
Queries and Aggregations w/ Scala, part 1
In this post we’ll take a look at the built-in aggregations in the Scala API.
I was looking at publicly available data sets to run some analysis on, and a good choice seemed the Chicago Crime statistics, a data set that includes all crime cases since 2001.
I chose the CSV download, which unfortunately is not compressed and exceeds 1 GB.
After (a lengthy) zip compression, the file became a slightly more managable 311 MB, which helps when copying around on the LAN.
The code
The CSV timestamps do not include timzeone information, so first up I defined the timezone needed for parsing, in the crime.chicago package:
package crime
import java.time.ZoneId
package object chicago {
val TimeZone = ZoneId.of("America/Chicago")
}
I then defined the class to hold each case. Since the dataset is a fairly large (6+ million cases), I kept only the fields that seemed interesting:
package crime.chicago import java.time.ZonedDateTime case class CrimeCase ( time: ZonedDateTime, block: String, primaryType: String, description: String, location: String, year: Short )
Parsing the CSV
For CSV parsing, I chose Apache Commons CSV, for no particular reason other than it seemed easy to get working:
package crime.chicago
import java.io.Reader
import java.time.ZonedDateTime
import java.time.format.DateTimeFormatter
import scala.collection.JavaConverters._
import org.apache.commons.csv.{CSVParser, CSVFormat}
object CrimeCSVParser {
// Timestamp parser function:
private val parseTime: (String => ZonedDateTime) = {
val timestampParser = DateTimeFormatter.ofPattern("MM/dd/yyyy h:m:s a").withZone(TimeZone)
str => ZonedDateTime from timestampParser.parse(str)
}
/**
* Parse through lazy transformation.
*/
def parse(reader: Reader): Iterator[(Int, CrimeCase)] = {
val parser = new CSVParser(reader, CSVFormat.DEFAULT)
val records = parser.iterator.asScala
val FieldNames = new Enumeration {
private[this] val header = records.next.iterator.asScala.toIndexedSeq
implicit def toId(fld: Value) = fld.id
val ID = Value(header.indexOf("ID"))
val Timestamp = Value(header.indexOf("Date"))
val Block = Value(header.indexOf("Block"))
val PrimaryType = Value(header.indexOf("Primary Type"))
val Description = Value(header.indexOf("Description"))
val LocationDescription = Value(header.indexOf("Location Description"))
val Year = Value(header.indexOf("Year"))
}
records.map { rec =>
import FieldNames._
val id = rec.get(ID).toInt
val cc = new CrimeCase(
time = parseTime(rec.get(Timestamp)),
block = rec.get(Block),
primaryType = rec.get(PrimaryType),
description = rec.get(Description),
location = rec.get(LocationDescription),
year = rec.get(Year).toShort)
(id, cc)
}
}
}
With most of the plumbing in place, I wrote the code for a single node:
package crime
import java.io.InputStreamReader
import java.util.zip.ZipFile
import scala.collection.JavaConverters._
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.duration._
import com.hazelcast.Scala._
import com.hazelcast.config.Config
import com.hazelcast.core.HazelcastInstance
import com.hazelcast.core.IMap
import com.hazelcast.logging.ILogger
object CrimeNode {
def main(args: Array[String]): Unit = {
val csvFile = args match {
case Array(filename) => new ZipFile(filename)
case _ =>
println("Please provide Chicago Crime zip filename")
return
}
val hz = newInstance()
implicit val logger = hz.getLoggingService.getLogger(getClass)
val crimeCases = getChicagoCrimes(hz)
populateMap(hz, crimeCases, csvFile)
logger.info("Ready!")
}
def populateMap(
hz: HazelcastInstance,
chicagoCrimeCases: IMap[Int, chicago.CrimeCase],
csvFile: ZipFile)(implicit logger: ILogger): Unit = {
val zipEntry = csvFile.entries().nextElement()
val zipInput = csvFile.getInputStream(zipEntry)
val crimeReader = new InputStreamReader(zipInput)
try {
val asyncMap = chicagoCrimeCases.async
val allCases = chicago.CrimeCSVParser.parse(crimeReader)
val finalCount = allCases.foldLeft(0) {
case (lastCount, (id, crimeCase)) =>
if (lastCount == 0) logger.info(s"Now processing ${csvFile.getName}")
asyncMap.set(id, crimeCase).failed.foreach { e =>
logger.warning(s"Failed to insert case $id", e)
}
val thisCount = lastCount + 1
if (thisCount % 25000 == 0) logger.info(f"processed $thisCount%,d records")
thisCount
}
logger.info(f"Done parsing CSV, total $finalCount%,d processed")
} finally {
crimeReader.close()
}
}
def getChicagoCrimes(hz: HazelcastInstance) = hz.getMap[Int, chicago.CrimeCase]("chicago-crimes")
private def newInstance(): HazelcastInstance = {
val conf = new Config
conf.getGroupConfig.setName("crime-cluster")
serialization.Defaults.register(conf.getSerializationConfig)
serialization.DynamicExecution.register(conf.getSerializationConfig)
conf.newInstance
}
}
Let’s quickly go through what happens here. The main method expects the zip file as argument, which it will then proceed to parse and add to the IMap (using set). For every 25,000 record, it will log progress. In the newInstance() method, we configure and return a HazelcastInstance, which simply is named and have the Defaults serializers added, as well as the DynamicExecution, which will allow us to run ad hoc queries without pre-compiling and restarting.
Running a single node
We can compile this to a JAR or simply run against the IDE classpath:
java -Xmx12G -cp $CP crime.CrimeNode ./Crimes_-_2001_to_present.zip
On my laptop, it takes slightly less than 2 minutes to parse the file.
Connecting a client
With that done, I then connected a client, through the Scala REPL (outlined here), so I can run ad hoc queries. Make sure the classpath includes all dependencies.
First, let’s setup the imports:
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_74). Type in expressions for evaluation. Or try :help. scala> :paste // Entering paste mode (ctrl-D to finish) import com.hazelcast.Scala._, client._ import com.hazelcast.client.config._ import concurrent._, duration._, ExecutionContext.Implicits.global // Exiting paste mode, now interpreting. import com.hazelcast.Scala._ import client._ import com.hazelcast.client.config._ import concurrent._ import duration._ import ExecutionContext.Implicits.global scala>
Now, let’s configure and connect the client:
scala> :paste
// Entering paste mode (ctrl-D to finish)
val conf = new ClientConfig
conf.getGroupConfig.setName("crime-cluster")
conf.getNetworkConfig.addAddress("localhost")
serialization.Defaults.register(conf.getSerializationConfig)
serialization.DynamicExecution.register(conf.getSerializationConfig)
val hz = conf.newClient
// Exiting paste mode, now interpreting.
Jun 16, 2016 11:32:49 AM com.hazelcast.core.LifecycleService
INFO: HazelcastClient[hz.client_0_crime-cluster][3.6.2] is STARTING
Jun 16, 2016 11:32:50 AM com.hazelcast.core.LifecycleService
INFO: HazelcastClient[hz.client_0_crime-cluster][3.6.2] is STARTED
Jun 16, 2016 11:32:50 AM com.hazelcast.client.spi.impl.ClientMembershipListener
INFO:
Members [1] {
Member [192.168.1.7]:5701
}
Jun 16, 2016 11:32:50 AM com.hazelcast.core.LifecycleService
INFO: HazelcastClient[hz.client_0_crime-cluster][3.6.2] is CLIENT_CONNECTED
conf: com.hazelcast.client.config.ClientConfig = com.hazelcast.client.config.ClientConfig@30839e44
hz: com.hazelcast.core.HazelcastInstance = com.hazelcast.client.impl.HazelcastClientInstanceImpl@5f174dd2
Client connected to the single node, and then it’s down to business.
The query and aggregation
First, get the crime case IMap using the helper method:
scala> val crimeCases = crime.CrimeNode.getChicagoCrimes(hz)
crimeCases: com.hazelcast.core.IMap[Int,crime.chicago.CrimeCase] = IMap{name='chicago-crimes'}
Then, filter out 2016, since it’s incomplete.
scala> val crimesEntries2001_2015 = crimeCases.filter(where("year") < 2016)
crimes2001_2015: com.hazelcast.Scala.dds.DDS[java.util.Map.Entry[Int,crime.chicago.CrimeCase]] = com.hazelcast.Scala.dds.MapDDS@405495e7
Notice, this returns a DDS, a Distributed Data Structure, a lazily evaluated collection type. Its content is java.util.Entry, because that’s what the IMap contains. However, we’re not interested in the full Entry, only the CrimeCase value, so let’s map:
scala> val crimes2001_2015 = crimesEntries2001_2015.map(_.value) crimes2001_2015: com.hazelcast.Scala.dds.DDS[crime.chicago.CrimeCase] = com.hazelcast.Scala.dds.MapDDS@5ceca60
I wanted to look at the number of crimes, per year, per type, so let’s group the cases by that:
scala> val casesByTypeAndYear = crimes2001_2015.groupBy(cc => cc.primaryType -> cc.year) casesByTypeAndYear: com.hazelcast.Scala.dds.GroupDDS[(String, Short),crime.chicago.CrimeCase] = com.hazelcast.Scala.dds.MapGroupDDS@429b336b
So far, nothing has executed, we’re simply staging the map for the eventual aggregation.
With the cases grouped, we’re ready to execute the count. However, I wanted to time this, so let’s write a quick timing function:
scala> :paste
// Entering paste mode (ctrl-D to finish)
def timeThis[T](thunk: => Future[T]): (T, Duration) = {
val start = System.currentTimeMillis
val result = Await.result(thunk, 10.minutes)
result -> (System.currentTimeMillis - start).milliseconds
}
// Exiting paste mode, now interpreting.
timeThis: [T](thunk: => scala.concurrent.Future[T])(T, scala.concurrent.duration.Duration)
It’s never a good idea to block forever, so I used a 10 minute timout. Don’t worry, it shouldn’t take that long.
Ok, let’s execute, and time, the built-in count() aggregation, which will execute on the cluster node, not the client:
scala> val (countByTypeAndYear, execTime) = timeThis { casesByTypeAndYear.count() }
Zzzzzzz…..
scala> val (countByTypeAndYear, execTime) = timeThis { casesByTypeAndYear.count() }
countByTypeAndYear: scala.collection.Map[(String, Short),Int] = Map((STALKING,2009) -> 167, (MOTOR VEHICLE THEFT,2014) -> 9902, (THEFT,2015) -> 57219, (OBSCENITY,2014) -> 36, (WEAPONS VIOLATION,2008) -> 3877, (CRIMINAL TRESPASS,2008) -> 12310, (STALKING,2008) -> 190, (KIDNAPPING,2009) -> 293, (OBSCENITY,2006) -> 17, (HOMICIDE,2007) -> 448, (BATTERY,2005) -> 83964, (MOTOR VEHICLE THEFT,2008) -> 18881, (BATTERY,2010) -> 65400, (PUBLIC INDECENCY,2015) -> 14, (BURGLARY,2002) -> 25623, (WEAPONS VIOLATION,2004) -> 4297, (ASSAULT,2002) -> 31521, (INTERFERENCE WITH PUBLIC OFFICER,2005) -> 615, (DECEPTIVE PRACTICE,2010) -> 12377, (OFFENSE INVOLVING CHILDREN,2007) -> 2854, (OFFENSE INVOLVING CHILDREN,2015) -> 2193, (HUMAN TRAFFICKING,2013) -> 2, (OTHER OFFENSE,2009) -> 25601, (NON-CRIMINAL,2012) ...
scala> println(s"Took ${execTime.toSeconds} secs")
Took 155 secs
Ok, so crunching the data took a little over 2 minutes on my laptop, with 12G allocated heap.
Now that we have the data locally, let’s find the top 10 crimes across all years:
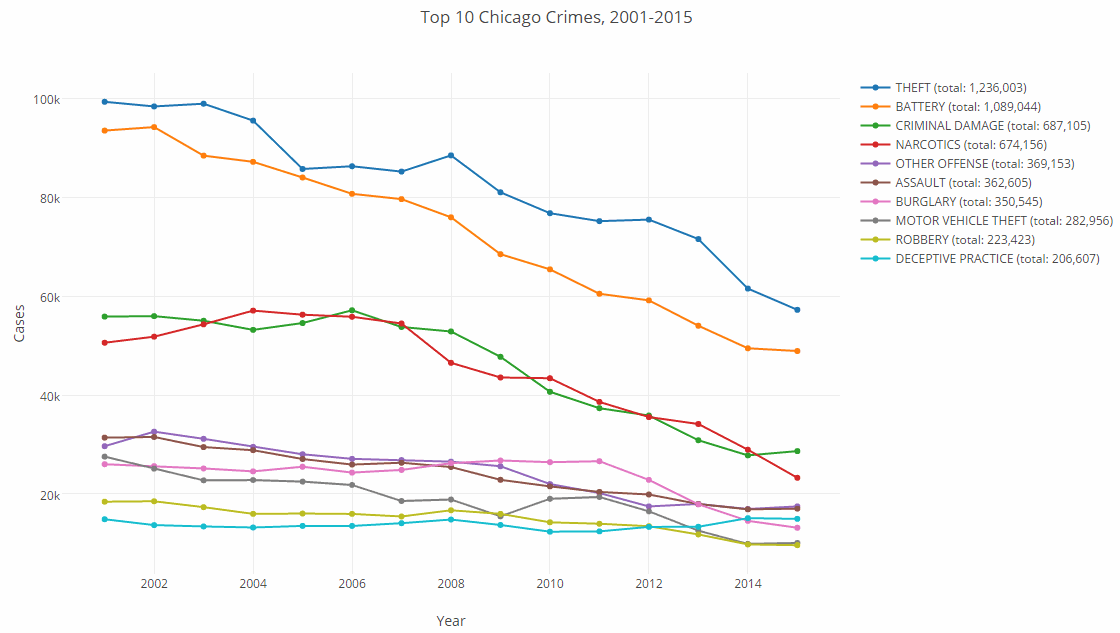
scala> val countByType = countByTypeAndYear.groupBy(_._1._1).mapValues(_.values.sum) countByType: scala.collection.immutable.Map[String,Int] = Map(CRIMINAL TRESPASS -> 174206, OFFENSE INVOLVING CHILDREN -> 38309, NARCOTICS -> 674156, RITUALISM -> 23, INTIMIDATION -> 3505, OBSCENITY -> 358, MOTOR VEHICLE THEFT -> 282956, GAMBLING -> 13846, OTHER OFFENSE -> 369153, HOMICIDE -> 7449, NON-CRIMINAL (SUBJECT SPECIFIED) -> 3, SEX OFFENSE -> 21932, NON - CRIMINAL -> 33, PUBLIC INDECENCY -> 130, HUMAN TRAFFICKING -> 17, INTERFERENCE WITH PUBLIC OFFICER -> 11967, ROBBERY -> 223423, DECEPTIVE PRACTICE -> 206607, CRIMINAL DAMAGE -> 687105, ARSON -> 9873, CRIM SEXUAL ASSAULT -> 22231, THEFT -> 1236003, CONCEALED CARRY LICENSE VIOLATION -> 49, PUBLIC PEACE VIOLATION -> 43504, NON-CRIMINAL -> 42, KIDNAPPING -> 6127, OTHER NARCOTIC VIOLATION -> 108, BATTERY -> 1089044, DOMESTIC VIOLENC... scala> val top10 = countByType.toSeq.sortBy(_._2).reverse.take(10) top10: Seq[(String, Int)] = ArrayBuffer((THEFT,1236003), (BATTERY,1089044), (CRIMINAL DAMAGE,687105), (NARCOTICS,674156), (OTHER OFFENSE,369153), (ASSAULT,362605), (BURGLARY,350545), (MOTOR VEHICLE THEFT,282956), (ROBBERY,223423), (DECEPTIVE PRACTICE,206607))
Using this top 10, we can filter the data set:
scala> val top10Types = top10.map(_._1).toSet top10Types: scala.collection.immutable.Set[String] = Set(NARCOTICS, MOTOR VEHICLE THEFT, OTHER OFFENSE, ROBBERY, DECEPTIVE PRACTICE, CRIMINAL DAMAGE, THEFT, BATTERY, BURGLARY, ASSAULT) scala> val top10CountByTypeAndYear = countByTypeAndYear.filter(t => top10Types.contains(t._1._1)) top10CountByTypeAndYear: scala.collection.Map[(String, Short),Int] = Map((BURGLARY,2003) -> 25156, (MOTOR VEHICLE THEFT,2014) -> 9902, (THEFT,2015) -> 57219, (BATTERY,2012) -> 59132, (NARCOTICS,2001) -> 50567, (OTHER OFFENSE,2014) -> 16958, (ASSAULT,2010) -> 21535, (ROBBERY,2001) -> 18441, (BATTERY,2013) -> 54002, (THEFT,2008) -> 88430, (NARCOTICS,2009) -> 43543, (CRIMINAL DAMAGE,2012) -> 35852, (BATTERY,2005) -> 83964, (ROBBERY,2002) -> 18522, (MOTOR VEHICLE THEFT,2008) -> 18881, (BURGLARY,2012) -> 22844, (OTHER OFFENSE,2006) -> 27099, (DECEPTIVE PRACTICE,2001) -> 14890, (CRIMINAL DAMAGE,2005) -> 54548, (BATTERY,2010) -> 65400, (CRIMINAL DAMAGE,2009) -> 47724, (THEFT,2005) -> 85685, (OTHER OFFENSE,2015) -> 17484, (BURGLARY,2002) -> 25623, (THEFT,2006) -> 86238, (OTHER OFFENSE,2005) -> ...
And then plot it out:
Conclusion
Ok, so there you have it. Very easy to crunch data in Hazelcast, and crime in Chicago is down too, so what’s not to like?
Well, but wait… more than 2 minutes to crunch that?? Come on, what is this, 1946?
Don’t worry, in part 2 we’ll be taking a look at how to make this perform better, much better.