
Dec 10, 2025
Why Hazelcast believes its live data platform redefines streaming data platforms
In a crowded market of streaming data platforms, differentiation is often lost in a sea of feature checklists. Against this backdrop, Hazelcast was evaluated as a Strong Performer among 15 providers in The Forrester Wave™: Streaming Data Platforms, Q4 2025. We believe Hazelcast offers a fundamental architectural divergence from the status quo. While the industry standard stitches together separate components for storage and compute, Hazelcast has engineered a unified live data platform.
This unification is not just an architectural preference—it is a business imperative for the next generation of resilient, real-time intelligence.
The “State” Problem in Traditional Streaming
Traditional architectures typically follow a “pipe-and-store” pattern: a streaming engine (like Apache Flink or Spark) processes data, while a separate database or cache (like Redis or Cassandra) holds the necessary context. This creates two distinct problems:
- The Latency Tax: Every time a stream processor checks a credit limit or inventory count, it makes a network hop to an external database. In high-throughput systems, millions of these calls create a “latency tax” that renders sub-millisecond performance impossible.
- The Complexity Tax: Managing two distributed clusters—one for compute, one for storage—doubles the operational burden, synchronization issues, and failure points. When one cluster fails or lags, the entire pipeline stalls, threatening the system’s overall reliability.
The Innovation: Co-Located Compute and State
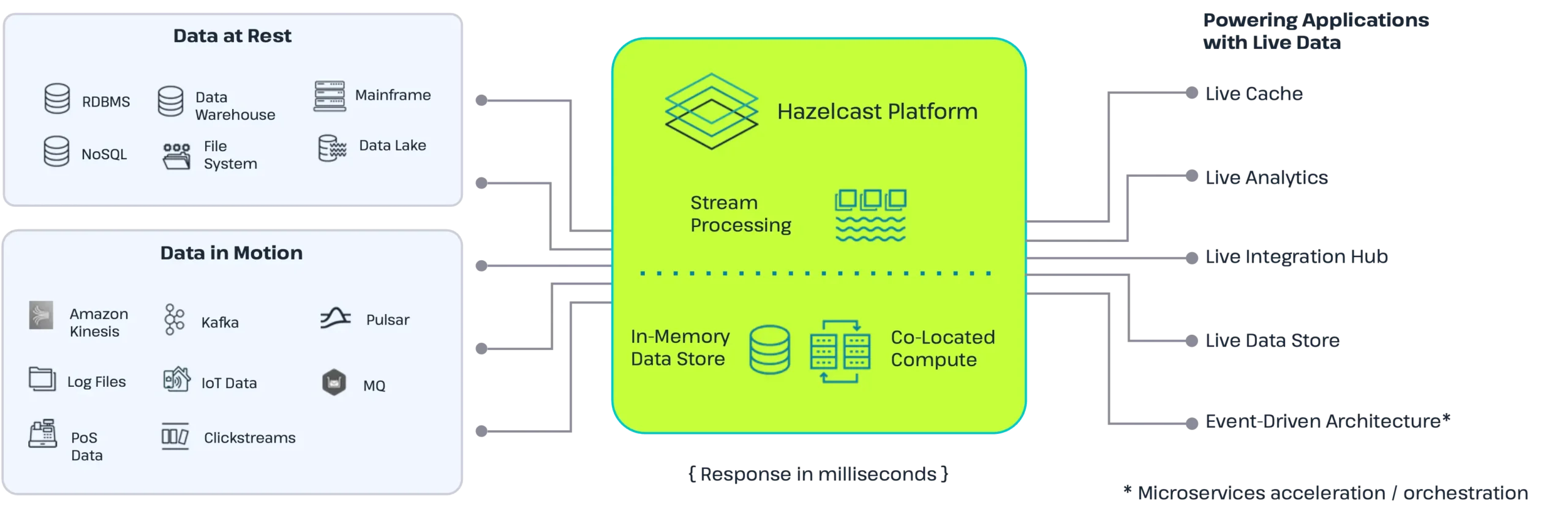
Hazelcast eliminates this divide by fusing Stream Processing (Jet) and In-Memory Data Grid (IMDG) into a single runtime. We don’t just connect to the data; the compute runs where the data lives.
Concretely, this combines an in-memory data store for hot operational data (sessions, features, counters) with a stream processing engine that ingests and analyzes data in motion. A co-located compute grid then executes business logic and AI inference directly next to the data using predicate pushdown and off-heap memory.
Because these capabilities share the same runtime, every event can be ingested, enriched, scored, and acted upon within a single platform—removing the need for extra data copies or fragile orchestration between systems. This unification also means there are fewer “moving parts” to break, inherently boosting system stability.
Low Latency by Design
This architecture delivers consistent sub-millisecond latency at massive scale—performance that “glued-together” systems simply cannot match.
- Zero-Copy Speed: Processing logic runs on the same node as the data partitions, turning lookups into local memory operations with no network hops.
- Efficiency & Correctness: Cooperative multithreading keeps CPU utilization predictable, while distributed snapshots ensure exactly-once delivery without sacrificing speed or data integrity.
The result is a platform capable of sustaining billions of events per second (Billion Events Per Second with Millisecond Latency: Streaming Analytics at Giga-Scale blog) while returning decisions in the low-millisecond range.
Operational Simplicity and Reliability
You deploy one cluster, manage one artifact, and scale one system. By unifying streaming, caching, and compute, Hazelcast drastically simplifies operations:
- Consolidated Infrastructure: Instead of managing separate clusters for Kafka, processing, and caching, teams operate a single platform with one security model and set of observability tools.
- Elastic Efficiency: The same hardware serves as both state store and compute fabric, improving utilization. The runtime scales elastically with demand to minimize over-provisioning while maintaining continuous availability during scaling events.
- Productivity: Developers build stateful applications using Java APIs and Streaming SQL, while analysts explore live data directly through the Management Center.
Resilience Without Compromise
In mission-critical environments—like payment processing or intraday risk management—speed is meaningless if the system goes down. Hazelcast’s unified architecture treats resilience as a first-class citizen, not an afterthought bolted onto external tools.
- Self-Healing Clusters: Hazelcast clusters are masterless and peer-to-peer. If a node fails, the cluster automatically detects the loss, rebalances data partitions, and recovers state from backups without manual intervention or service interruption.
- Native Disaster Recovery: High availability and Geo/WAN replication are built directly into the platform. You can replicate data across zones or regions asynchronously or synchronously to ensure business continuity even in the event of a total data center failure.
- Stateful Fault Tolerance: Unlike stateless processors that lose context during a crash, Hazelcast persists state alongside computation. Our distributed snapshotting mechanism ensures that even if a job restarts, it resumes exactly where it left off, guaranteeing exactly-once processing and zero data loss.
Powering the Real-Time AI/ML Future
This architecture is critical as the market shifts toward real-time AI/ML, where the value of a model depends entirely on the freshness of the data feeding it.
Traditional data warehouses are “post-mortem” analyzers—too slow for applications that require immediate context to take instant action. Hazelcast acts as the “pre-mortem” engine, serving as the “hot storage” brain that allows AI to read context, decide, and write back state in real-time.
Furthermore, Hazelcast eliminates the ‘inference bottleneck‘ by acting as the high-speed serving layer for features used in real-time inference. Instead of forcing your models to wait on sluggish databases for customer profiles or complex rolling aggregates, Hazelcast maintains a live, in-memory repository of these features. This ensures your inference engines can instantly retrieve the exact, continuously updated features they need to execute a prediction, preventing data latency from stalling your AI/ML pipelines.
Aligned with Where Customers Are Headed
Enterprises are looking for fewer systems and a cleaner path to production AI. Hazelcast addresses this by:
- Modernizing existing JVM and microservices estates with a cloud-native, Java-first experience.
- Providing a portable and resilient architecture that runs consistently across major clouds, Kubernetes, and on-prem environments (including mainframes via IBM).
- Creating a single data plane ensuring both applications and AI agents act on the same trusted live data.
The Bottom Line: Efficiency and Business Value Matter
This unified approach translates directly to business value. By removing the separate caching layer, customers often reduce their infrastructure footprint by approximately half1. Furthermore, with fewer moving parts and operator-grade stability, Hazelcast meets the rigorous demands of the world’s largest financial institutions.
We believe Hazelcast is not just participating in the streaming market; we are redefining it. Our platform proves you don’t have to choose between the speed of a cache and the intelligence of a stream processor, and the resilience of an enterprise data platform.
You can—and should—have all three.
Forrester does not endorse any company, product, brand, or service included in its research publications and does not advise any person to select the products or services of any company or brand based on the ratings included in such publications. Information is based on the best available resources. Opinions reflect judgment at the time and are subject to change. For more information, read about Forrester’s objectivity here .
1 Based on conversations with customers who have deployed Hazelcast in production.