cloud by selecting the cluster type as Viridian in the first question. You can configure those manually later on by editing the online store section in feature_store.yaml file. Check out this page for more information: https://docs.feast.dev/reference/online-stores/hazelcast. At the end, feature_store.yaml file should look like following for a local cluster connection:
project: YOUR_PROJECT_NAME
...
online_store:
type: hazelcast
cluster_name: dev
cluster_members: ["localhost:5701"]
key_ttl_seconds: 36000
Create Feature Set based on offline data
To store historical data, the offline data store should be set up with the databases supported by feast. This provides bulk storage of all historical data where we don’t need low latency. Using the offline data storages as batch source, we can define feature views. A feature view is an object that represents a logical group of time-series feature data as it is found in a data source. Note: that feast requires all feature views to be based on time series feature data, therefore data must be converted into a time series format
user_account_fv = FeatureView(
name="user_account_features",
entities=["user_id"],
ttl=timedelta(weeks=52),
batch_source=BigQuerySource(
table_ref=f"user_account_features",
event_timestamp_column="feature_timestamp"
)
)
Here, we have created an abstraction over the underlying BigQuery data storage. The user_account_features is an existing table in BigQuery. This table can include columns such as credit_score, account_age_days, customer_location etc. Additional columns such as number_of_transactions_in_the_last_hour have to be computed and stored in the offline feature store. The feature view definitions make it possible to manage and access data using Feast API.
We need to run the apply command to register those data connections to the registry file of our feature store.
feast apply
Now we have a batch source and feature view defined over it. We can create point-in-time joins over multiple feature views and generate a consolidated feature set to train machine learning models.
training_data = store.get_historical_features(
...
features=[
...
"user_account_features:credit_score",
"user_account_features:account_age_days",
"user_account_features:user_has_2fa_installed",
...
])
Feast to_df() function returns a pandas data frame with this feature set to train the machine learning model.
Materialization to Online Feature Store
We should materialize the offline store to our configured online store, Hazelcast Platform. During the inference phase, we need the latest features of each user to generate the prediction. Using a traditional data storage for this operation is costly since we need to access the disk-based storage and get the feature with the latest timestamp value. The system needs to use fast data storage to access the latest features for each user. Considering that there might be thousands of users at the same moment we need to generate predictions, the batch sources do not help. Hazelcast Platform online store provides this functionality with its low latency storage.
Hazelcast Platform was initialized as a feature store in the section above and the command below materializes the latest timestamp data points for the feature view definitions to a Hazelcast Platform cluster.
feast materialize-incremental $(date -u +"%Y-%m-%dT%H:%M:%S")
Inference using Online Feature Store
After materialization, we can access the features from Hazelcast Platform in the inference pipeline. This allows us to detect fraud transactions in real-time at low latency. Below API call pulls the online features from Hazelcast Platform cluster through Feast API.
feature_vector = store.get_online_features(
features=[
...
"user_account_features:credit_score",
"user_account_features:account_age_days",
"user_account_features:user_has_2fa_installed",
...
])
Suppose that you have a predict function which takes the new Kafka message as argument and runs the ML model to decide whether the transaction is fraud or not. The inference stage of pipeline looks like following:
def predict(message):
// Load features based on message user entity
feature_vector = store.get_online_features(
features=[
…
"user_account_features:credit_score",
"user_account_features:account_age_days",
"user_account_features:user_has_2fa_installed",
…
])
// Any processing on the feature vector
is_fraud = model.predict(feature_vector)
// Any processing on result
return is_fraud
Our machine learning model receives the feature vector we created using online features and generates predictions in real-time using the latest features of the user.
Notice that we omitted some parts of the tutorial to emphasize the importance of online stores. You can go over the full tutorial and configure Hazelcast Platform as an online store as described above.
Summary
Hazelcast Platform’s availability as an online feature store within the Feast ecosystem streamlines the transition from raw data to actionable insights. Machine learning pipelines are the backbone of practical applications, and feature stores play a crucial role in managing data storage and access for historical and live feature data. Feast, an open-source feature store, provides offline and online stores, with online stores catering to real-time inference needs.
Feast’s integration with Hazelcast Platform allows organizations to materialize features efficiently for low-latency access during the inference phase. This is especially beneficial for time-critical applications like fraud detection, where responsiveness within milliseconds is crucial. By configuring Hazelcast Platform as an online store, the materialization of the latest timestamp data points is facilitated, enabling seamless access to features for real-time decision-making. This integration not only reduces inference latency but also ensures accurate predictions by leveraging the latest user features.
We look forward to your feedback and comments about this blog post! Share your experience with us in the Hazelcast community Slack and the Hazelcast GitHub repository. Hazelcast also runs a weekly live stream on Twitch, so give us a follow to get notified when we go live.

