
Performance Top 5 #1 Map.put vs Map.set
This is the first in a series of 5 blogposts about how to speed up Hazelcast applications. Some modifications are a bit more work and some are minor. Each of the blogpost will be backed up by a JMH benchmark to verify the performance improvement. All the benchmarks for this blog-series can be found in our repository on GitHub. So lets get started.
The Hazelcast IMap extends the put interface and therefore implements the Map.put(key,value) method. The problem with this method is it returns the old value even though in most cases this old value is not used. For regular in memory data-structures like a HashMap or a ConcurrentHashMap this isn’t a big problem. But in a distributed environment things are a bit more complicated.
It could be that the old value is stored on a different machine and needs to be send over the wire and this causes overhead. Apart the network overhead, the deserialization of the old value also causes overhead. That is why the IMap supports an additional method called set with similar semantics as the put, but instead of returning the old value, void is returned and therefore is not suffering from the performance penalty of returning the old value. So lets see how big the performance impact is.
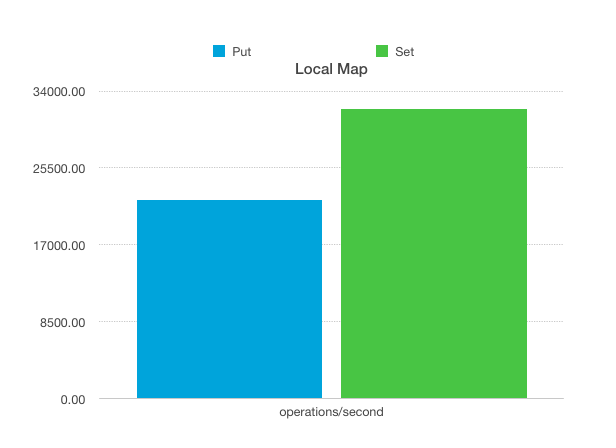
I created 2 benchmarks: 1. a local benchmark without any networking 2. a ‘distributed’ benchmark with 5 Hazelcast instances communicating over the loopback device. Each benchmark contains a map, with a binary in memory format, with 50k items. Integers are used as key and a String of length 500 as value. All keys/values have been created up front to remove garbage collection out of the equation. Also backups and statistics have been disabled, but you can easily enable them and see what the performance impact is. The test machine is a dual socket Nehalem machine, 12 gigs of ram, running Debian 7 and Oracle Java 1.7.0_51 64 bits with default JVM settings. Below you can see the results of the local benchmark:
The performance of the set is roughly 45% faster because the set doesn’t need to deserialize. In the future the performance of the put will probably increase once we add an optimization for local calls returning immutable data.
In the current setup the map is configured with ‘binary’ in-memory-format, meaning that if the value is return, it needs to be deserialized. In the future, when the ‘object’ in-memory-format is selected, local calls can directly return the stored object as long as the object is recognized to be immutable. For the distributed one we also see a performance improvement: 
Here the set is roughly 35% faster than than the put. As you can see, with a minor programming change, we can achieve a nice performance improvement.
In the next Hazelcast Community editions we’ll be spending most of our time on quality, scalability and stability. So you can expect that the performance numbers are going to improve significantly. If you’re interested in performance you may also want to download the Quantschool benchmarks, an independent third-party benchmark for testing Hazelcast and other NoSQL and Data Grid solutions.