Hazelcast – Low Latency Datastores for IoT
DataMountaineer recently published a blog post entitled, “Hazelcast – Low Latency Datastores for IOT“. In the post, DataMountaineer presents a strategy for building low latency datastores for Internet of Things using Kafka and Hazelcast.
The Internet of Things is on the rise, it was certainly a buzzword of 2016. Gartner thinks so, they say there will be 20 billion devices online by 2020 with all of them transmitting (streaming) data. These devices are not limited to new devices, more and more we are seeing our clients want to connect into manufacturing control systems such as SCADA. Take a utility company for example, they might want to collect and analyse wind turbine or other asset data and perform forecasting or real time steering in combination with smart home meter data.
A Streaming solution with Kafka is the ideal platform to feed this never-ending flow of data into and Kafka Connect makes connecting these sources and sinks easy. So DataMountaineer built connectors for IoT, both CoAP (Constrained Application Protocol) and MQTT.
While being able to easily ingest this data by simply passing a config file to Connect is great we still need to process the incoming messages. We could use a stream processor like Kafka Streams or we could simply configure a sink to write to a In-Memory grid like Hazelcast, or both. At Datamountaineer we have support for Hazelcast.
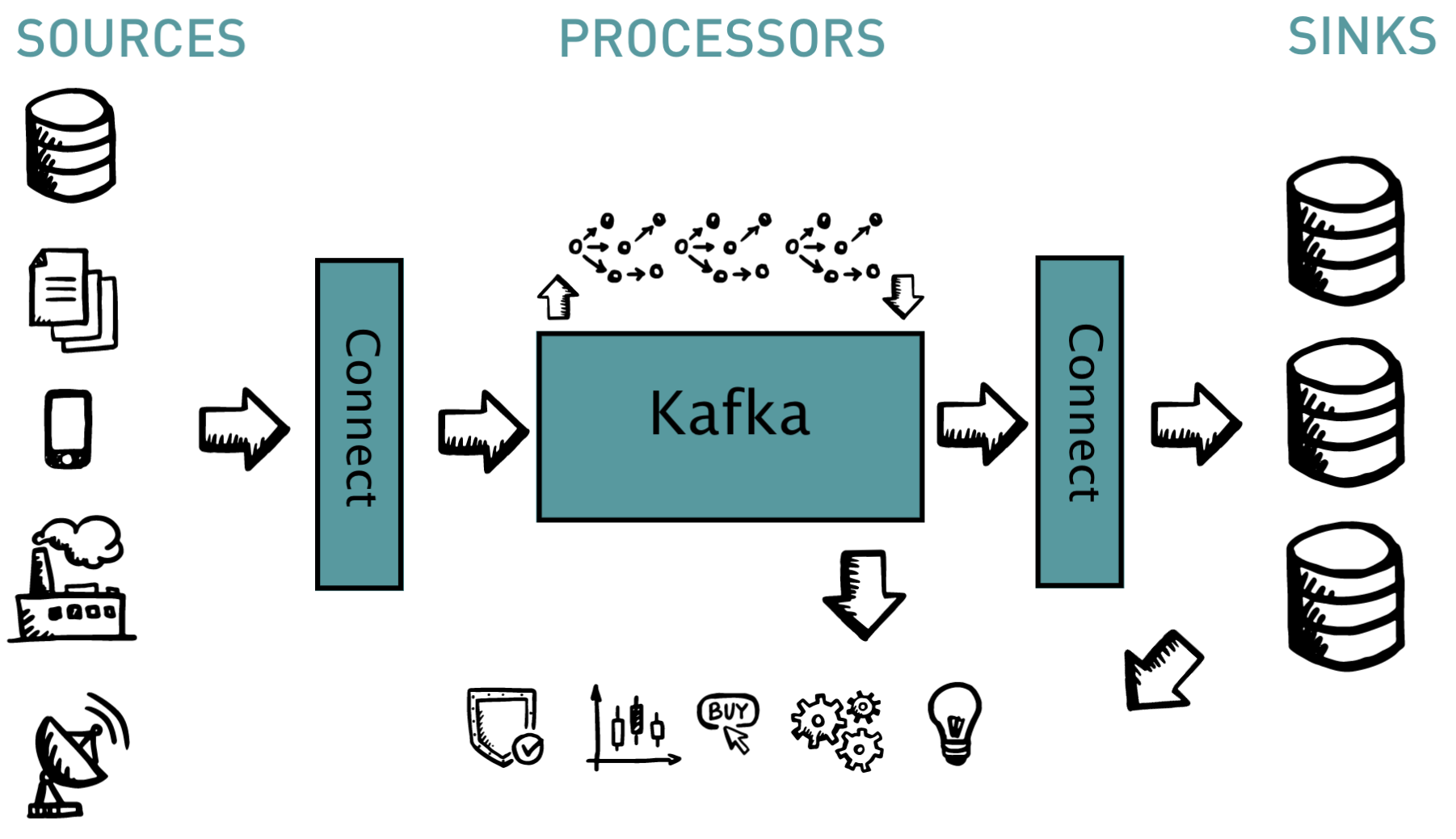
What does this architecture look like for IoT? We need to able to capture, process and persist the deluge of sensor data. Combining Kafka with Hazelcast makes this simple. You need four components to achieve this:
- Gateways Kafka Connect simplifies the loading and unloading of data in and out of Kafka.
- Pipeline Persistence Kafka, a scalable, durable commit log, is capable of ingesting the flood of data, supporting consumers tapping into the flow and acting as a buffer for the long term storage layer. It handles back pressure (fast producer, slow consumers) out of the box.
- Processing In flight processing, the heart of any stream reactor, cleansing, aggregations and real-time analytics with Kafka Streams, Spark or Flink.
- Storage Longer term storage for further processing.
Kafka Connect SOURCES SINKS PROCESSORS Connect Kafka
Hazelcast
Hazelcast, the leading open source in-memory data grid, provides a rich architecture and feature set allowing it to receive high velocity writes for data storage, perform distributed processing and act as a perfect Sink. For example Hazelcast supports distributed events, execution callbacks, entry processor and a wide array of data structures such as map, queue, reliable topics, ringbuffers and JCaches.
It also has a variety of uses cases in many sectors such as IoT, Financial, Gaming and Media. These include:
- Caching
- NoSQL
- In-Memory Grid
- Web Session Clustering
One of the key differentiators from other data stores, besides it’s incredible ease of use, is the ability to use Hazelcast as a caching layer. For example providing Database Caching, Caching as a Service, Memcached replacement or plugin and more. A very versatile and easy to use to say the least! Keep your materialized views and caches up-to-date and continuously feed from Kafka.
Another use case is as an Oracle Coherence replacement. At DataMountaineer are working on a Source connector for this, stream all your data live out of Coherence and into Hazelcast? Just a thought.

Building a flow
Now onto the flow we want to setup.
We’ll use the CoAP source to subscribe to an observable CoAP server resource and publish the messages into Kafka.The CoAP Source automatically converts the incoming COAPResponse to Avro or Json and registers the schema with the Schema Registry.
Finally we’ll use the DataMountaineer Hazelcast Sink to subscribe to the CoAP topic and stream events to a Queue in the Hazelcast Cluster.

CoAP Source
The Internet of Things has several protocols, the most notable are MQTT and CoAP, DataMountaineer has connectors for both. CoAP is the Constrained Application Protocol from the CoRE (Constrained Resource Environments) IETF group. More information and a comparison of MQTT vs CoAP is available here. The CoAP Source Connector supports observable CoAP resources and secure DTLS clients, we have blogged in more detail about our CoAP and MQTT source here.
Hazelcast Sink
The Hazelcast sink supports the following features;
KCQL
DataMountaineers SQL like connector syntax. This simplifies mappings and features of our connectors while keeping the configuration clean and stops it becoming too verbose. I’m a big fan of Flume NG and Morphlines but the configurations quickly become verbose and I go blind writing them.
For Hazelcast KCQL supports;
- Topic to Hazelcast data structure mapping.
- Field selection from the topic, requires the payload to be Avro or JSON with a schema.
- Ability to choose the storage structure types.
- Format types, JSON or Avro.
For example, to select the sensor_id, timestamp and temperature field from the coap_sensor_topic , store into a RingBuffer called sensor_ringbuffer with the payload as JSON the KCQL statement would look like this;
INSERT INTO sensor_ringbuffer SELECT sensor_id, timestamp, temperature FROM coap_sensor_topic WITH FORMAT JSON
make confluent home folder mkdir confluent download confluent wget http://packages.confluent.io/archive/3.2/confluent-3.2.0-2.11.tar.gz extract archive to confluent folder tar -xvf confluent-3.2.0-2.11.tar.gz -C confluent setup variables export CONFLUENT_HOME=~/confluent/confluent-3.2.0 cd $CONFLUENT_HOME
Start the confluent platform, we need kafka, zookeeper and the schema registry
bin/zookeeper-server-start etc/kafka/zookeeper.properties & sleep 10 && bin/kafka-server-start etc/kafka/server.properties & sleep 10 && bin/schema-registry-start etc/schema-registry/schema-registry.properties &
Additionally, we need to start Kafka Connect. We will do this in distributed mode which is straight forward but we need the CoAP Source and Hazelcast Sink on the CLASSPATH. Download the Stream Reactor. Unpack the archive and start Kafka Connect in distributed mode with the Connectors on the CLASSPATH.
We can use Kafka Connect’s Rest API to confirm that our Sink class is available.
wget https://github.com/datamountaineer/stream-reactor/releases/download/v0.2.5/stream-reactor-0.2.5-3.2.0.tar.gz mkdir stream-reactor tar xvf stream-reactor-0.2.5-3.2.0.tar.gz -C stream-reactor cd stream-reactor/stream-reactor-0.2.5-3.2.0 bin/start-connect.sh
In a new terminal check the plugins available.
bin/cli.sh plugins Class name: ConnectorPlugins(com.datamountaineer.streamreactor.connect.coap.source.CoapSourceConnector) Class name: ConnectorPlugins(com.datamountaineer.streamreactor.connect.hazelcast.sink.HazelCastSinkConnector)
CoAP
We built a small test CoAP Server which can be downloaded here for testing or you can use a Eclipse testing server. CoAP also has a FireFox plugin called Copper which you can use to inspect servers and their resources. If you want to use our test CoAP server download and start the server in a new terminal window.
wget https://github.com/datamountaineer/coap-test-server/releases/download/v1.0/start-server.sh chmod +x start-server.sh ./start-server.sh
Hazelcast
Hazelcast, while extremely powerful and flexible is also really easy to use. Setting up a cluster takes no time at all. This is all the code you need to start a Cluster node, start multiple instances and they find each other via multicast to form a cluster.
import com.hazelcast.core.*;
import com.hazelcast.config.*;
import java.util.Map;
import java.util.Queue;
public class GettingStarted {
public static void main(String[] args) {
Config cfg = new Config();
HazelcastInstance instance = Hazelcast.newHazelcastInstance(cfg);
Queue<String> queueCustomers = instance.getQueue("customers");
queueCustomers.offer("Tom");
queueCustomers.offer("Mary");
queueCustomers.offer("Jane");
System.out.println("First customer: " + queueCustomers.poll());
System.out.println("Second customer: "+ queueCustomers.peek());
System.out.println("Queue size: " + queueCustomers.size());
}
}
Even less for the Java client!
package com.hazelcast.test;
import com.hazelcast.client.config.ClientConfig;
import com.hazelcast.client.HazelcastClient;
import com.hazelcast.core.HazelcastInstance;
import com.hazelcast.core.IMap;
public class GettingStartedClient {
public static void main(String[] args) {
ClientConfig clientConfig = new ClientConfig();
clientConfig.addAddress("127.0.0.1:5701");
HazelcastInstance client = HazelcastClient.newHazelcastClient(clientConfig);
IMap map = client.getMap("customers");
System.out.println("Map Size:" + map.size());
}
}
But we don’t need to write code to get this flow going!
Lets download Hazelcast and start a server node and a client, the server will by default set its socket address as its public address so you can either modify the hazelcast.xml in the hazelcast-3.7.4/bin/ or update the connect.hazelcast.sink.cluster.members configuration option in the Sink configuration later. If you want to change the public address of the node add the following to the network section of the hazelcast.xml file.
<public-address>localhost</public-address> view rawhc-public-address.xml hosted with ❤ by GitHub #start hazeclast server node hazelcast-3.7.4/bin/start.sh
In a new terminal start the console app.
#start the console app (client node) export CLASSPATH=~/Downloads/hazelcast-3.7.5/bin/hazelcast.xml cd demo clientConsole.sh
Now in the terminal you started the server node you should see something like this:
INFO: [127.0.0.1]:5701 [dev] [3.7.4] TcpIpConnectionManager configured with Non Blocking IO-threading model: 3 input threads and 3 output threads
Jan 19, 2017 11:21:20 AM com.hazelcast.internal.cluster.impl.MulticastJoiner
INFO: [127.0.0.1]:5701 [dev] [3.7.4]
Members [1] {
Member [127.0.0.1]:5701 - 2cc01773-6525-48a0-a9a3-09ba943fd478 this
}
Jan 19, 2017 11:21:20 AM com.hazelcast.core.LifecycleService
The Hazelcast client console allows you to interact with with the cluster. For this demo we will listen to a queue for events written from Kafka. In the Hazecast client console terminal, switch to the dev namespace/group and listen to the queue:
hazelcast[default] > ns dev namespace: dev hazelcast[dev] > q.take
Starting the flow
Now that we have a Connect and Hazelcast Cluster up and running let’s give it the configurations for the CoAP Source and Hazelcast Sink. Lets create a properties file for the sink called coap-hazelcast-sink.properties.
Add the following configuration:
name=hazelcast-sink connector.class=com.datamountaineer.streamreactor.connect.hazelcast.sink.HazelCastSinkConnector max.tasks=1 topics = coap_sensor_topic connect.hazelcast.sink.cluster.members=localhost connect.hazelcast.sink.group.name=dev connect.hazelcast.sink.group.password=dev-pass connect.hazelcast.sink.kcql=INSERT INTO dev SELECT * FROM coap_sensor_topic WITHFORMAT JSON STOREAS QUEUE
This configuration is straightforward;
- Defines the name of the sink as hazelcast-sink.
- Sets the connector class to use which must be on the CLASSPATH of all workers in the Connect cluster.
- Sets the number of tasks the Connector is allowed to spawn across the cluster.
- The Hazelcast group name to use. Our Hazelcast console app listening on the other end.
- The password for the group name.
- The KCQL statement. This is saying we want to select all fields from the coap_sensor_topic topic and write them to a Queue called dev as JSON. We are using dev here since we haven’t added a new group to the hazelcast.xml config and we are listening via the demo console app.
For completeness lets create the CoAP Source config. Here we define the CoAP server and sensor resource to subscribe to. Create a file called coap-hazelcast-source.properties with the following contents.
name = coap-source connector.class = com.datamountaineer.streamreactor.connect.coap.source.CoapSourceConnector max.tasks = 1 connect.coap.source.uri = coap://localhost:5633 connect.coap.kcql = INSERT INTO coap_sensor_topic SELECT * FROM sensors
Pushing configurations to Connect
DataMountaineer has a CLI for interacting with Kafka Connect.This is a tiny command line interface (CLI) around the Kafka Connect REST Interface to manage connectors. It is used in a git like fashion where the first program argument indicates the command.
./cli.sh [ps|get|rm|create|run|status|status|plugins|describe|validate|restart|pause|resume]
The CLI is meant to behave as a good unix citizen: input from stdin; output to stdout; out of band info to stderr and non-zero exit status on error. Commands dealing with configuration expect or produce data in .properties style: key=value lines and comments start with a #.
We will use the CLI to push in the configurations to the Connect Cluster, at which point you should see the connectors starting up. If you’re using the Confluent Control Center you can also add the connectors that way.
bin/cli.sh create coap-source < conf/coap-hazelcast-source.properties
This will start the Coap Source Connector to feed entries into Kafka. Next start the Hazelcast Sink:
bin/cli.sh create hazelcast-sink < conf/hazelcast-coap-sink.properties
If you check the logs of the terminal where you started the Kafka Connect cluster you should see both Connectors start loading data into Kafka and Hazelcast.
Lets check the data in Kafka via the console consumer.
./kafka-avro-console-consumer --zookeeper localhost --topic coap_sensor_topic
{"message_id":{"int":62517},"type":{"string":"NON"},"code":"2.05","raw_code":{"int":69},"rtt":{"long":998},"is_last":{"boolean":true},"is_notification":{"boolean":true},"source":{"string":"localhost:5633"},"destination":{"string":""},"timestamp":{"long":0},"token":{"string":"d77d"},"is_duplicate":{"boolean":false},"is_confirmable":{"boolean":false},"is_rejected":{"boolean":false},"is_acknowledged":{"boolean":false},"is_canceled":{"boolean":false},"accept":{"int":-1},"block1":{"string":""},"block2":{"string":""},"content_format":{"int":0},"etags":[],"location_path":{"string":""},"location_query":{"string":""},"max_age":{"long":2},"observe":{"int":0},"proxy_uri":null,"size_1":null,"size_2":null,"uri_host":null,"uri_port":null,"uri_path":{"string":""},"uri_query":{"string":""},"payload":{"string":"{\"sensorId\":\"Sensor4\",\"timestamp\":1486997194029,\"temperature\":23.60440030439427,\"message\":\"Sensor message 98\"}"}}
{"message_id":{"int":62525},"type":{"string":"NON"},"code":"2.05","raw_code":{"int":69},"rtt":{"long":999},"is_last":{"boolean":true},"is_notification":{"boolean":true},"source":{"string":"localhost:5633"},"destination":{"string":""},"timestamp":{"long":0},"token":{"string":"d77d"},"is_duplicate":{"boolean":false},"is_confirmable":{"boolean":false},"is_rejected":{"boolean":false},"is_acknowledged":{"boolean":false},"is_canceled":{"boolean":false},"accept":{"int":-1},"block1":{"string":""},"block2":{"string":""},"content_format":{"int":0},"etags":[],"location_path":{"string":""},"location_query":{"string":""},"max_age":{"long":2},"observe":{"int":0},"proxy_uri":null,"size_1":null,"size_2":null,"uri_host":null,"uri_port":null,"uri_path":{"string":""},"uri_query":{"string":""},"payload":{"string":"{\"sensorId\":\"Sensor5\",\"timestamp\":1486997199029,\"temperature\":25.7178981915713,\"message\":\"Sensor message 106\"}"}}
Back in our Hazelcast console app we should see data arriving:
hazelcast[default] > ns dev
namespace: dev
hazelcast[dev] > q.take
{"ingest_time":1487166342000,"message_id":34158,"type":"ACK","code":"2.05","raw_code":69,"rtt":65,"is_last":true,"is_notification":true,"source":"localhost:5633","destination":"","timestamp":0,"token":"6b3e66","is_duplicate":false,"is_confirmable":false,"is_rejected":false,"is_acknowledged":false,"is_canceled":false,"accept":-1,"block1":"","block2":"","content_format":0,"etags":[],"location_path":"","location_query":"","max_age":2,"observe":0,"proxy_uri":null,"size_1":null,"size_2":null,"uri_host":null,"uri_port":null,"uri_path":"","uri_query":"","payload":"{\"sensorId\":\"Sensor5\",\"timestamp\":1487166341936,\"temperature\":28.33645994241467,\"message\":\"Sensor message 1\"}"}
hazelcast[dev] > q.take
{"ingest_time":1487166346002,"message_id":34159,"type":"ACK","code":"2.05","raw_code":69,"rtt":3,"is_last":true,"is_notification":true,"source":"localhost:5633","destination":"","timestamp":0,"token":"6b3e66","is_duplicate":false,"is_confirmable":false,"is_rejected":false,"is_acknowledged":false,"is_canceled":false,"accept":-1,"block1":"","block2":"","content_format":0,"etags":[],"location_path":"","location_query":"","max_age":2,"observe":0,"proxy_uri":null,"size_1":null,"size_2":null,"uri_host":null,"uri_port":null,"uri_path":"","uri_query":"","payload":"{\"sensorId\":\"Sensor4\",\"timestamp\":1487166346000,\"temperature\":22.77444653747327,\"message\":\"Sensor message 2\"}"}
hazelcast[dev] > q.iterator
1 {"ingest_time":1487166350005,"message_id":34160,"type":"ACK","code":"2.05","raw_code":69,"rtt":2,"is_last":true,"is_notification":true,"source":"localhost:5633","destination":"","timestamp":0,"token":"6b3e66","is_duplicate":false,"is_confirmable":false,"is_rejected":false,"is_acknowledged":false,"is_canceled":false,"accept":-1,"block1":"","block2":"","content_format":0,"etags":[],"location_path":"","location_query":"","max_age":2,"observe":0,"proxy_uri":null,"size_1":null,"size_2":null,"uri_host":null,"uri_port":null,"uri_path":"","uri_query":"","payload":"{\"sensorId\":\"Sensor4\",\"timestamp\":1487166350004,\"temperature\":24.549225553626442,\"message\":\"Sensor message 4\"}"}
2 {"ingest_time":1487166354011,"message_id":34161,"type":"ACK","code":"2.05","raw_code":69,"rtt":3,"is_last":true,"is_notification":true,"source":"localhost:5633","destination":"","timestamp":0,"token":"6b3e66","is_duplicate":false,"is_confirmable":false,"is_rejected":false,"is_acknowledged":false,"is_canceled":false,"accept":-1,"block1":"","block2":"","content_format":0,"etags":[],"location_path":"","location_query":"","max_age":2,"observe":0,"proxy_uri":null,"size_1":null,"size_2":null,"uri_host":null,"uri_port":null,"uri_path":"","uri_query":"","payload":"{\"sensorId\":\"Sensor4\",\"timestamp\":1487166354009,\"temperature\":24.316168206573426,\"message\":\"Sensor message 7\"}"}
Conclusion
Kafka Connect provides a common framework to load and unload data to and from Kafka, it takes care of the hard parts of data ingestion for you;
- Delivery semantics
- Offset management
- Serialization / de-serialization
- Partitioning / scalability
- Fault tolerance / failover
- Data model integration
- CI/CD
- Metrics / monitoring
DataMountaineer has covered IoT with both CoAP and MQTT, coupled with the Hazelcast as a processing engine and storage layer it is easy to construct, simple, reliable and scalable dataflows to handle IoT stream processing and analytics.