Platform›Hot Restart Store
Hot Restart Store
High-performance persistence for fast cluster restarts.
Dramatically reduce restart time for large caches by enabling fast data reloads
Whether the restart is a planned shutdown or a sudden cluster-wide crash, Hot Restart Store allows full recovery to the previous state of configuration and cluster data.
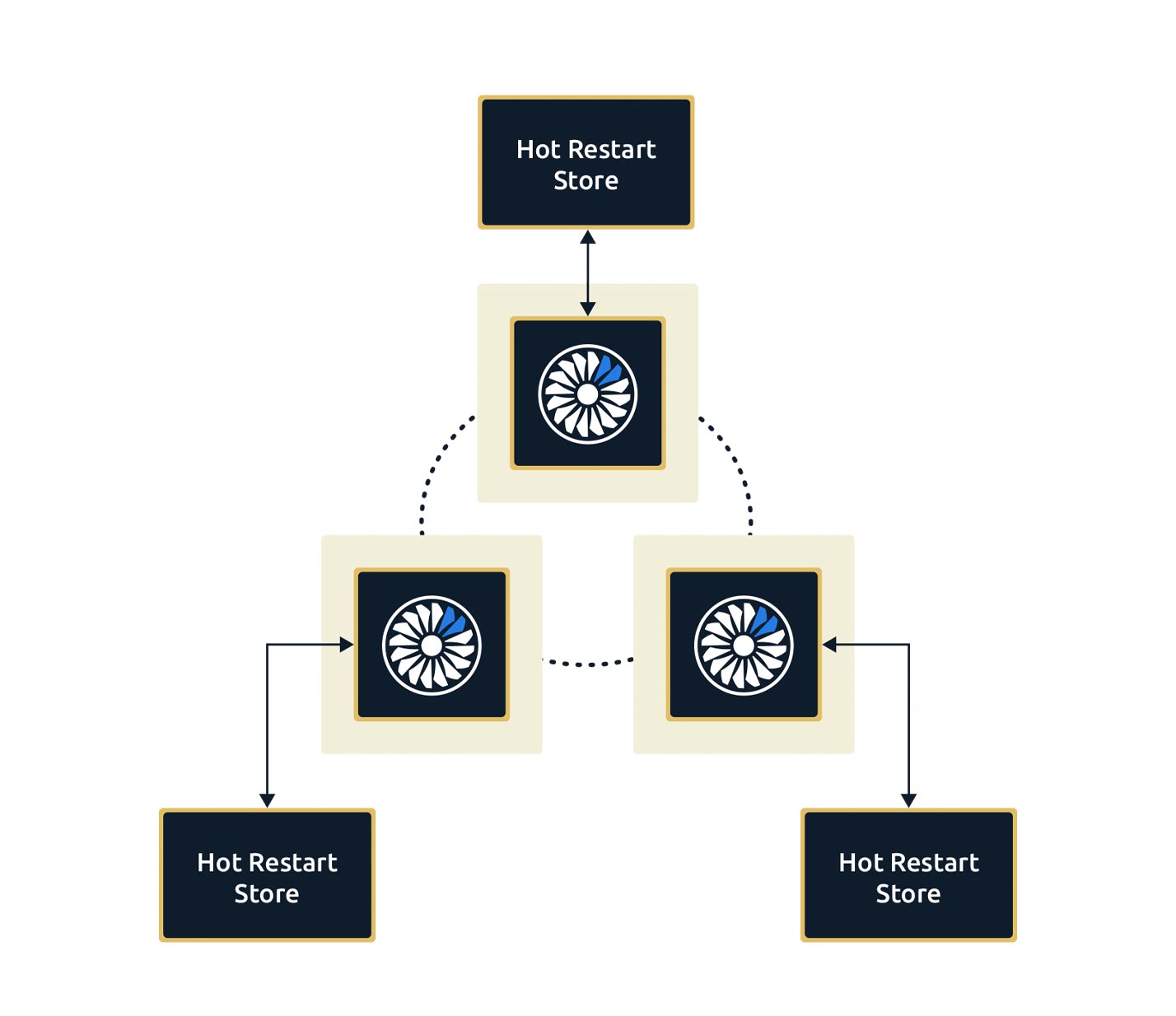
Local Control
Each node controls its own local snapshot, providing linear scaling across the cluster.
Industry Standards
Hot Restart Store supports the IMap and JCache interfaces, as well as Web Sessions and Hibernate, with further data structures planned in subsequent releases.
Features
Speed and Performance
Persistence store optimized for SSD and mirrored in native memory.
Linear Scaling Across Clusters
Each node operates its own independent store.
In-Memory Speeds
Data entirely loaded into RAM on reload, ensuring you always operate at in-memory speeds.
Data Persistence
Configurable per data structure for JCache, Map, Web Sessions and Hibernate.