
By Rafal Leszko
Cloud Software Engineer
Rafał is a passionate software engineer, trainer, conference speaker, and author of the book, Continuous Delivery with Docker and Jenkins. He specializes in Java development, cloud environments, and continuous delivery. Prior to joining Hazelcast, Rafał worked with a variety of companies and scientific organizations, including Google, CERN, and AGH University of Science and Technology.
View all blogs by the authorDec 3, 2019
Hazelcast Resilient to Kubernetes Zone Failures
Data is valuable. Or I should write, some data is valuable. You may think that if the data is important to you, then you must store it in the persistent volume, like a database or filesystem. This sentence is obviously true. However, there are many use cases in which you don’t want to sacrifice the benefits given by in-memory data stores. After all, no persistent database provides fast data access or allows us to combine data entries with such high flexibility. Then, how to keep your in-memory data safe? That is what I’m going to present in this blog post.
High Availability
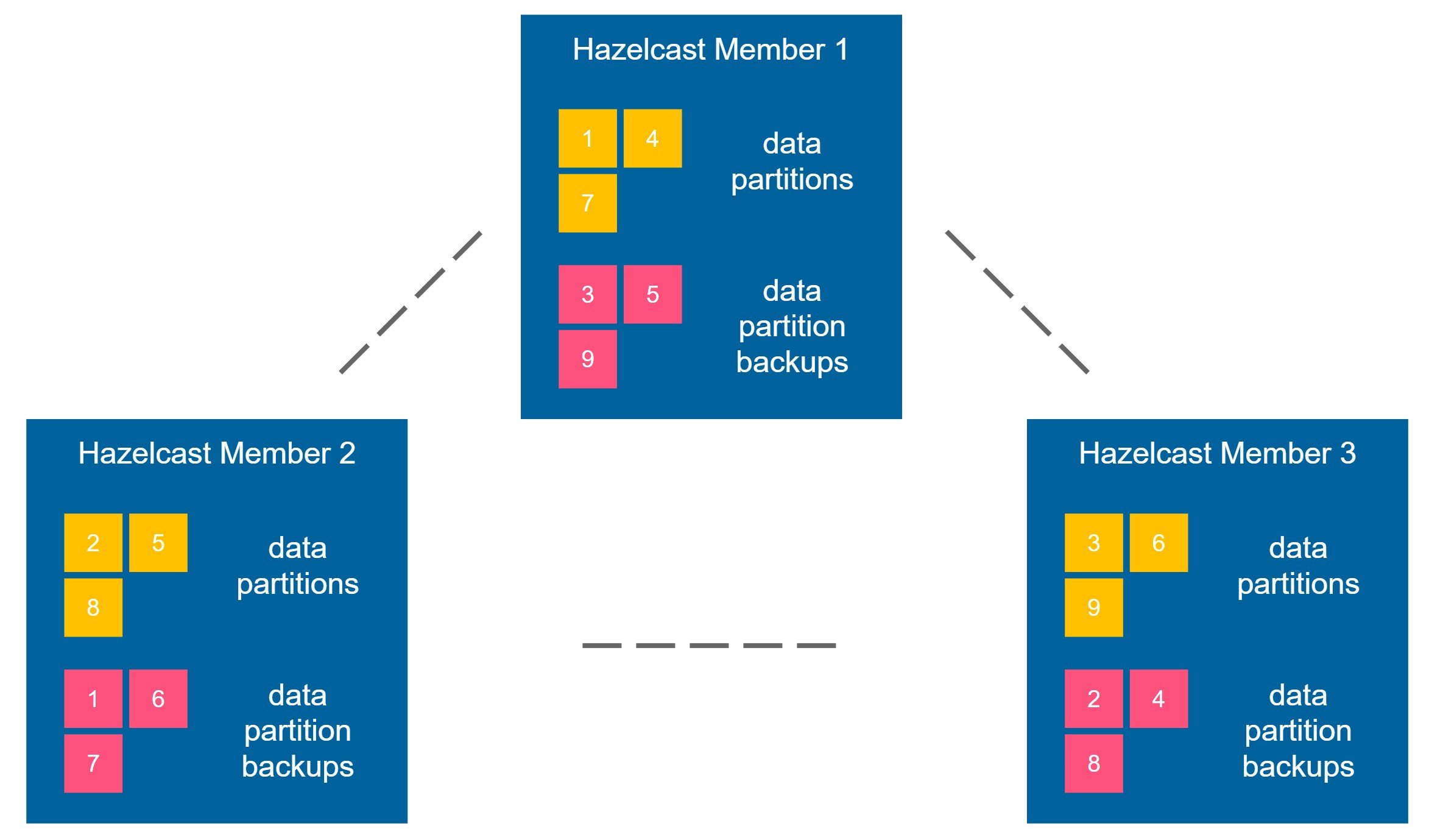
Hazelcast is distributed and highly available by nature. It’s achieved by keeping the data partition backup always on another Hazelcast member. Let’s look at the diagram below.
Imagine you put some data into the Hazelcast cluster, for example, a key-value entry (“foo”, “bar”). It is placed into the data partition 1, and this partition is situated in the member 1. Now, Hazelcast guarantees that the backup of any partition is kept in a different member. So, in our example, the backup of the partition 1 could be placed in the member 2 or 3 (but never in the member 1). Backups are also propagated synchronously, so the strict consistency is preserved.
Imagine that member 1 crashes. What happens next is that the Hazelcast cluster detects it, promotes the backup data, and creates a new backup. This way, you can always be sure that if any of the Hazelcast member crashes, you’ll never lose any data. That is what I called “high availability by nature.”
We can increase the backup-count property and propagate the backup data synchronously to multiple members at the same time. However, the performance would suffer. In the corner case scenario, we could have backup-count equal to the number of members and then even if all members except for one crash, the data is not lost. Such an approach, however, would not only be very slow (because we have to propagate all data to all members synchronously), but it would also use a lot of in-memory data. That is why it’s not very common to increase the backup-count. For the simplicity of this post, let’s say that we’ll always keep its value as 1.
High Availability on Kubernetes
Let’s move the terminology from the previous section to Kubernetes. We can say we’re sure that if one Hazelcast pod fails, we don’t experience any data loss. So far, so good. It sounds like we are highly available, right? Well… yes and no. Let’s look at the diagram below.
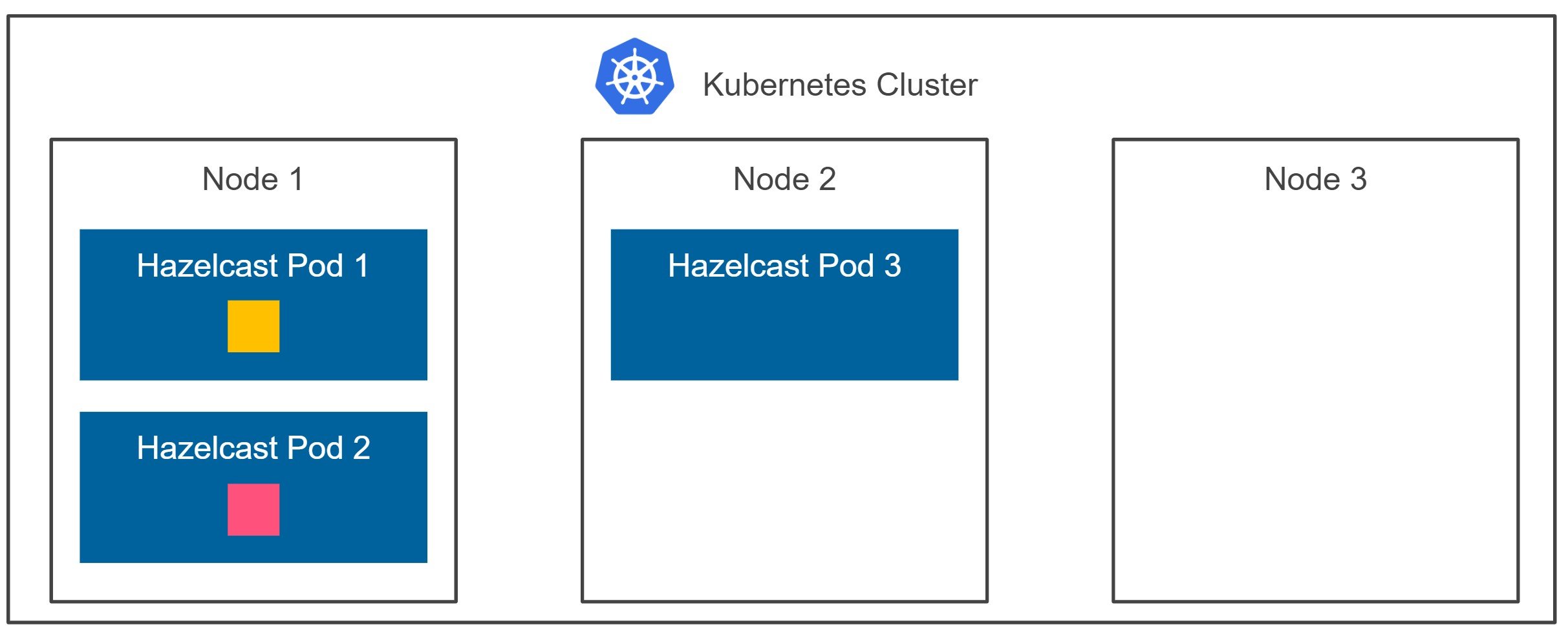
Kubernetes may schedule two of your Hazelcast member pods to the same node, as presented on the diagram. Now, if node 1 crashes, we experience data loss. That’s because both the data partition and the data partition backup are effectively stored on the same machine. How to solve this problem?
Luckily, Kubernetes is quite flexible so that we may ask it to schedule each pod on a different node. This can be done using the Inter-pod affinity feature. In our case, if we’d like to be sure that each Hazelcast member is scheduled on a separate node, assuming our application name is “hazelcast”, we need to add the following configuration.
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- hazelcast
topologyKey: kubernetes.io/hostname
Note that with such configuration, you must be aware of what nodes are available and ensure not to run more Hazelcast members than the number of Kubernetes nodes. Otherwise, Kubernetes won’t schedule some of your pods. We could also use preferredDuringSchedulingIgnoredDuringExecution instead of requiredDuringSchedulingIgnoredDuringExecution, but then we’d again be unsure if no two Hazelcast members are scheduled on the same Kubernetes node.
All in all, with some additional effort, we achieved high availability on Kubernetes. Let’s see what happens next.
Multi-zone High Availability on Kubernetes
At this point, we’re sure that if any of the Kubernetes nodes fail, we don’t lose any data. However, what happens if the whole availability zone fails? Let’s look at the diagram below.
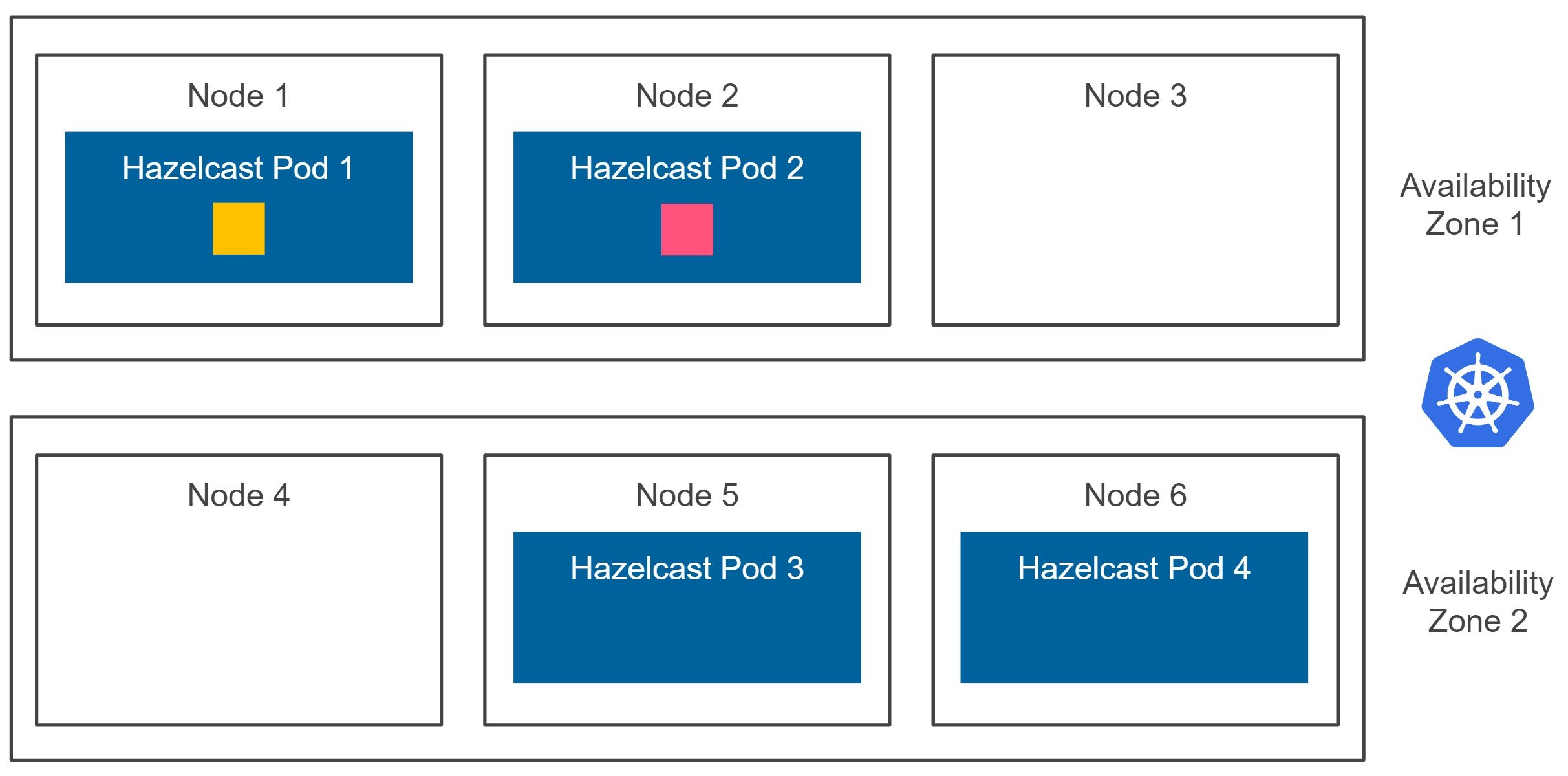
Kubernetes cluster can be deployed in one or many availability zones. Usually, for the production environments, we should avoid having just one single availability zone, because any zone failure would result in the downtime of our system. If you use Google Cloud Platform, then you can start a multi-zone Kubernetes cluster with one click (or one command). On AWS, you can easily install it with kops, and Azure offers multi-zone Kubernetes service as part of AKS (Azure Kubernetes Service). Now, when you look at the diagram above, what happens if the availability zone 1 is down? We experience data loss because both the data partition and the data partition backup and effectively stored inside the same zone.
Luckily, Hazelcast offers the ZONE_AWARE functionality, which forces Hazelcast members to store the given data partition backup inside a member located in a different availability zone. Having the ZONE_AWARE feature enabled, we end up with the following diagram.
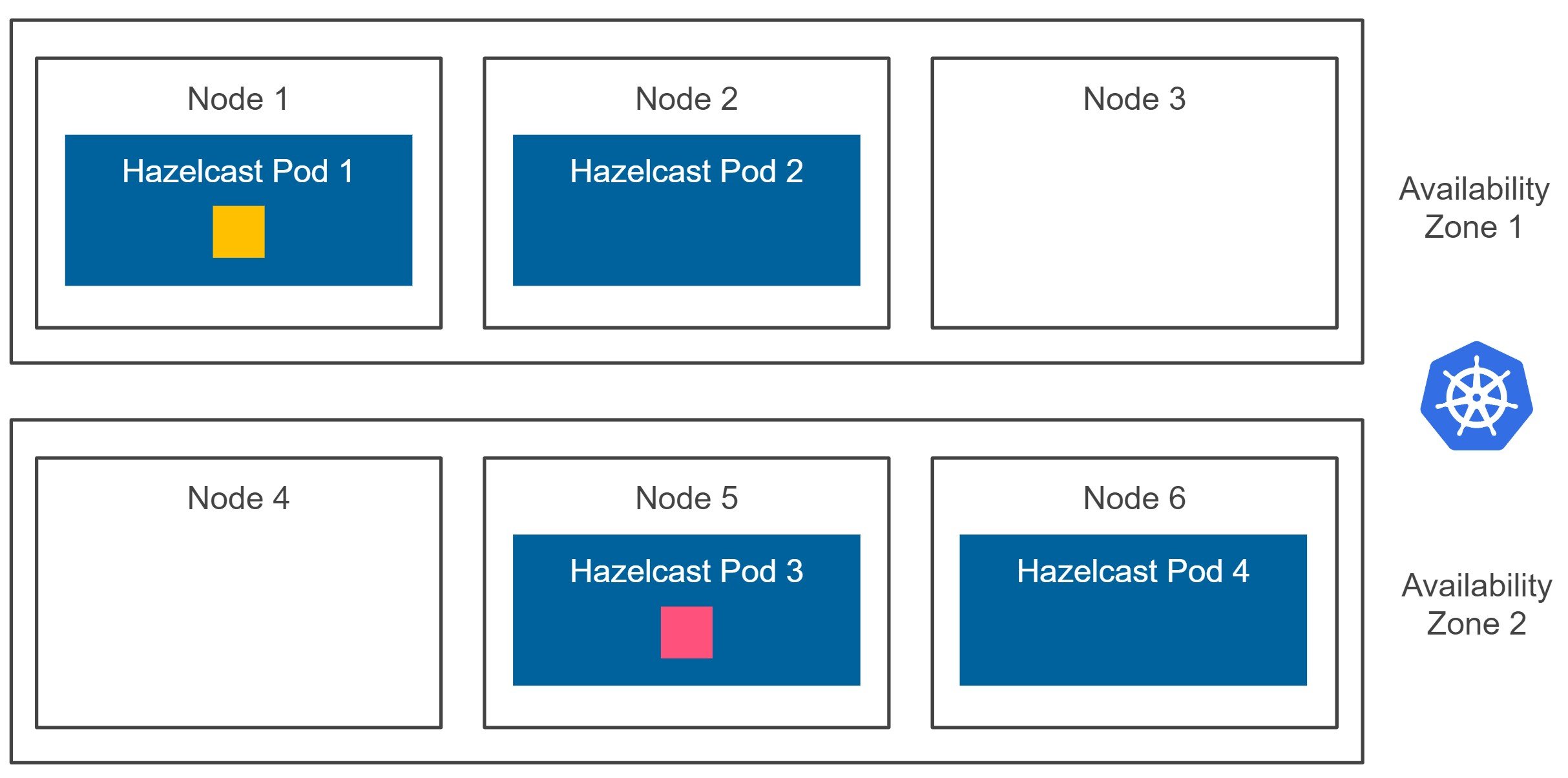
Let me stress it again. Hazelcast guarantees that the data partition backup is stored in a different availability zone. So, even if the whole Kubernetes availability zone is down (and all related Hazelcast members are terminated), we won’t experience any data loss. That is what should be called the real high availability on Kubernetes! And you should always configure Hazelcast in that manner. How to do it? Let’s now look into the configuration details.
Hazelcast ZONE_AWARE Kubernetes Configuration
One of the requirements for the Hazelcast ZONE_AWARE feature is to set an equal number of members in each availability zone. Starting from Kubernetes 1.16, you can achieve it by defining Pod Topology Spread Constraints. However, this feature is still in alpha and, what’s more, cloud platforms don’t offer Kubernetes 1.16 yet. That is why I’ll present how to achieve the same by running two separate Helm installations, each in a different availability zone. They’ll both point to the same Kubernetes service, and therefore, all pods will form one Hazelcast cluster.
First, you need to run a service that will be used for the Hazelcast cluster discovery.
$ kubectl apply -f - <<EOF apiVersion: v1 kind: Service metadata: name: hazelcast-service spec: type: ClusterIP selector: role: hazelcast ports: - protocol: TCP port: 5701 EOF
Then, you can start two Helm installations. Assuming your availability zones are named: us-central1-a and us-central1-b, the first command looks as follows. Note that the following command is for Helm version 2 (if you use Helm 3, you need to add a parameter --generate-name).
$ helm install hazelcast/hazelcast -f - <<EOF
hazelcast:
yaml:
hazelcast:
network:
join:
kubernetes:
service-name: hazelcast-service
partition-group:
enabled: true
group-type: ZONE_AWARE
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- us-central1-a
EOF
Let’s comment on the parameters we just used. It contains three interesting parts:
- using
hazelcast-servicefor discovery – otherwise, each Helm installation would use its service and therefore they would form two separate Hazelcast clusters - enabling
ZONE_AWARE - setting
nodeAffinity– forces all Hazelcast pods in this installation to be scheduled on the nodes in the zone availabilityus-central1-a
To run the second Helm chart installation, you should run the same command, this time with the zone us-central1-b. Then, you should see that all your members formed one Hazelcast cluster.
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
dandy-ladybird-hazelcast-0 1/1 Running 0 117s
dandy-ladybird-hazelcast-1 1/1 Running 0 77s
dandy-ladybird-hazelcast-2 1/1 Running 0 40s
romping-gibbon-hazelcast-0 1/1 Running 0 107s
romping-gibbon-hazelcast-1 1/1 Running 0 74s
romping-gibbon-hazelcast-2 1/1 Running 0 39s
$ kubectl logs dandy-ladybird-hazelcast-0
...
Members {size:6, ver:6} [
Member [10.32.1.8]:5701 - 55dc5090-38c7-48e4-821e-abe35e370a8e this
Member [10.32.4.4]:5701 - 11ba4bce-20ad-4af0-afef-f7670e44195d
Member [10.32.3.4]:5701 - 16ad5d0b-6b88-4d24-b46b-e3e200c54626
Member [10.32.2.6]:5701 - 56c87c59-f764-411a-8faf-d8618af3ed7c
Member [10.32.1.9]:5701 - 8d00bb07-39f2-4b6b-8dc8-fbb7ab13751e
Member [10.32.5.7]:5701 - 1212341a-d033-42b3-96c9-9c69ded9db94
]
...
What we just deployed is a Hazelcast cluster resilient to Kubernetes zone failures. Needless to add, if you want to have your cluster deployed on more zones, then you can run the next Helm installations. Note, however, that it won’t mean that if 2 zones fail at the same time, you don’t lose data. What Hazelcast guarantees is just that the data partition backup is stored in the member, which is always located in a different availability zone.
Hazelcast Cloud
Last but not least, Hazelcast multi-zone deployments will soon be available in the managed version of Hazelcast. You can check it at cloud.hazelcast.com. By ticking multiple zones in the web console, you can enable the multi-zone high availability level for the Hazelcast deployment. It’s no great secret that while implementing Hazelcast Cloud, internally, we used exactly the same strategy as described above.
Conclusion
In the cloud era, multi-zone high availability usually becomes a must. Zone failures happen and we’re no longer safe just by having our services on different machines. That is why any production-ready deployment of Kubernetes should be regional in scope, and not only zonal. The same applies to Hazelcast. Enabling ZONE_AWARE is highly recommended, especially because Hazelcast is often used as a stateful backbone for stateless services. If your Kubernetes cluster, however, is deployed only in one availability zone, then please at least make sure Hazelcast partition backups are always effectively placed on a different Kubernetes node. Otherwise, your system is not highly available at all and any machine failure may result in data loss.