
By Dan Ortega
Product Marketing
Dan has had more than 20 years of experience helping customers understand the business value of technologies. His domain expertise spans enterprise software, IoT, ITSM/ITOM, data analytics, mobility, business intelligence, SaaS, content management, predictive analytics, and information lifecycle management. Throughout his career, Dan has worked with companies ranging in size from start-up to Fortune 500 and enjoys sharing insights on business value creation through his contributions to the Hazelcast blog. Dan was born in New York, grew up in Mexico City, and returned to get his B.A. in Economics from the University of Michigan.
View all blogs by the authorOct 17, 2019
Right-Sizing Your On-Demand Infrastructure for Payment Processing in Any Cloud
In an ideal world, consumer-facing online businesses would deliver a consistent, efficient, and secure payment processing experience to their customers. Although there are lots of variables in running an e-commerce site, completing the sale is pretty much at the top of the list. When consumers go online to make purchases during a busy period such as Black Friday, they don’t expect to spend a lot of time “standing” in a virtual line; if they’re forced to, they will likely jump to another site. This is the cardinal sin of e-commerce; customers are standing there, money in hand, ready to pay, and then they leave out of frustration.
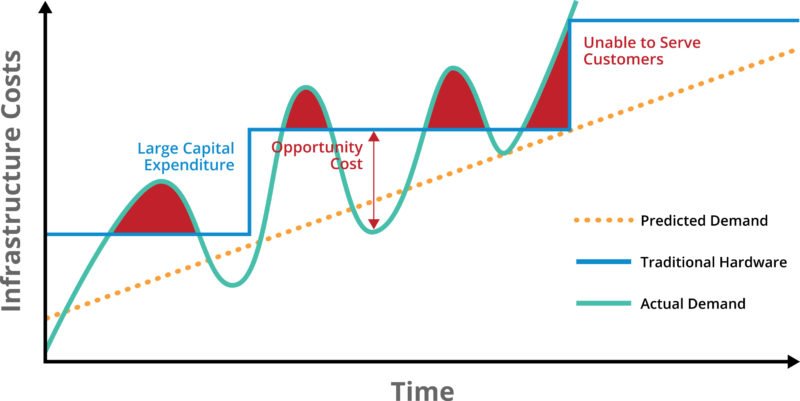
A big part of the reason consumers get stuck in line is lack of proper IT infrastructure; that is, companies have historically tried to build out on-premises infrastructure to meet a predictable level of demand. The problem is that demand is unpredictable and dynamic, and on-premises infrastructure is not. Historically, it has looked like this:
Business drivers for most e-commerce businesses and the payment processing infrastructure that enables them are a function of consumer demand. These can be positive events, such as strong demand for a new product on a launch date, or for seasonal events such as Cyber Monday, Black Friday, or Singles Day. It can, however, also be triggered by negative events, such as a service failure that triggers a huge influx of calls (e.g., to customer service), or something that starts out well and then heads south in a hurry, such as unexpectedly high demand that triggers an infrastructure crash or garden-variety slow response. Thus the big IT challenge has always been, “How do you match what you have to what you need?”
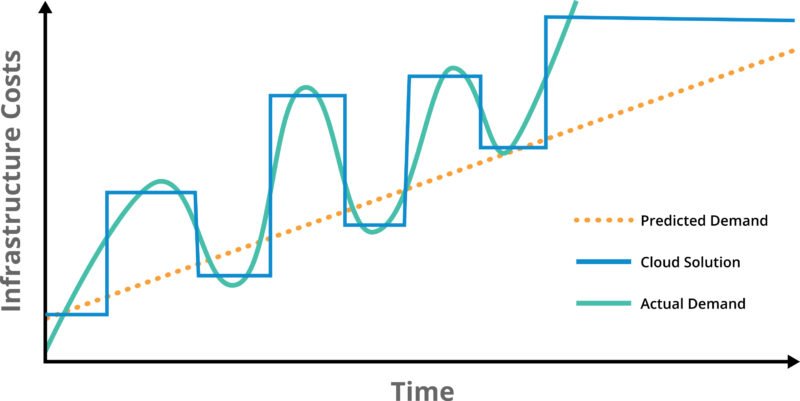
This scenario has been around for several years, and one of the compelling reasons to move to the cloud is the ability to have more control over the availability of infrastructure to match demand. In the scenario below, the two curves are able to track each other more closely, although as you would expect, the cloud infrastructure curve lags behind the demand curve. It looks something like this:
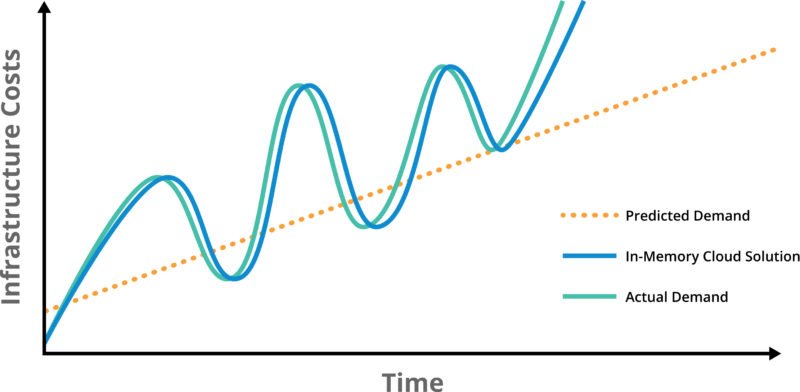
The ideal scenario is to have your cloud infrastructure scale up and down instantly in response to fluctuations in demand. This has not really been an option until recently, but with improvements in both in-memory processing (1000X faster than a database) and distributed cloud architectures (instant load balancing, hot restart enabled by persistent memory), the ability to respond instantly—and this means instantly from a human’s perspective, not a computer’s—is now a reality. Suddenly the risk of losing a sale due to delays in payment processing becomes a rapidly receding spot in your rear-view mirror. This scenario looks like this:
The architecture to support this scenario is relatively new, but has been tested by some of the most demanding payments infrastructure and e-commerce companies in the world, and is now in the process of being rolled out. The structure looks like this:
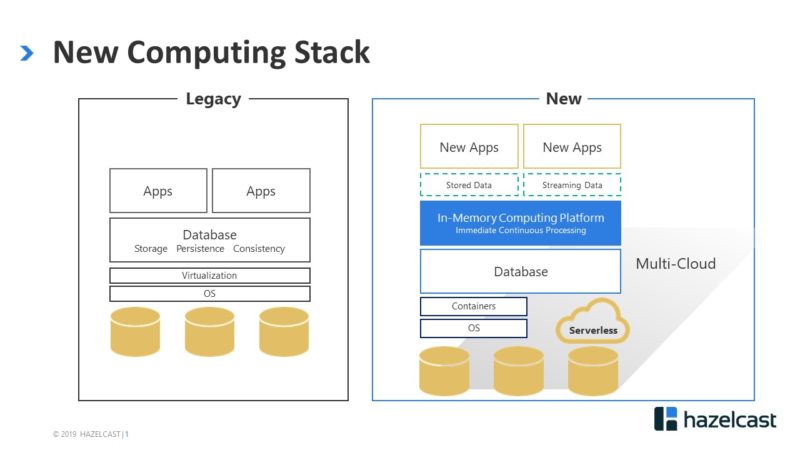
In this model, applications that are revenue-critical are no longer constrained by the slow journey across the network to a database to retrieve that one key piece of information needed to process a payment. Because random-access memory (RAM) is now measured in terabytes, information that previously could only be stored in a database can now be cached in-memory, enabling transactions to run at RAM speed. This includes static (stored) data such as customer information (payment history, service calls, etc.), as well as streaming data such as the particulars of the transaction itself, plus meaningful value-adds like feeding fraud detection algorithms. All of this is now running at sub-millisecond speed, millions of times per second, in a cloud infrastructure that adjusts automatically to changes in demand. This is the value of in-memory, and it applies to pretty much everything we do.
To learn more, dive into our rich collection of resources.