
Developer Advocate, Hazelcast
Nicolas Fränkel is a Developer Advocate with 15+ years experience consulting for many different customers, in a wide range of contexts (such as telecoms, banking, insurances, large retail and public sector). Usually working on Java/Java EE and Spring technologies, but with focused interests like Rich Internet Applications, Testing, CI/CD and DevOps. Currently working for Hazelcast. Also double as a teacher in universities and higher education schools, a trainer and triples as a book author.
View all blogs by the authorMay 12, 2021
Subscribe to the blogQuerying Your IMDG: Why and How?
Where would you draw the line between a data store and a cache? Persistence? Hazelcast allows you to write your in-memory data on disk. Derived data vs. source of truth? If the cost of creating the data is cheap, why would you persist them? Let’s agree that there’s no clear-cut defining property but a blurry continuum between those two concepts.
The raison d’être for caches is two-fold: performance, data is available faster, and availability, data is “always” available (at least the availability is higher than the underlying store). Therefore, it stands to reason queries would benefit from the same properties. You may argue that caches are key-value stores: they shine when retrieving an entry by its key. However, if you execute a query, you’d need to iterate entry by entry, something akin to a full table scan in a SQL database. The performance would be abysmal, even more so if your cache is distributed like Hazelcast.
And yet, sometimes, the underlying store offers no straightforward query mechanism either. Think about a Kafka topic or a web service.
In this post, I’d like to describe how you can take advantage of Hazelcast to query your cached data in different ways and still be fast.
Our Use Case: Collecting User Interactions
Collecting user interactions with the application is the first step when you want to improve your application. Whether it’s documentation to make it more relevant or e-commerce to increase your sales, so-called “clickstreams” can be seen as the new oil. We will use a (significantly) simplified click-collecting application architecture:
- A web page with JavaScript code that sends click events to the server
- The server part is a Python Flask application. It enriches the events and stores them in a Hazelcast cluster.
- The Hazelcast cluster itself. It provides querying capabilities.
- A third-party component to query the cache data.
In a real-world setup, we probably would want to store the event data in a persistent store, e.g., a Kafka topic or a MongoDB instance. We would then capture the inserts via a Jet pipeline to load the Hazelcast cluster. In the context of this post, it would only make the architecture unnecessarily complex.
We can tentatively model the structure of an event with the following attributes:
- The timestamp of the event
- The date on the client machine; it might differ from the previous data.
- The type, e.g., click, change, etc.
- The screen coordinates
- The source component ID
- The IP of the client machine
- The related session
- Anything else that might be relevant
When users interact with the application, the front-end will send a JSON payload that contains client-related data to the server. The server will also enrich the JSON with server-related data, e.g., IP and session ID, and store the complete JSON in a Hazelcast IMap. The key is not that important; the value is the JSON. Now, our marketing team wants to query the data to understand how users interact with our application.
The Predicate API
The Predicate API is the one that predates all other ways presented in this post. The idea behind it is that it will serve as a filter before returning the values of an IMap.
Before going further, we need to understand what it means to query a distributed system. From the documentation:
The requested predicate is sent to each member in the cluster. Each member looks at its own local entries and filters them according to the predicate. At this stage, key/value pairs of the entries are deserialized and then passed to the predicate. The predicate requester merges all the results coming from each member into a single set.
That being said, it’s time to query! Here’s the code to select all values that match a component’s name:
var entry = Predicates.newPredicateBuilder().getEntryObject();
var predicate = entry.get("component").equal(name); // 1
Collection<String> values = map.values(predicate); // 2
nameis the component’s IDvaluescontains all values that match the component’s name
The above is Java code, but all of our clients do offer the Criteria API.
Unfortunately, if you run the code as-is, values will be empty even though some values match. The reason is that by default, Hazelcast stores values as bytes arrays. Thus, it has no understanding of the underlying format. The fastest way to fix the issue is to wrap the JSON value into a HazelcastJsonValue object.
On the “put” side, we need to replace the first line with the second one:
analytics.set(uuid.uuid4(), json.dumps(data)).result() # 1 analytics.set(uuid.uuid4(), HazelcastJsonValue(data)).result()
datais a Pythondic
On the query side, the only change is to update the generic type of the collection:
Collection<String> values = map.values(predicate); Collection<HazelcastJsonValue> values = map.values(predicate);
The Shape of Water Stored Data
Using HazelcastJsonValue means we are still storing data as JSON-formatted Strings. While some language ecosystems favor the usage of JSON, e.g., JavaScript, some others favor the usage of dedicated data structures, e.g., Java and Go. If developers on different language stacks use your Hazelcast cluster, you need to store the data in the most “consumable” shape. Enters PortableAnother data serialization format that is query-friendly.
With Portable, you need to
- Design a class or a struct (for Go) that models a unit of data.
- Write down how to store and load an instance in an
IMap
Let’s keep the storage part in Python and the query part in Java. Here’s the Python code:
from hazelcast.serialization.api import Portable
class Analytics(Portable):
def __init__(self, dic=None):
if not dic:
return
self.timestamp = dic['timestamp']
self.event = dic['event']
self.instant = dic['instant']
self.component = dic['component']
self.session = dic['session']
self.client = dic['client']
self.value = dic.get('value', None)
self.type = dic.get('type', None)
self.x = dic.get('x', None)
self.y = dic.get('y', None)
def get_class_id(self):
return 1
def get_factory_id(self):
return 1
def write_portable(self, writer):
writer.write_long('timestamp', self.timestamp)
writer.write_long('instant', self.instant)
writer.write_utf('event', self.event)
writer.write_utf('component', self.component)
writer.write_utf('session', self.session)
writer.write_int('client.left', self.client['left'])
writer.write_int('client.height', self.client['height'])
writer.write_int('client.top', self.client['top'])
writer.write_int('client.width', self.client['width'])
if self.value is not None:
writer.write_utf('value', str(self.value))
if self.type is not None:
writer.write_utf('type', self.type)
if self.x is None:
writer.write_int('x', -1)
else:
writer.write_int('x', self.x)
if self.y is None:
writer.write_int('y', -1)
else:
writer.write_int('y', self.y)
factory = {
1: Analytics
}
On the Java side, we can avoid creating the class by using GenericRecord. As its name implies, it’s generic. Hence, we can query the data without having the definition of a Java Analytics class on the classpath! Again, the change is straightforward:
Collection<HazelcastJsonValue> values = map.values(predicate); Collection<GenericRecord> values = map.values(predicate);
In both cases, you can access a field by its name:
values.stream()
.map(value -> value.getString("component"))
.forEach(System.out::println);
Indexing Data
Indexing data is not (only!) related to databases and how one stores data on disk. If you already know about indexes, please feel free to skip this introduction.
Key-Value stores, such as Hazelcast’s IMap, provide fast key-based access: that’s their raison d’être. However, to query the value – or part of it, the engine needs to:
- Go through each of the entry in turn
- Check whether the predicate applies
- And eventually, add the entry to the collection of matching entries
While it’s faster to execute the flow in-memory than reading from a disk, it’s not optimal.
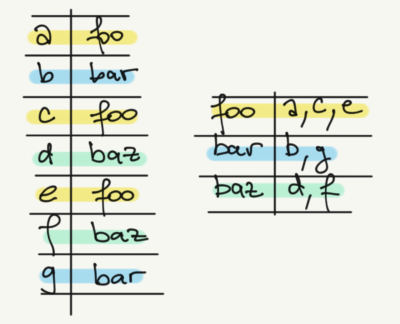
The solution is to create a dedicated data structure that stores additional information: an index. You can imagine an index as a sort of Key-Value store. The key is the value of the attribute, and the value the collection of keys from entries whose attribute’s value matches the value.
Now, when we query for entries whose value match “foo”, the engine will look at the index, locate the key “foo”, read the value, and look for entries whose keys are “a”, “c” and “e”. Of course, this is a pretty simple example. Since Hazelcast allows you to store complex values such as JSON and Portable, you can set an index on any attribute (or nested attribute).
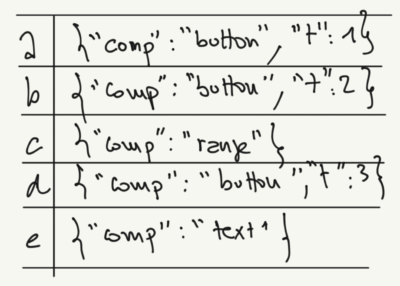
Here, you’d be able to set an index on the “comp” attribute or the “t” attribute.
You should carefully evaluate on which attribute to set an index, though, as indexes have two main downsides:
- An index slows down storing values as the engine needs to maintain the index.
- An index-only makes sense if a query is using it. With the above
IMap, if the predicate isentry.get("component").equal("button"), but the index is on “t”, it won’t improve performance.
The above explanation caters to exact matches. Imagine that we want now every entry whose “t” is above a certain threshold, e.g., entry.get("t").lessThan(2). For this usage, we need a sorted index. A sorted index keeps its keys, well, sorted. The engine will go through the keys in order, and once it has reached a key that doesn’t match the predicate, it will return the results.
Finally, for queries that involve multiple attributes, we need a compound index that contains all attributes. Here’s such a query:
var map = client.getMap("analytics");
var entry = Predicates.newPredicateBuilder().getEntryObject();
var predicate = entry.get("component").equal(name).and(entry.get("instant").lessThan(instant));
The relevant index configuration would be:
hazelcast:
map:
analytics:
indexes:
- type: HASH
attributes:
- "component"
- type: SORTED
attributes:
- "instant"
At this point, we know how to query an IMap with the Criteria API and make it fast with the proper index configuration.
SQL and JDBC
As a Java developer, you might already be familiar with SQL and JDBC. Learning a new API might feel like a roadblock. The good news is that Hazelcast now offers a JDBC driver. To use it:
- Add the driver to your classpath (here with Maven)
<dependency> <groupId>com.hazelcast</groupId> <artifactId>hazelcast-jdbc</artifactId> <version>4.2</version> </dependency> - Use the standard JDBC API:
try (var connection = DriverManager.getConnection("jdbc:hazelcast://localhost:5701/"); var statement = connection.prepareStatement("SELECT * FROM analytics where component = ? and instant < ?")) { statement.setString(1, name); statement.setLong(2, instant); var resultSet = statement.executeQuery(); var modelBuilder = new TableModelBuilder<>(); while (resultSet.next()) { var component = resultSet.getString("component"); System.out.println(component); } }
That’s all!
The icing on the cake, you can use SQL in other language stacks (without JDBC, obviously). At the time of this writing, it still uses part of the Criteria API, but we intend to move it outside. The above code can be rewritten in Python like the following:
analytics = client.get_map('analytics')
select = 'component = {component} AND instant < {instant}'.format(component = component, instant = instant)
results = analytics.values(sql(select)).result()
for result in results:
print(result.component)
Conclusion
In this post, we went through several core concepts covering querying your data on Hazelcast:
- It makes sense to query your in-memory data because data access is fast
- By default, Hazelcast offers the Criteria API; you can use SQL as an alternative
- Use indexes judiciously to speed up your queries
The complete code for this post is available on GitHub.
