
Software Engineer
Metin is a Software Engineer working on the Clients Team. Since joining Hazelcast as an intern, he has been working on various clients such as Python, Node.js, and Java.
View all blogs by the authorDec 19, 2022
Compact Serialization: In-Depth
In the previous blog post, we introduced Compact Serialization and showed how to use it.
In this post, we will examine the details of the Compact Serialization to give you a better idea of how things are working “under the hood.”
We will start by showing how the Compact Serialized objects are laid out in the binary, talk about the schemas, and how Hazelcast uses them to read or query data, as well as support class evolution. We will also briefly show how Hazelcast replicates the schemas across the cluster and talk about the zero configuration.
Binary Representation

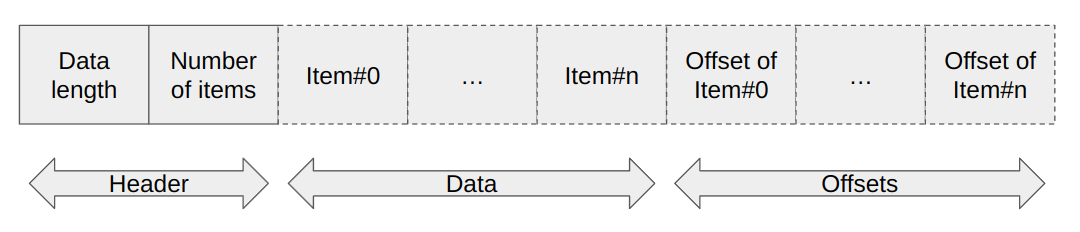
As the image above shows, the binary representation of the Compact Serialized objects consists of three sections. Note, in the above image, the dashed borders represent that these are optional and might not be in the binary representation depending on the schema.
The endianness of the data is configurable in client or member, and they must be consistent.
Header Section
This section consists of two numbers back to back.
Schema id is an 8-byte number that uniquely identifies the schema. It is used to associate the data with the actual schema so that we can avoid duplicating it in every serialized object but still know the structure of the binary data.
Data length is a 4-byte optional number, representing the data section size in bytes. Suppose the schema does not have any variable-size fields. In that case, this number is excluded from the binary form, as the length of the data section can be determined by the length of the fixed-size data, which is a piece of information available in the schema. It is used to determine where the offsets section starts.
Data Section
This section is where the actual data sits in the binary representation. It consists of two subsections, both of which are optional depending on whether at least one fixed-size or variable-size field exists in the schema.
Fixed-size fields subsection contains the data of the fixed-size fields listed in the previous blog post, sorted in descending order of the number of bytes occupied by the fields, and the ascending order of the alphabetical names of the fields, in case of ties. A special optimization is made for boolean fields, where we pack 8 boolean fields into 1 byte, spending only a single bit per boolean field.
The fixed-size fields cannot be null, hence they are always in the binary data.
Variable-size fields subsection contains the data of the variable-size fields, sorted in the ascending order of the alphabetical names of the fields. A special optimization is made for the array of boolean fields, where we pack 8 boolean items into a single item of size 1 byte, spending only a single bit per boolean item.
Arrays of fixed-size fields are serialized as shown below, where the number of items is a 4 bytes integer, and each item occupies a fixed number of bytes, according to its type.

Arrays of variable-size fields are serialized as shown below, where the data length and the number of items are two 4 bytes integers describing the length of the data section and the number of items in the array respectively. The offsets section of the array has the same properties as the offsets section described below for the Compact Serialized objects.
The variable-size fields can be null, hence they can be missing in the binary data.
Offsets Section
As the size of the variable-size fields cannot be known beforehand, there has to be an extra level of indirection to determine the actual offsets of the fields that rest in the binary data.
The offsets section consists of an offset for each variable-size field. The orders of offsets for fields are determined from the schema, according to the ascending alphabetical order of the names of the fields.
For variable-size fields that are null, a special value, -1, is used as the offset.
The size of the offsets can be either 1, 2, or 4 bytes, depending on the size of the data section. This is an optimization to avoid wasting more space for offsets than necessary when the actual data fits into 254 bytes (1 byte offsets) or 65534 bytes (2 byte offsets).
This section is also optional and is only present in the binary data if there is at least one variable-size field in the schema.
Schema
Schema is the central structure of the Compact Serialization, which describes the binary data. It is used in the serialization and deserialization processes to put the data into the correct places.
A schema consists of two pieces: the schema id and the fields.
The schema id is calculated from the fields and the type name was given by the user. So, the type name, number of fields, names of the fields, and types of fields identify the schema. When any one of them changes slightly, so does the schema id. It is a unique fingerprint of the user classes or types.
The id is calculated from the information described above using the Rabin Fingerprint algorithm. We use 64 bits long fingerprints, which should result in no collision for schema caches up to a million entries, far beyond the number of schemas expected to be available in a running Hazelcast system.
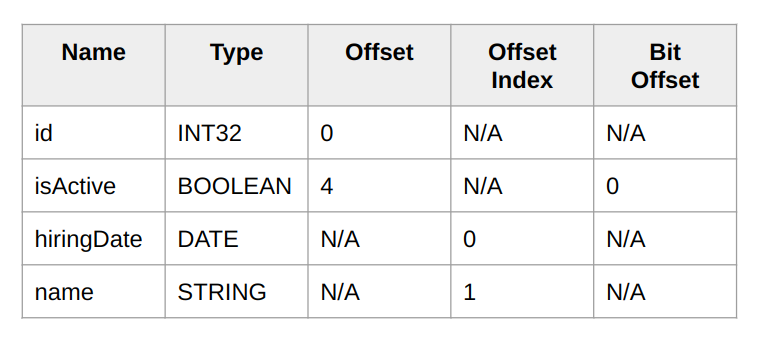
The other important piece of the schema is the fields, which consist of the following information:
- Name
- Type
- Offset (for fixed-size fields)
- Offset index (for variable-size fields)
- Bit offset (for boolean fields)
With that information, the schema can be considered a lookup table and used to deserialize individual fields.
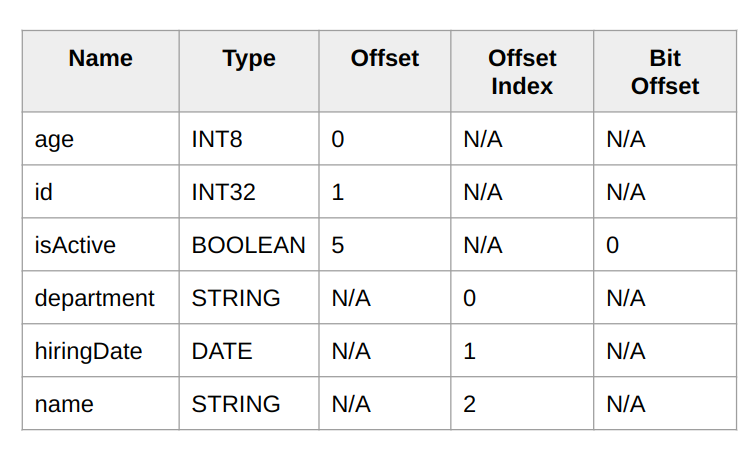
Let’s see the schema in action to read a fixed-size and variable-size field from a schema consisting of the following fields:
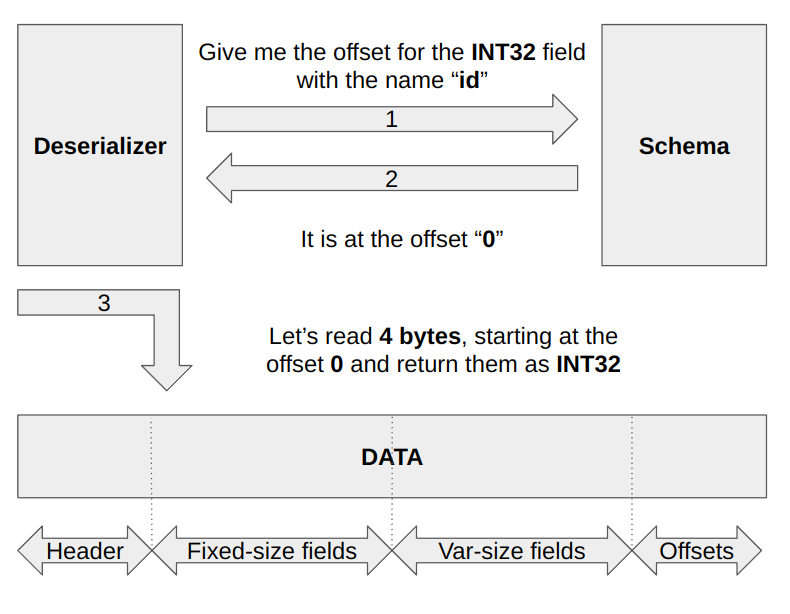
Let’s start with reading a fixed-size field, “id”. First, we need to consult the schema to learn the offset that the data for that field begins. We can do that by asking for the fixed-size field offset with the field name and the type. The schema can return the offset as long as a field with that name and the type exists in itself. In this case, such a field exists, and it starts at the offset “0”. After getting that information from the schema, we can go to that offset, read 4 bytes, and reinterpret it as int32.
As seen from the image below, we can read fixed-size fields with just one lookup, which is another improvement over the Portable serialization.
We will not be showing the deserialization procedure for the boolean fields not to repeat ourselves. Still, it is very similar to reading other fixed-size fields: We first ask the schema for offset and bit offset, read a single byte at the given offset from the fixed-size fields section, and mask and return the bit given at the returned bit offset.
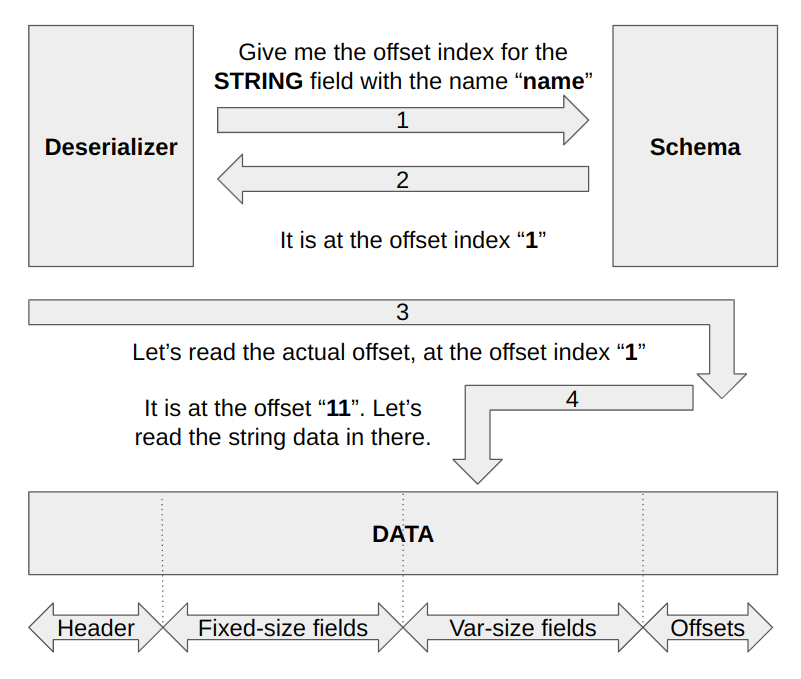
Reading variable-size fields involves an extra lookup because we can’t pinpoint the locations on them from the schema, as they differ for each binary data. For some data, a variable-size field might take 10 bytes, and for another, it might take 100 bytes. Due to that, we always encode the offsets of the variable-size fields into the binary itself in the offsets section described above. We again consult the schema to learn the index where the offset for the given field resides in the offsets section. For the string field with the “name”, the schema returns the offset index “1”. With that information, we can jump to the offsets section, and read the offset at the given index. We know exactly where the index sits in the data because we know how many bytes a single offset index occupies from the data size. After reading the actual offset, we can read the data as a string. This mechanism is the same as the Portable serialization, but we optimize the offset sizes in the data depending on the data size.
Schema Evolution
It is expected for the user classes or types to evolve as time passes. New fields might be added, some fields might be removed, or the types of fields might change. The Compact Serialization format supports all those use cases by design.
As we stated above, the schema id is calculated from the type name given by the user and the fields. If the fields change in any way by adding or removing fields, the schema id changes along with it. That results in a completely new schema tied to earlier versions of the schemas of the user classes only by the type name. There is no relationship between the old and new schemas in any other way.
Hazelcast clients and members implement ways to store and retrieve all versions of the schemas in a running cluster. Therefore, any deserializer can access all the schemas available in the cluster and use them.
When Hazelcast is confronted with the data, it first checks the schema id and finds a schema associated with it.
After finding the schema, the deserializers do nothing special. They again consult the schema for the offsets, offset indexes, or bit offsets of the fields while deserializing the data. Using the schema as the source of truth allows the deserializers to dynamically use different schemas to read evolved versions of the data by changing nothing on their side.
In the above section, we showed how we use the schemas to get the necessary information to read the actual data. From the point of view of the deserializer, using schema#0 or schema#1 makes no difference at all. As long as there is a field with that name and the type, the new or the old schema will return the correct offset, offset index, or bit offset for that field.
For example, in the next version of our application, assume that we have added integer “age” and string “department” fields to the schema; there would be no need for any change in the old applications. When the old applications asked for the offset of the “id” field, they were reading the 4 bytes starting at the offset “0”, because the schema told them so. Now, they would be reading the 4 bytes starting at the offset “1”, again because the new schema told them so. The same thing holds true for the “name” field. They were reading the actual offset from the offset index “1”, but now they will use the index “2” for the new data and still be able to read the data written by the new application without any change. For the newly added fields, an old application will ignore them, as it was not aware of them at the beginning.
Now, what happens when I try to read the data written by the old applications with the new application? The answer is that you can keep reading the existing fields on the old schema. For the newly added fields, you have to use the APIs shown in the previous blog post to conditionally skip reading the fields because there won’t be such fields in the old schemas.
Partial Deserialization
Hazelcast is a real-time data platform. Apart from storing the data, doing queries, aggregations, and indexing operations on the data is quite a common practice.
However, most of the time, we would only need part of the data and don’t necessarily need to deserialize the whole of it. Deserialization is quite costly, so avoiding any part of it would be a win for us. That’s why the new Compact Serialization format supports partial deserialization.
For example, when an index is added to Hazelcast for the “department” field shown above, it will only deserialize that string field while updating the indexes.
The benefit of partial deserialization is quite noticeable when one application switches from IdentifiedDataSerializable to Compact Serialization.
Schema Replication
As shown above, the schema and the data are now separate entities. However, Hazelcast nodes need to know the schema to be able to work on the data associated with it. Without a schema, data is just a regular byte array; nothing can be known about it.
That’s why we have to ensure that any schema associated with the data about to be put into Hazelcast must be replicated across the Hazelcast cluster.
There are a few things about the schemas that make the replication easier and do not need any consensus protocol.
Schemas are unique. There is only a single schema for a given schema id. There is no relationship between different “versions” of the schemas. The order that the schemas are delivered to the system is not important. In short, schema delivery is a commutative, associative, and idempotent operation.
Hazelcast achieves reliable replication of the schemas to the cluster by making sure that:
- Before sending any data associated with a schema, the clients must make sure that the schema is replicated across the cluster by waiting on acknowledgment from one of the cluster members once for any schema.
- For any schema to be replicated across the cluster that is not known to be replicated yet, the cluster members initiate the replication procedure. The replication procedure resembles the two-phase commit protocol and ensures that the schema is available in every cluster node before declaring it replicated.
Hazelcast also supports schema persistence and replication over WAN so that the Compact Serialization can be used with HotRestart persistence and WAN replication.
Note that it is not possible to delete schemas after they are replicated right now. There are plans to integrate schema management capabilities into the Management Center in the future.
Zero Configuration
As described in the previous blog post, it is possible to use Compact Serialization without doing any configuration at all, currently only in Java and C# clients.
Under the hood, Hazelcast creates a serializer in runtime for a class the first time it is being serialized. It uses reflection to determine the fields of a class, both the types and names, and registers a serializer that uses reflection to read and write fields.
The type name used for this runtime serializer is selected as the fully qualified class name.
The supported field types differ from language to language, but Hazelcast supports all the types offered in the public APIs of the CompactReader/Writer.
On top of that, it supports some extra types for different languages to make it more usable for a wide range of classes. Please take a look at the reference manual for the exact list of field types supported for different languages.
Since the Zero-Config Serializers use reflection to read and write fields, it has some overhead compared to explicit Compact serializers. We recommend using explicit serializers in production for performance-critical applications.
Conclusion
That was all we wanted to talk about. It is our belief that the new Compact Serialization We hope that the new Compact Serialization will make the improve the performance and overall experience of the serialization within Hazelcast. We are looking forward to your feedback and comments about the new format. Don’t hesitate to try it and share your experience with us in our community Slack or Github repository.