
By Greg Luck
Chief Technical Officer
Greg Luck is a leading technology entrepreneur with more than 15 years of experience in high-performance in-memory computing. He is the founder and inventor of Ehcache, a widely used open source Java distributed cache that was acquired by Software AG (Terracotta) in 2009, where he served as CTO. Prior to that, Greg was the Chief Architect at Australian start-up Wotif.com that went public on the Australian Stock Exchange (ASX:WTF) in 2006. Greg is a current member of the Java Community Process (JCP) Executive Committee, and since 2007 has been the Specification Lead for JSR 107 (Java Specification Requests) JCACHE. Greg has a master's degree in Information Technology from Queensland University of Technology and a Bachelor of Commerce from the University of Queensland.
View all blogs by the authorJun 10, 2016
We just made Hazelcast 3.7 30% faster
3.7 30% Faster Across the Board
3.7 EA just got released. And I am happy to say our Performance Team led by Peter Veentjer found another amazing optimisation. The main change this time was to remove notifyAll and synchronized blocks in the networking layer and replace them with LockSupport.park/unpark. The code change was done on the Member to Member code and the Client to Member code. So the change lifts performance for most operations by 30% across both topologies.
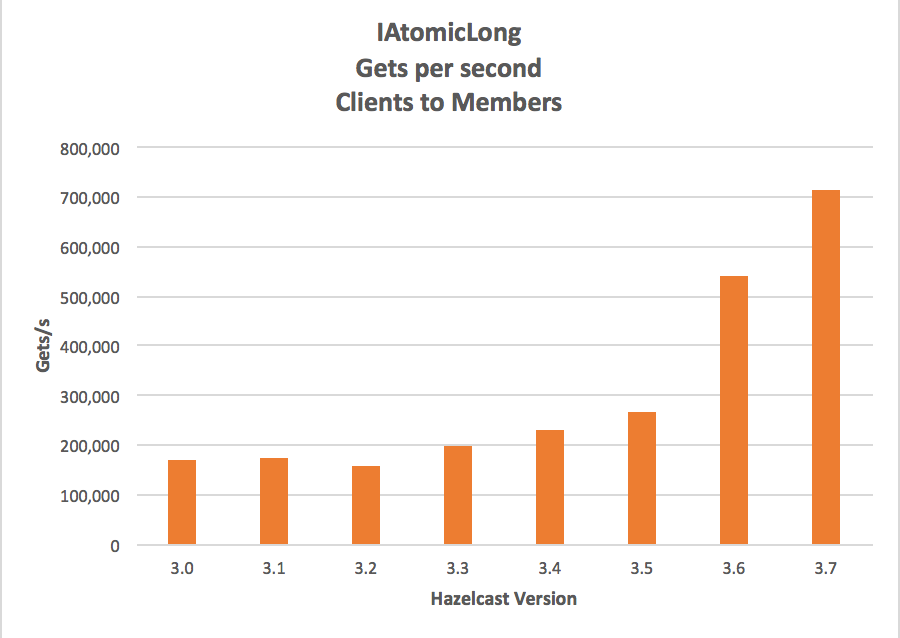
Hazelcast 3.6, based on the extensive benchmarks we do and publish, was already the fastest In-Memory Data Grid and Distributed Cache, including Redis. With this change we will open up a larger air gap between us and the rest. Look for our benchmarks against each to get updated over the next few months.
The Performance Increase in Pictures
We use AtomicLong.get/put here because the payload is always a fixed 8 bytes and it makes very clear the performance changes. These numbers are for a four node cluster all measured on a 1Gbps network in our Perf Lab.
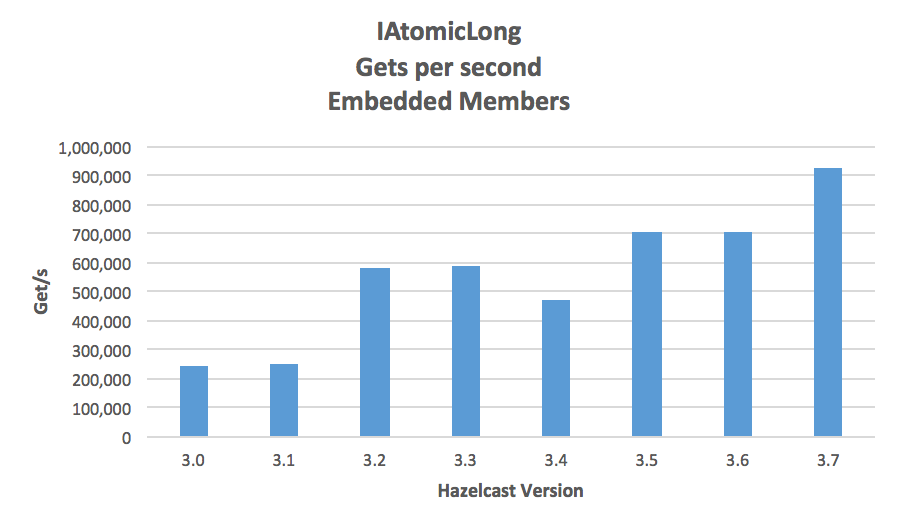
What got Changed
Firstly we unified the client and member code bases in this area so they automatically benefit from optimization work.
Progress was made in the border between the networking layer and the the engine, i.e. when a packet containing an operation comes in it goes into the operation queue. This is a task completed by the IO Thread, but internal to the engine.
We made several optimizations:
- The invocation future, triggered by the response thread, has been upgraded to make use of LockSupport instead of synchronized wait/notify
- The response queue, responsible for receiving responses from io threads is implemented using the MPSCQueue (more about that below)
- The operation queue, responsible for receiving operation from i pthread, to be executed by an operation thread, is implemented using the MPSCQueue
The MPSCQueue is our Multi Producer, Single Consumer Queue. It is again written with LockSupport.
What’s Next?
The last two releases have seen an explosion in Hazelcast performance. So what’s next? In Hazelcast 3.8 we will (most likely) shift our attention to the following areas:
Optimising In-Process Operations in Embedded Members
Here we plan to bypass the operation thread and use the calling thread – tests indicate a 10x performance increase is possible. This should make the performance of a local operations on an embedded Hazelcast member much closer to what you get from a purely in-process cache like Ehcache or Guava, expanding the use cases for Hazelcast.
This will be particularly useful for:
- ReplicatedMap
- Near Cache in Embedded Members – we will cache only remote member entries – local entries will be fast enough not to need the extra copy in near cache
Near Cache
In Hazelcast, near cache – a copy of the cache that is in-process with you on your side of the network – is used both in client and in members. This simple trick, a copy on your side of the network, will be expanded in 3.8.
First we will make a whole bunch of changes to near cache to make it more usable in more scenarios. Many have been suggested by our users.
Second we will be adding a storebyreference option so that we skip copying on get and just return the reference. This is how in-process caches work by default.