
By Greg Luck
Chief Technical Officer
Greg Luck is a leading technology entrepreneur with more than 15 years of experience in high-performance in-memory computing. He is the founder and inventor of Ehcache, a widely used open source Java distributed cache that was acquired by Software AG (Terracotta) in 2009, where he served as CTO. Prior to that, Greg was the Chief Architect at Australian start-up Wotif.com that went public on the Australian Stock Exchange (ASX:WTF) in 2006. Greg is a current member of the Java Community Process (JCP) Executive Committee, and since 2007 has been the Specification Lead for JSR 107 (Java Specification Requests) JCACHE. Greg has a master's degree in Information Technology from Queensland University of Technology and a Bachelor of Commerce from the University of Queensland.
View all blogs by the authorOct 7, 2017
Jepsen Analysis on Hazelcast 3.8.3
Update: June 10, 2020
Updated a number of the links as content and documentation have changed.
Update: March 6, 2019
Hazelcast 3.12 introduced a new CP Subsystem based on an In-Memory RAFT for the atomic data structures discussed in this blog. This is an ideal solution recommended by Kyle Kingsbury which we have now implemented. See Hazelcast IMDG 3.12 Introduces CP Subsystem.
Jepsen Analysis
Kyle Kingsbury (aka @aphyr) has prepared an analysis of Hazelcast IMDG 3.8.3 using his Jepsen tool, as he has many other distributed systems over the last four years. We are the first in-memory data grid (IMDG) to be analysed. Jepsen tests for linearizability under normal and also abnormal conditions such as failed nodes and network partitions. We also use the Jepsen tool ourselves in order to understand the behaviour of our system under different conditions.
To oversimplify, the main conclusion from the Jepsen report is that, during a network partition, Hazelcast favours availability over consistency. i.e. Hazelcast does not exhibit linearizability in those circumstances.
Hazelcast and the PACELC Theorem
A useful way of thinking about distributed systems is the PACELC Theorem, an extension to the CAP Theorem that focuses on the behaviour of distributed systems in two modes: one when there is a network partition, the PAC part, and second, where there is no network partition, the normal case, which is the ELC part.
Before going into that let’s go into how common network partitions are. Hazelcast clusters are deployed on LANs. We do not support deployment of a single cluster over a WAN. Datacenter, network and hardware engineers strive for reliability through redundancy of hardware systems. So they are rare but possible, and need to be considered in the design of a distributed system.
Hazelcast is a PA/EC system, which may be also be tuned in some cases to be PA/EL.
What this means is that when there is no network partition, we favour consistency over latency, but may be tuned to favour latency over consistency. When there is a network partition we favour availability over consistency. Which is what the Jepsen test shows.
This is, and has always been, Hazelcast’s PACELC contract. It is also the PACELC contract of the entire category of IMDG systems. IMDGs are used for maximum speed and low latency. They represent a set of design trade-offs to achieve this primary purpose.
Professor Daniel Abadi has published a research article on Hazelcast from a PACELC perspective which goes deeply into this topic.
In-Memory Data Grids
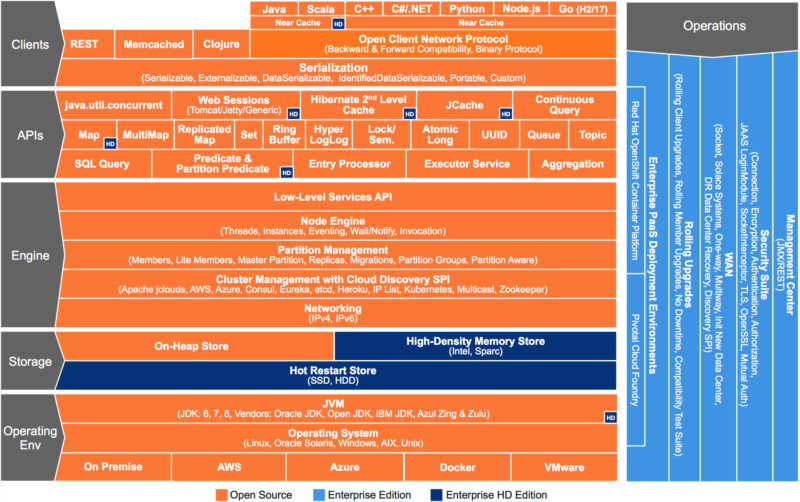
In-Memory Data Grids are a category of distributed systems, mostly Java based, which have elastic clusters of nodes to hold and process data. The most common use case by far is caching with our IMap and JCache APIs. But we also have distributed messaging, computation, and a Swiss Army Knife of clustering primitives, mostly taken from java.util.concurrent. See the following diagram which shows all the APIs.
Explicit Programmer Guidance
Programming contracts need to be explicit. Hazelcast is a 9 year old open source project. Over time the documentation has become more complete, both the reference manual and the JavaDoc. For example, in Hazelcast IMDG 3.0 the reference manual was 93 pages. As of 3.9 it is 501 pages. In 3.9 we formalised our description of our consistency behaviour in both our reference manual and our JavaDoc.
Relevant Reference Manual Chapters
The Hazelcast documentation explicitly and clearly describes how we work. The following two chapters are the most relevant.
- A Brief Overview of Consistency & Replication in Distributed Systems
- Network Partitions, Split Brain and Split Brain Protection
Network Partition Behaviour
As we said, Hazelcast is a PA system, meaning, in a network partition, we favour availability over consistency. Our design allows us to be faster in the normal situation where there is no network partition.
A network partition between nodes of an In-Memory Data Grid is called a “split brain”. The partition causes two or more clusters to form, when before there was one. Writes to one of the new clusters do not propagate to the other clusters. The data can therefore become inconsistent.
Whether inconsistency is a problem and how big a problem depends on the use case, the data structure, the time duration that the inconsistency is allowed to continue and whether there are mitigations in the application that can be taken after an inconsistency occurs.
Split Brain Protection
Split Brain Protection seeks to reduce the time the inconsistency persists. We set a minimum number of nodes which must be present for a write and/or a read to happen. For example, in a 10 node cluster, you set the minimum number to 6. If a split brain happens any sub-clusters smaller than 6 nodes are prevented from accepting writes and/or reads, depending on configuration. This is by Distributed Object so the tunings can be different. Today we support the Distributed Objects:
- Map (for Hazelcast IMDG 3.5 and higher versions)
- Transactional Map (for Hazelcast IMDG 3.5 and higher versions)
- Cache (for Hazelcast IMDG 3.5 and higher versions)
- Lock (for Hazelcast IMDG 3.8 and higher versions)
- Queue (for Hazelcast IMDG 3.8 and higher versions)
Split Brain Protection has proven to be useful. We are planning to extend it to all Distributed Object Types in 3.10 and 3.9.1.
We reduce the time but do not eliminate it. There is a time window between a partition occurring and our Split Brain Protection occurring. This is in the order of tens of seconds in 3.9 but will be reduced further in 3.10/3.9.1 with our new ICMP based cluster membership system.
Split Brain Healing
When the network partition is over, the sub-clusters re-establish communication and return to being one cluster. Data in the largest cluster is retained and the smaller cluster’s data is discarded.
For our two most common use cases, JCache and IMap, by default, we merge data from the smaller sub-clusters to the larger, using a put if absent policy. A programmer can also specify another policy or write their own. See Merge Policies.
We will be extending merging on healing across most Distributed Object types in 3.10/3.9.1.
Planned Improvements in 3.10/3.9.1
- Extend Split Brain Protection to all Distributed Object Types (3.9.1/3.10)
- Add a new CRDT Counter type, which will be more appropriate to use than AtomicLong for counters (3.10)
- Extend merge policies to more Distributed Object Types (3.10)
Some Specific Comments on Points Raised in the Discussion
Cluster Failed Node Detection Time
The report mentions a 300 second timeout. We recently did some optimisations in this area and have reduced it to 60 seconds in 3.9. This is an intentionally conservative default which can be lowered in many cases. In 3.9 we introduce the Phi Accrual Detector in addition to our Deadline Detector. It uses hypotheses testing and adapts to network conditions. With this detector a timeout of 10 seconds is reliable.
In 3.10/3.9.1 we will also introduce an ICMP Detector, at OSI Layer 3, which will run in parallel with the existing Layer 7 detectors. This will bring the default detection of network or host based partitions down to 3 seconds i.e. 3 ICMP ping misses.
Appropriate Warnings
We agree making the contract explicit, with warnings on what can happen to the JavaDoc, is important. We have been adding these over the last few weeks in time for the 3.9 release which is expected at the end of October.
See the JavaDoc for:
- ICache, our JCache implementation
- IAtomicLong
- IAtomicReference
- ICountDownLatch
- ILock
- IMap
- ISemaphore
- IdGenerator
We will extend our coverage further in 3.10. See the Roadmap later in this blog.
Appropriate Use of Primitives
While the PA behaviour + Split Brain Protection of Hazelcast during a split brain is usually useful for caching use cases, it may be less so for the primitives.
For ILock, the lock is not mutually exclusive under split brain. However it can still be useful as an advisory lock.
AtomicLong will diverge in a split brain. On heal, the one that was in the largest cluster will be used. So it depends on what the long is being used for. If used as a counter, the counters would diverge, and then one counter would be used but would be missing counts. Whether this practically matters depends on the application. For applications where the counter must return to a correct value, we plan to introduce a CRDT Counter in 3.10.
For IdGenerator, you could get duplicates in a split brain. For this reason we like the idea of using Flake Ids and we plan to introduce it to 3.10.
IQueue and ITopic do not honour the exactly once guarantee if a split brain has occurred. Once again, whether this is Ok depends on the application. They can be considered lossy queueing systems, which have their uses, but which should be more clearly documented.
3.10 Roadmap
We plan to improve Hazelcast’s in things relevant to this blog post. Here is a summary of features planned for 3.10, by category. We expect 3.10 to be released by the end of 2017.
Improving Guidance
Document Failure Conditions – Fully document failure conditions for each data type covering items such as: split brain, async backup, master node failure before backup complete Use Case Guidance – For each data structure, document the recommended use cases, and warn against those that are not suitable and why. Explain clearly with reference to failure conditions.
Improving Detection of Split Brains
ICMP Ping Failure Detector – Layer 3 detector to run alongside Layer 7 and provide much more determinism for hardware and OS related events. Will bring down the detection window down from tens of seconds to possibly as low as 3 seconds for hardware and OS based problems
Preventing or Limiting Divergence
Extend Hazelcast Split-Brain Protection – Will extend our protection which kicks in after detection. Either reads or writes will be blocked to any Distributed Object, if configured. This limits the amount of time inconsistent reads or writes can be made.
ID Generator backed by Flake IDs – Gives unique, non-duplicative IDs without coordination other than a round of coordination on initialisation.
Reconciling After Divergence
Merge Policies for Additional Data Structures – Add merge policies for all data types on slit brain heal. Most will be user configurable.
Distributed Object auto creation by data type – so that if a sub-cluster creates a Distributed Object it can be merged on split brain heal.
CRDT PN Counter – Each node will be able to increment and decrement the counter value and those updates will be propagated to everyone in the background. On Split Brain Heal, the system will guarantee that everyone will see the final value of the counter eventually and the history of the counter value will be monotonic. Can be used as an alternative to IAtomicLong.
CRDT OR-Set – Observed-Removed Set. Allows multiple adds and removes. Can be used as an alternative to ISet.
Conclusion
Hazelcast is a PA/EC system which we believe is the case for all In-Memory Data Grids (to be confirmed by Jepsen testing). To pass the Jepsen test we would need to be PC/EC. Why are IMDGs PA? Generally, to be PC across all Distributed Object Types we would need a consensus protocol such as Raft or Paxos. These require more network calls and coordination and are hence slower.
IMDGs are used for maximum speed and low latency. They represent a set of design trade-offs to achieve this primary purpose.
There are a multitude of other systems with different design goals that can be used if PC is of primary importance.
Revision History
6 October 2017 – Initial Draft
7 October – Grammar and re-emphasis on the design goals of IMDGs
8 October – Add 3.10 Roadmap. Add reference to Professor Daniel Abadi PACELC analysis.
6 March 2019 – Add information about atomics on our new CP subsystem.