
Software Engineer
Metin is a Software Engineer working on the Clients Team. Since joining Hazelcast as an intern, he has been working on various clients such as Python, Node.js, and Java.
View all blogs by the authorJan 19, 2021
Hazelcast Python Client 4.0 is Released
![]()
We are happy to announce that the Hazelcast Python Client 4.0 is released!
You can install the latest version through PyPI by issuing the following command.
pip install hazelcast-python-client
Let’s dive into the highlights of this release!
Hazelcast Client Protocol 2.0
Python client now uses Hazelcast Open Binary Protocol 2.0, which features numerous enhancements over the 1.x version, to communicate with the Hazelcast cluster. Although the protocol layer is invisible to the end-user, this change has an important implication. The client is now able to work with IMDG 4.x clusters. However, the 4.x client won’t be able to work with IMDG 3.x clusters anymore. We will be releasing 3.12.x client versions regularly for the people using IMDG 3.x.
Performance
We optimized the hot-path of the client by eliminating unnecessary buffer copies, simplifying the operations we did, and changing how some internal components work.
More importantly, we re-architected how we write messages to the wire which resulted in almost 2x throughput improvements for the non-blocking use cases and gave us opportunities to improve it more. As promised in the 4.0 Beta release announcement blog post, we have implemented automatically coalescing multiple client messages to reduce the number of send system calls we do. This change resulted in a 10% throughput increase in balanced workloads for non-blocking use cases.
Another important change happened in how we serialize strings. In the 3.x version of the client, we were doing a non-standard UTF-8 serialization due to how strings are represented in the IMDG itself. This non-standard serialization is replaced with the standard UTF-8 serialization in the IMDG 4.x and that enabled us to change the way we do string serialization in the Python client. We are now using the encode method that comes with the standard library. So, if you were using strings as your keys, values, or items for our distributed data structures, you will see pretty significant performance improvements without changing any code!
Client on Kubernetes
In an effort to verify that every Hazelcast client works on Kubernetes environments, our Integration Team team conducted some tests using the 4.0 version of the Python client. Thanks to those efforts, we have found critical bugs in the client which sometimes leaves it in an unusable state after scaling up and down the Hazelcast cluster or restarting the cluster pods. We have fixed those bugs and verified that the client works correctly in the scenarios above. After that, we have added the Python client to our Kubernetes guide. Check that out and try the new client with IMDG clusters running on Kubernetes!
CP Subsystem Support
The concurrency primitives offered in the 3.x version of the Python client were AP in terms of the CAP principle. This means that IMDG was handling server, client, and network failures gracefully to maintain availability but it was not able to guarantee consistency in every failure scenario. We believe that consistency is a fundamental requirement for such primitives and developed the CP Subsystem.
In this release of the Python client, concurrency primitives moved to the CP Subsystem which guarantees consistency provided by the implementation of the Raft consensus algorithm. As the name implies, these primitives are now CP concerning the CAP principle and they live alongside the AP data structures in the same Hazelcast IMDG cluster. They maintain linearizability in all cases, including client and server failures, network partitions, and prevent split-brain situations.
Hazelcast Python client supports all concurrency primitives available in the CP Subsystem, namely, AtomicLong, AtomicReference, FencedLock, Semaphore, and CountDownLatch.
Sample usage of the FencedLock is provided below.
# Get a FencedLock called "my-lock" lock = client.cp_subsystem.get_lock("my-lock").blocking() # Acquire the lock and get a fencing token fence = lock.lock() try: # Your guarded code goes here ... finally: # Make sure to release the lock lock.unlock()
Boomerang Backups
The data stored in the Hazelcast IMDG cluster is resilient to node failures since the IMDG maintains backups across the cluster. When a client performs a write operation, the change must be reflected in the backups.
In Hazelcast IMDG 3.x, when the sync backups are enabled (which is enabled by default) the primary node was issuing backup operations to the replica nodes, waiting for their responses, and then sending the response back to the client. This architecture requires 4 network hops to complete write operations sent by the client.
In IMDG 4.x, we wanted to improve the out-of-the-box write performance and implemented what we call Boomerang Backups. In the new architecture, replica nodes send backup acknowledgments directly to the client and eliminate a network hop. With this change, write operations sent by the client require 3 network hops, thus improving the throughput by up to 30%.
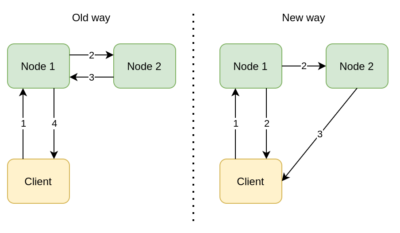
Configuration Redesign
To make the configuration easier, we redesigned it to work with keyword arguments instead of the configuration objects. To have an idea about this change, take a look at the following code snippets.
The old way:
from hazelcast.client import HazelcastClient from hazelcast.config import ClientConfig # Create the configuration object config = ClientConfig() # Customize the client configuration config.group_config.name = "cluster-name" config.network_config.addresses = [ "10.90.0.2:5701", "10.90.0.3:5701", ] config.lifecycle_listeners = [ lambda state: print("Lifecycle event >>>", state) ] # Initialize the client with the given configuration client = HazelcastClient(config)
The new way:
from hazelcast.client import HazelcastClient # No need to import ClientConfig anymore # Initialize the client with the custom configuration client = HazelcastClient( cluster_name="cluster-name", cluster_members=[ "10.90.0.2:5701", "10.90.0.3:5701", ], lifecycle_listeners=[ lambda state: print("Lifecycle event >>>", state) ] )
Also, the “shape” of the configuration was changed and made flat. We tried to preserve the names of the configuration elements as much as we can, but there are a couple of changes either to make them more clear or to give them meaning without a parent configuration. Also, all the configuration elements are documented under the HazelcastClient constructor now.
Another improvement we did for the configuration is that it is now trying to validate the given configuration and fails fast if there is a problem.
Logging
Contrary to what logging HOWTO recommends, we were adding a custom handler to the parent logger of the client to get the exact style with the Java client. This handler was producing mouthful log messages like the one below and more importantly, potentially interfering with the preferences of the library users.
15, 2019 12:51:59 PM HazelcastClient.LifecycleService
INFO: [3.10] [dev] [hz.client_0] (20181119 - 9080a46) HazelcastClient is STARTING
Feb 15, 2019 12:51:59 PM HazelcastClient.ClusterService
INFO: [3.10] [dev] [hz.client_0] Connecting to Address(host=127.0.0.1, port=5701)
Feb 15, 2019 12:51:59 PM HazelcastClient.ConnectionManager
INFO: [3.10] [dev] [hz.client_0] Authenticated with Connection(address=('127.0.0.1', 5701), id=0)
We decided to change that and removed such handlers. Now, the user has to specify the logging configuration by themselves like the code snippet below.
import logging from hazelcast.client import HazelcastClient # Configure the logging logging.basicConfig(level=logging.INFO) client = HazelcastClient() client.shutdown()
See the Logging Configuration section of our client documentation for details.
Documentation
Formerly, we were using a pretty long markdown document for our technical documentation and hosting our API documentation at Github Pages. We have decided to better structure our documentation as a whole before the stable 4.0 release. So, we have simplified the documentation we serve at PyPI and our Github repository and moved the technical and API documentation to Read The Docs.
Check the new technical and API documentation at hazelcast.readthedocs.io and tell us what you think!
Paging Predicates
Paging Predicates allow the users to filter keys, values, or entries of Hazelcast maps (a distributed version of Python’s dictionary) page by page.
Sample usage of the Paging Predicate is shown below.
# Create a paging predicate that will filter students
# older than 18, with the page size of 10
predicate = paging(greater("age", 18), 10)
# Retrieve the first page
values = students.values(predicate)
# Setup the next page
predicate.next_page()
# Retrieve the next page
values = students.values(predicate)
This was implemented for the 3.12.x version of the client by Yağmur Dülger, who is a former intern of our Clients Team and now a community member. We forward ported it with the necessary changes to the 4.x client.
With this opportunity, we once again thank Yağmur for her contributions and encourage everyone to contribute to open-source Hazelcast projects. We are more than happy to assist you in any way we can!
Other Changes
This was a quite big release for us, so we did a lot of small changes and improvements other than the items we listed above. You can see the full list of them in the release notes.
What’s Next?
We believe that the Hazelcast Python client would be a great addition to your application stack. We are planning to work harder to make it easier for you to use the client with popular libraries and frameworks through the integrations on our backlog. Here is the list of the top items in our backlog.
- Integrations with popular web frameworks such as Flask and Django
- Ability to use Hazelcast IMDG as a broker for Celery
- Easier integration with Gunicorn
- Full support for SQL feature in IMDG once it graduates from the beta status
- Eventually consistent Near Cache implementation
You can always check the Python client roadmap for an up-to-date list of backlog items. Please do not hesitate to share your ideas via our community channels.
Closing Words
This one was a quite big release for us and we are delighted to make it through. We hope that the client “looks” and performs better compared to the 3.x version, and the migrations to the new major version will be hassle-free for everyone.
We also thank another former intern of our Clients Team, Burak Dursunlar, who worked on the initial 4.0 version of the Python client.
As mentioned above if you have any questions, suggestions, or feedback we will be waiting for them in our Slack channel, Google Group, or Github repository. Better, if you want to contribute to the Python client, please take a look at our issue list or talk with us through the communication channels listed above.
Stay safe, be well, and see you soon!