Serialization is the process of converting a data object—a combination of code and data represented within a region of data storage—into a series of bytes that saves the state of the object in an easily transmittable form. In this serialized form, the data can be delivered to another data store (such as an in-memory computing platform), application, or some other destination.
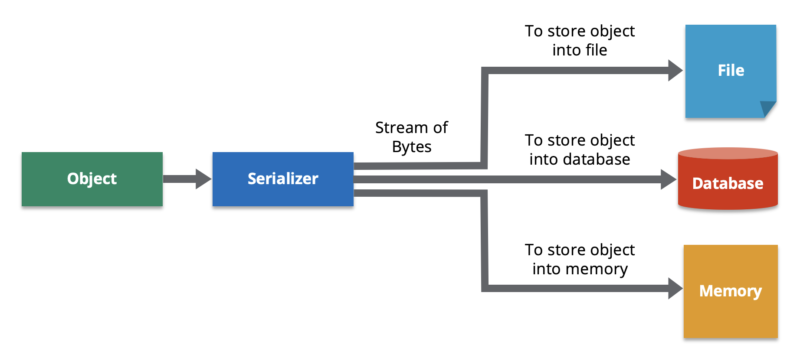
The reverse process—constructing a data structure or object from a series of bytes—is deserialization. The deserialization process recreates the object, thus making the data easier to read and modify as a native structure in a programming language.
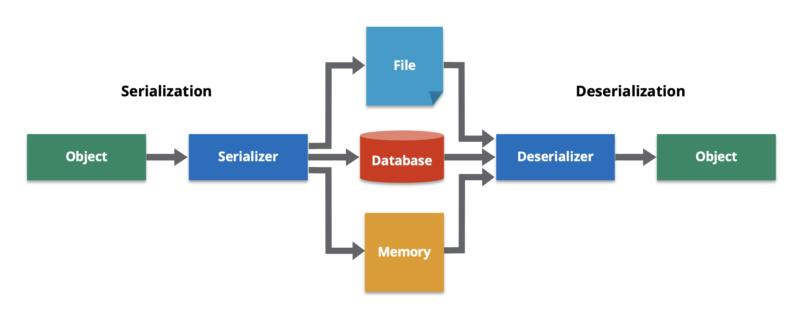
Serialization enables us to save the state of an object and recreate the object in a new location. Serialization encompasses both the storage of the object and exchange of data. Since objects are composed of several components, saving or delivering all the parts typically requires significant coding effort, so serialization is a standard way to capture the object into a sharable format.
With serialization, we can transfer objects:
- Over the wire for messaging use cases
- From application to application via web services such as REST APIs
- Through firewalls (as JSON or XML strings)
- Across domains
- To other data stores
- To identify changes in data over time
- While honoring security and user-specific details across applications