
Performance Top 5 #2 Serialization options
This is the second of five blogposts how to improve performance in Hazelcast applications. When accessing data in Hazelcast, e.g. a distributed IMap, the data needs to be serialized to be transferred over the line. To deal with serialization, Hazelcast supports various serialization options. The most basic serialization option is the java.io.Serializable. Unfortunately, java.io.Serializable is not always the best choice: 1. There is quite some CPU cost. 2. It doesn’t lead to the smallest byte-content. 3. It doesn’t always result in the same byte-content, e.g. HashMap. This can be an issue with methods like the IMap.replace method, that rely on the byte-content. Hazelcast supports a whole suite of different serialization implementations and for this blogpost that I’ll discuss:
- Serializable
- DataSerializable
- IdentifiedDataSerializable.
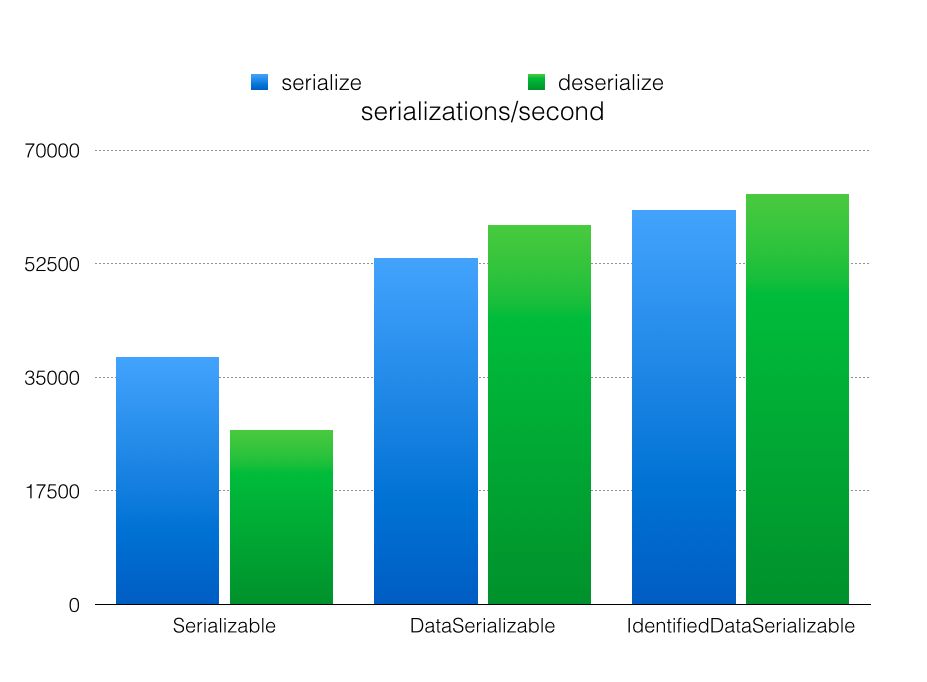
The main difference between the last 2 is that the DataSerializable includes the classname in the byte-content and the IdentifiedDataSerializable just an id, so the latter produces a smaller byte-content. For this blogpost we are not going to look at the size of the byte-content; but just as the throughput of operations. To measure the differences, I’m going to create orders with an arbitrary number of order-lines and (de)serialize them using these 3 different serialization techniques. The orders are put in a default configured IMap, so a single synchronous backup, but the tracking of statistics is disabled. All the tests make use of the IMap.set method. The sources for this blogpost can be found here Let’s get started with the JMH results. For the JMH test I’m making use a single member cluster. This means that there are no backups and we can do a fair comparison between serialization and deserialization. There are a few things we can conclude: 1. Deserializing java.io.Serializable is slower than serializing. With the DataSerializable and IdentifiedDataSeriable deserialization is faster than serialization. 2. DataSerializable is faster than Serializable. 3. IdentifiedDataSerializable is marginally faster than DataSerializable.
So apparently sending an id (int) instead of sending a String (classname) doesn’t make a big difference. The problem with JMH is that it will only benchmark in a local setup, but how does this behave in a real environment? That is why I also have included Stabilizer tests. Staiblizer is a tool we use internally to stress tests our Hazelcast systems. It has some very rudimentary performance tracking capability and has out of the box profiling support for hprof and for Yourkit and in the coming months we’ll add support for Intel VTune. With Stabilizer you can create ‘JUnit’ like tests that are automatically uploaded to a group of machines where they are executed. It is also possible to start/stop machines in a cloud, e.g. Amazon EC2 or Google Compute Engine. But it can just as easily be used in a static environment; cloud environments are very unreliable for performance testing and it is very easy to start ghost hunting because of inconsistent performance results. For this blogpost I’m making use of a 4 machines with dual socket 6 core (12 because of hyper-threading) Sandy Bridge Xeon machine, 32 Gigabytes of memory on each machine and Gigabit network. Below you can see the results of the Stabilizer tests for the different serialization mechanisms.
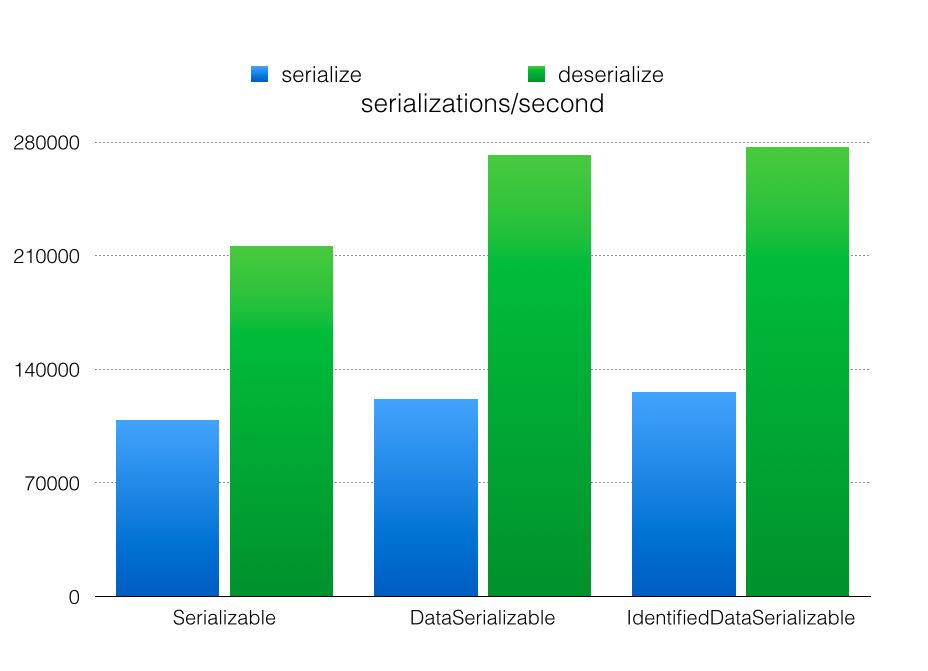 There are a few things we can conclude: 1. For serializing (map.set) it doesn’t really matter which serialization technique is selected. The reason is that the overhead of creating a backup outweighs the serialization performance differences. 2. DataSerializable is significantly faster than Serializable for deserializing. 3. IdentifiedDataSerializable is only marginally faster than IdentifiedDataSerializable. The last 2 conclusions are the same as with JMH. So apparently the amount of data being send, doesn’t influence serialization that much. This is also backed up by other tests; currently the way interact with the network probably is the most determining factor for performance.
There are a few things we can conclude: 1. For serializing (map.set) it doesn’t really matter which serialization technique is selected. The reason is that the overhead of creating a backup outweighs the serialization performance differences. 2. DataSerializable is significantly faster than Serializable for deserializing. 3. IdentifiedDataSerializable is only marginally faster than IdentifiedDataSerializable. The last 2 conclusions are the same as with JMH. So apparently the amount of data being send, doesn’t influence serialization that much. This is also backed up by other tests; currently the way interact with the network probably is the most determining factor for performance.