
By Rahul Gupta
Rahul Gupta is the Senior Director of Solutions Architecture at Hazelcast, where he continues to solve a wide range of business initiatives, largely in Big data and Real-Time processing space, with modern yet trusted technology for a good part of 15 years. Today, Hazelcast is a distributed platform comprising in-memory data store and stream/batch processing engine to solve complex data problems requiring running extreme workloads. Rahul has traveled the world, speaking at various international conferences, tech meetups, and large user groups worldwide. He is an avid blogger and has written many pieces on Hazelcast and related technologies, real-life use cases, and case studies.
View all blogs by the authorFeb 2, 2021
Getting More from Your Mainframe by Integrating In-Memory Computing
In the modern era of digital transformation, mainframe systems continue to stand out against the backdrop of the constantly changing ecosystem of global enterprise IT. More and more industries such as banking, retail, telecommunications, and healthcare rely on mainframe computing to manage processing of large volumes of data to serve thousands of users at any given time.
According to a Micro Focus customer survey published in 2017, plans were put in place to maintain or modernize 84% of mainframe applications in the near future. Since then, a large number of organizations have realised the importance of upgrading the legacy infrastructure and are now pursuing this goal.
Organisations usually tend to build upon what already works and mainframe environments fit perfectly in that thought process. Although mainframe environments have fast response times and are uniquely resilient, they still need to be kept up-to-date to address the challenges posed by the constantly growing and developing landscape of modern computing.
Below are some of the very important such challenges that will continue to play significant role in the mainframe world:
Ensuring high availability for critical workloads
For any mission-critical workload, a brief period of unplanned outage could have serious consequences for the end user, brand reputation, and your employees. Different organizations have specific needs for availability and that requires planned maintenance strategies, which is also necessary to build a system with minimal risks of unplanned downtime.
Ease of use for modern applications
It is a common practice to methodically modernize existing systems and connect them with mobile and cloud applications. More than 65% of enterprise software and 70% of business transaction processing are still powered by COBOL, and now that Enterprise COBOL can work directly with Java, JSON and XML, business decision-makers know that they need to retire mainframes that run on COBOL and modernize legacy systems that do not require mainframe runtime.
The organisations that have braved the fear of change have started to invest a good amount of focus into keeping applications lightweight and containerized for portability. More and more organisations are rapidly adopting cloud-based infrastructure for running backend processes, which drives the need for easy integration with cloud compatible software.
Reduced mainframe costs
A universal standard of measuring the cost of using a mainframe system is MIPS, which stands for Million Instructions Per Second and it indicates the system’s speed and power. The cost of using a mainframe system is directly proportional to MIPS consumption. For example, a high MIPS consumption indicates high resource utilization (cpu, memory), and which directly results in higher financial costs.
With the evolution of technology, MIPS consumption is also steadily increasing. Industry analysts estimate that most of the large organizations using mainframe systems should expect their CPU consumption to increase by more than 1000% annually. As a result of which, the companies have grown conscious of the financial impact it would have on businesses. Therefore they are looking for ways to reduce the costs of their mainframe environment with immediate impact and at low risk. Two of the easiest, low hanging yet highly critical items in mainframe computing cycle that the organisations are looking to act upon to reduce MIPS consumption are:
- Avoid repetitive usage of I/O calls for the same data
- Move top CPU consuming jobs/transactions out of mainframe environment
Hazelcast for mainframe
Let us take a look at how Hazelcast has been helping out organisations worldwide in their pursuit of modernizing legacy mainframe systems by addressing the above-mentioned challenges in a highly cost-effective yet user-friendly way.
The technology is architected for environments that demand extremely high performance, elastic scale, and the availability promise of five 9s. It also provides a powerful computing platform that runs complex business algorithms, executes AI/ML models, etc., with ease in a highly concurrent environment. Add to this the plug ‘n’ play nature, enterprise-grade security capabilities, off-the-shelf integration with numerous other software, and cloud-native deployments, and Hazelcast becomes the driving technology behind many of today’s leading financial, e-commerce/retail, telecommunications, healthcare, and government organizations.
In the rest of this article, we will delve into a test conducted on a multi-dimensional cross datacenter replication configuration originating at a Hazelcast cluster deployed on an IBM powered Z Platform. We will learn how Hazelcast allows mainframe applications to perform additional complex business functions at ultra-high speeds without any significant increase in costs (MIPS). We will also learn how the technology efficiently utilises data stored in legacy systems and also makes that available to modern applications without affecting MIPS cost.
In this test, we will see Hazelcast cluster running on the Z Platform pulling data out of a legacy database (DB2) running on Z. It will run business functions and at the same time, externalize the legacy data by making it available to other applications without hitting the mainframe. This type of architecture is commonly referred to as a digital integration hub, where data from multiple sources is made available to a variety of consumers (applications).
Before we get into the specifics of the test, let’s first take a look at how Hazelcast ensures High Availability and provides Ease of Use in the context of mainframe modernization.
High Availability with Hazelcast
With the in-built redundancy through memory-resident backups and no single point of failure, Hazelcast delivers an always-on and always-available infrastructure. The write-through persistence and read-through/read-aside lookup framework ensures that the data is always available at in-memory speeds whenever requested by applications.
Read here for more information on how the data is stored on Hazelcast and how the backups are activated to provide redundancy:
https://docs.hazelcast.org/docs/latest/manual/html-single/index.html#data-partitioning
Read here for more information on write-through/write-behind persistence and read-aside/read-through lookup with any data store that runs underneath a Hazelcast cluster: https://docs.hazelcast.org/docs/latest/manual/html-single/index.html#loading-and-storing-persistent-data
Another important offering from Hazelcast and one of the most commonly used features across organizations around the world is cross datacenter replication, also known as WAN Replication. This allows you to run multiple Hazelcast clusters across geographies and keep them in sync with each other to maintain data consistency. This lets your applications switch from one cluster to another if the original cluster is not available. It also helps to reduce latency across geographically remote sites by leveraging local copies of your cluster that shorten the network hops. Read here for more about WAN Replication: https://docs.hazelcast.org/docs/4.1.1/manual/html-single/index.html#wan-replication
With the combination of built-in redundancy, read-aside lookup, and WAN Replication, Hazelcast allows you to build a powerful and robust in-memory distributed infrastructure that is capable of handling unplanned outages on its own while protecting the data.
Using Hazelcast
Although Hazelcast is a Java-based technology, it also supports applications written in different languages such as C/C++, .NET, Python, and more. Applications written in different languages running on different platforms can interact with the same Hazelcast cluster, all at the same time.
For Java users, Hazelcast APIs are the direct extension of the Java SDK, providing a high degree of familiarity with the APIs and making Hazelcast very easy to use. For non-Java users, Hazelcast provides native libraries for many different programming languages. Check this link for more information on all supported programming platforms: https://hazelcast.org/imdg/clients-languages/
Deploying a Hazelcast cluster is as easy as downloading an approximately 20 MB JAR file and either putting in an application CLASSPATH to initialize a cluster instance or use a script to launch one. Since Hazelcast servers are Java applications, a cluster can be deployed on any infrastructure that supports a Java runtime.
Run Hazelcast on IBM Z Platform
For the purpose of this test, we will use a popular business use case of running fraud detection on a financial transaction to determine whether the transaction is a genuine transaction or a fraudulent one.
In a real-world scenario, a financial transaction may have various sources – credit card terminals, ATM machines, online applications etc. Those transactions are then sent to a backend infrastructure for processing which entails running various operations before a result could be established.
This test runs on an IBM Z Platform that runs z/OS, which hosts a DB2 instance, a CICS console, zIIP environment, and much more.
Special note about zIIP: IBM® z Integrated Information Processor (zIIP) is a dedicated processor designed to operate asynchronously with the general processors in a mainframe to process new workloads; manage containers and hybrid cloud interfaces; facilitate system recovery; and assist with several types of analytics, systems monitoring and other applications.
IBM does not impose IBM software charges on zIIP capacity, except when additional general purpose CP capacity is used. In other words, Hazelcast exploits zIIP specialty engines to run cluster instances on mainframes while reducing total cost of ownership (TCO) even further.
More on zIIP here: https://www.ibm.com/au-en/marketplace/z-integrated-information-processor-ziip
Architecture and deployment
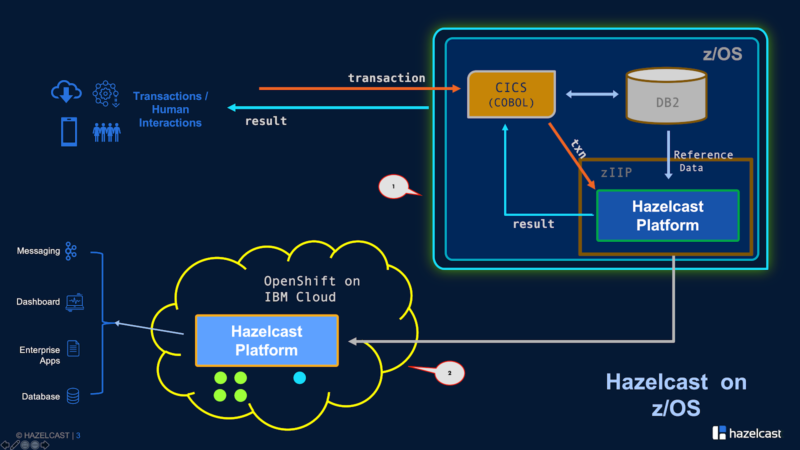
Let us take a step-by-step look at Hazelcast cluster deployment on mainframes (IBM), data access patterns, integration with various applications, externalization of data, and fault-tolerance. Figure 1 below shows all the different components used in this test:
CICS — the transaction engine that generates a financial transaction and sends it to the Hazelcast Platform for processing.
DB2 — the RDBMS that stores reference data, which is required for transaction processing. This is also the data that we will aim to externalize and make it available to applications running outside of the mainframe ecosystem.
Hazelcast Platform — two instances of the Hazelcast Platform were deployed (Fig 1):
- One running on zIIP on z/OS. We will refer to this cluster as Cluster 1 in the rest of this article.
- Another deployment running on an OpenShift cluster deployed on IBM Cloud, outside of the mainframe environment. We will refer to this cluster as Cluster 2 in the rest of this article.
Figure 1. The topology of the two Hazelcast deployments.
Both platform clusters connect with each other via Hazelcast WAN Replication, where the data that gets stored on distributed maps (i.e., name-value data structures) on Cluster 1 is also immediately replicated to Cluster 2.
Here is the flow:
- On startup, Cluster 1 pulls the reference data from DB2 and caches it in two distributed maps – Account and Merchant. See the below server logs in Figure 2 and the Management Center view of the cluster with data in Figure 3:
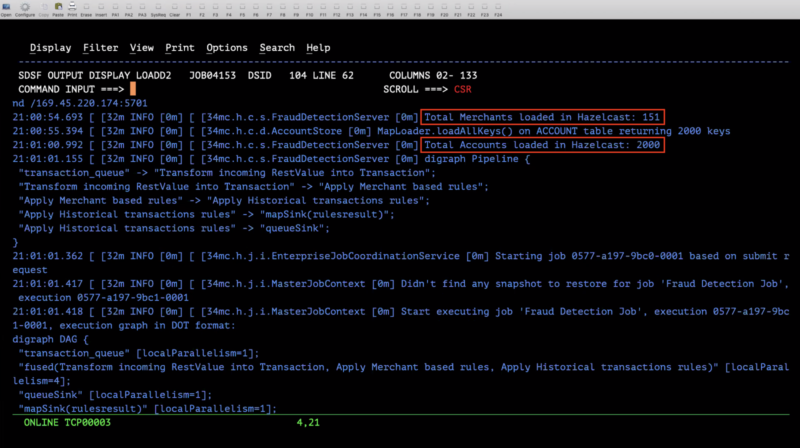
Figure 2. Server logs for Cluster 1.
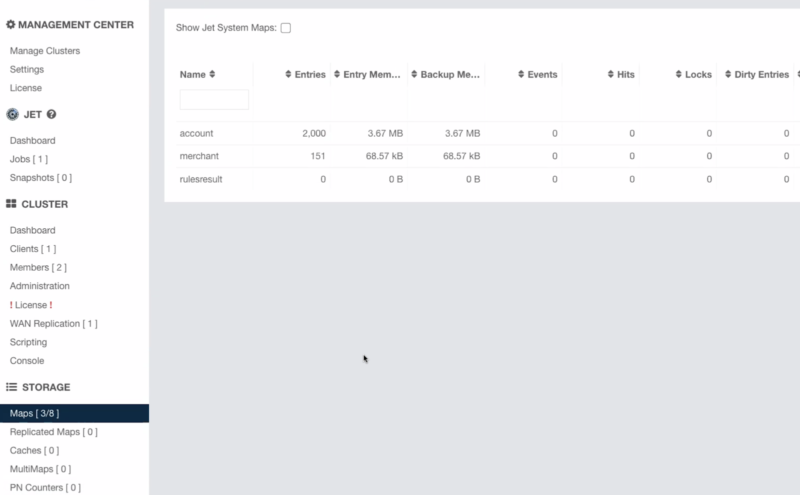
Figure 3. The Management Center view for Cluster 1 running on zIIP.
Reminder: Since Hazelcast servers are running on zIIP, there is no extra cost for keeping data in the Hazelcast cluster
- As Cluster 1 loads data into its cache, it also replicates the data into distributed maps in Cluster 2. See Figure 4 below for the Management Center view of Cluster 2 (OpenShift).
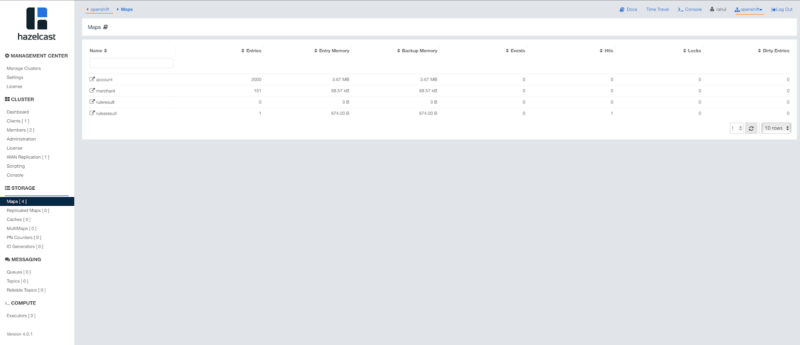
Figure 4. The Management Center view of Cluster 2 running on OpenShift.
- Cluster 1 is pre-configured and is already running a fraud detection engine that runs continuously. This engine waits for a transaction to arrive into the platform (it waits for a transaction to be posted in an input Hazelcast IQueue data structure). Upon arrival, the transaction is picked up for processing which entails several stages, including transformation, fraud checks, results processing, etc. Look at Figure 5 below for the various stages of the fraud detection pipeline.
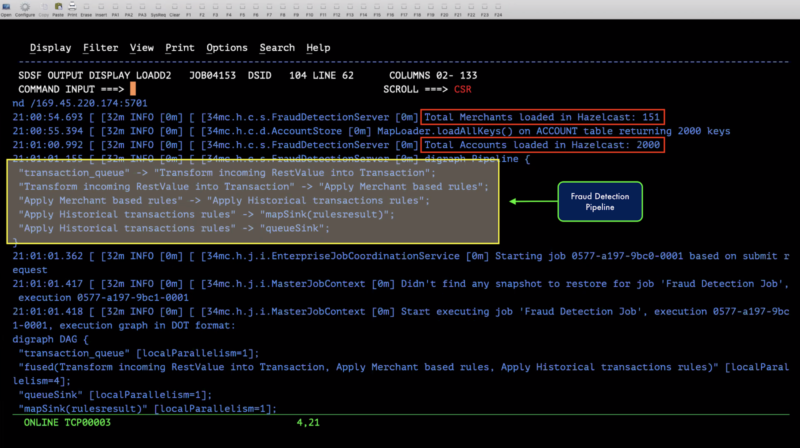
Figure 5. The fraud detection pipeline.
When the transaction comes out of the pipeline after going through the entire process of fraud detection, the result is published to an output Hazelcast IQueue. This result can then be consumed by any application through various methods: direct Hazelcast client, REST call, etc.
The Java class that defines the pipeline is available here: https://github.com/hazelcast/hazelcast-mainframe-demos/blob/master/fraud-detection-mainframe-wan/src/main/java/com/hazelcast/certification/server/FraudDetectionServer.java#L81
- For transaction generation (as depicted in Figure 1), we will use a CICS application written in COBOL, which accepts different parameters for a financial transaction. It then builds a comma separated transaction string and makes a REST call to Cluster 1 to post the transaction string onto a Hazelcast IQueue. See Figure 6 below:
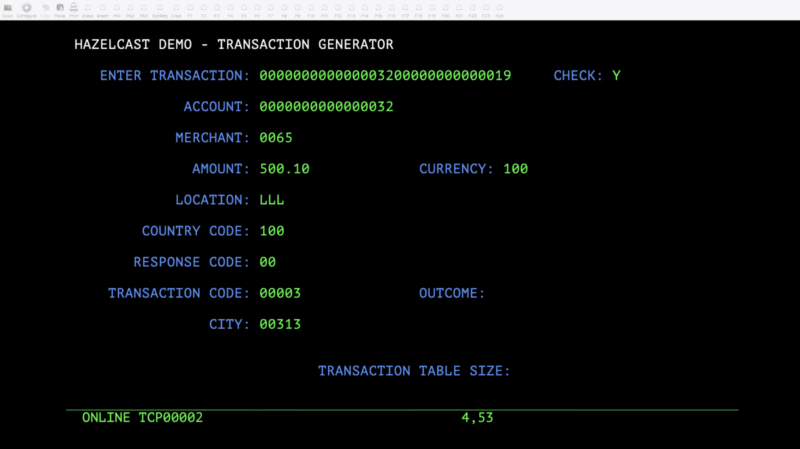
Figure 6. Transaction data sent to Cluster 1.
The CICS console further waits on the output Hazelcast IQueue for the result and as soon as it finds one, it publishes the output on the console (Figure 7).
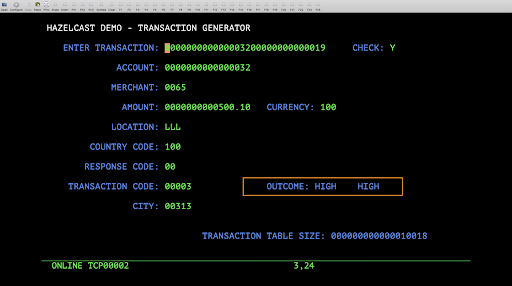
Figure 7. Output of the console.
The outcome of fraud detection on this transaction is = High risk on merchant and High risk on transaction amount.
- When the fraud detection engine running on Cluster 1 produces the output of the financial transaction, it also places the result on another Hazelcast IMap called rulesresult. The map rulesresult is also WAN replicated to Cluster 2.
Conclusion
To summarize the experiment of running Hazelcast on a mainframe environment, we learned that Hazelcast is a completely independent and very lightweight distributed technology that has all the bells and whistles to run complex yet ultra-fast business functions, make legacy data available to modern applications, allow easy scale and keep the costs down. We also learned that deploying a Hazelcast Platform on a mainframe environment is not rocket science, the native clustering mechanism of Hazelcast is such that it makes the technology infrastructure agnostic. All it means is that Hazelcast can be deployed in its default state on any environment, without requiring other third party software to run.
Reduced MIPS cost
By running Hazelcast on zIIP, there are significantly huge savings on operational and maintenance costs. At the same time, you have the ability to extract data out of legacy systems and use it to solve complex business problems in the areas of financial transaction processing, validations, fraud checks, scientific algorithms, etc.
Externalize the Data
Once the data is extracted out of legacy systems and stored in the Hazelcast Platform, it is immediately available to all applications running either on the mainframe or outside of it. This “digital integration hub” allows you to use your mainframe data in any new application you build in the future, with extremely fast data access and significant savings on MIPS costs. With the support for multiple programming languages, Hazelcast makes it easy to let different types of applications use the all-important data, at in-memory speeds.
With WAN Replication, data is sent outside of the mainframe environment and is made available to all other applications that need data in the cloud, or on other PaaS systems, or on any other infrastructure.
High Availability
With default built-in redundancy, configurable level of fault tolerance and WAN Replication capabilities, Hazelcast ensures to keep the data available with promised uptime of five 9s.
Fraud detection demo
This is a Java project and the code can be found at https://github.com/hazelcast/hazelcast-mainframe-demos