
By Can Gencer
VP R&D
Can is one of the founding members of the Hazelcast Jet team and is currently the engineering team lead. Prior to joining Hazelcast, he worked as a software development consultant to some of the world’s leading investment banks. He has deep interest in distributed systems, stream processing and building high-throughput, low-latency data pipelines. He is also a polyglot programmer with expertise in Java, Python, C# and functional programming.
View all blogs by the authorJun 27, 2019
Hazelcast Jet 3.1 is Released
After releasing Hazelcast Jet 3.0 in May, we are happy to announce its first update, Hazelcast Jet 3.1.
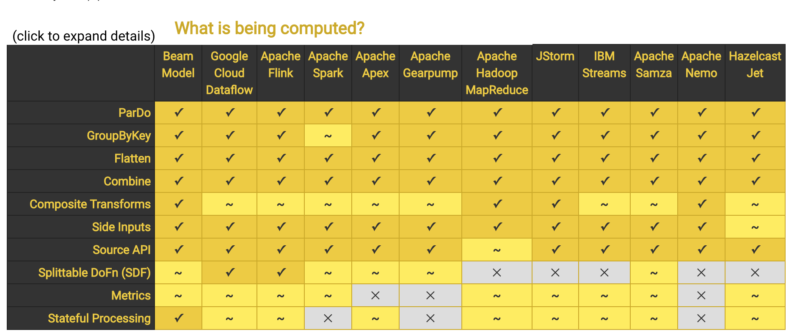
Hazelcast Jet is now an Apache Beam Runner
Apache Beam is a framework for building distributed batch and stream processing applications over a unified API. The API itself is decoupled from the underlying execution implementation, making it possible to use Apache Beam with different execution engines. Over the last few months, we have been developing a Runner for it and we are happy to announce that the Hazelcast Jet Runner will be included in the next Apache Beam release.
New Contributor Repository and New Connectors
We have introduced a new repository for community supported modules for Hazelcast Jet. The repository currently contains the following modules:
- InfluxDB source and sink: A connector which can write to or read from InfluxDB
- Elasticsearch source and sink: A connector which is able to read from or write to Elasticsearch
- Probabilistic Aggregations: Contains probabilistic aggregations which can be used to estimate the cardinality of a data set with very low memory usage
Extended SourceBuilder API
SourceBuilder API has been extended to include support for fault tolerance. A source built using this API is now able to save its state during snapshots and restore it when a job is restarted. This will allow custom sources which are repayable to support at-least-once and exactly-once processing.
Support for Composite Transforms
We have added a new apply operator which can be used to compose multiple transforms into one and then use it as a building block. For example, if we have the following pipeline:
pipeline
.drawFrom(textSource)
.map(String::toLowerCase)
.filter(s -> s.startsWith("success"))
.flatMap(line -> traverseArray(line.split("\\W+")))
.drainTo(Sinks.logger());
It can be transformed as:
StreamStage<String> cleanUp(StreamStage<String> input) {
input.map(String::toLowerCase)
.filter(s -> s.startsWith("success"));
}
pipeline
.drawFrom(textSource)
.apply(this::cleanUp)
.flatMap(line -> traverseArray(line.split("\\W+")))
.drainTo(Sinks.logger());
YAML Configuration
As with Hazelcast IMDG, Jet also now fully supports YAML based configuration as an alternative to XML:
hazelcast-jet:
instance:
cooperative-thread-count: 8
flow-control-period: 100
backup-count: 1
scale-up-delay-millis: 10000
lossless-restart-enabled: false
edge-defaults:
queue-size: 1024
packet-size-limit: 16384
receive-window-multiplier: 3
metrics:
enabled: true
jmx-enabled: true
collection-interval-seconds: 5
retention-seconds: 5
metrics-for-data-structures: false
See the configuration section in the reference manual for more details.
New Aggregate Operations
The aggregate operations filtering and flatMapping have been added to complement the mapping operator. These operations can be used as the foundation to build more complex aggregate operations:
people.aggregate(allOf(
filtering(
(Person p) -> p.getAge() < 18, averagingLong(Person::getHeight)
),
filtering(
(Person p) -> p.getAge() >= 18, averagingLong(Person::getHeight)
)
));
For a full list of changes and fixes, please see the release notes. Hazelcast Jet 3.1 is available to try via our downloads page.