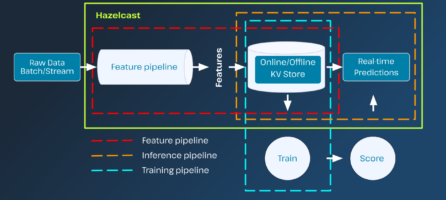
Blog Blog by Fawaz Ghali / Apr 17, 2024 Announcing Hazelcast Platform 5.4 Release Introduction The impact of solutions built on the Hazelcast Platform is visible in many aspects of our daily lives. It... Most PopularThe Cloud-Agnostic Power Play: Unleashing the Versatility of Hazelcast Platform10 Reasons Why Developers Use Hazelcast: A Recap of Flink Forward ConferenceFrom Hazelcast Customer to CTO: Why I Joined HazelcastTopic TopicAIBuild a Business CaseCachingClients and LanguagesCloudCommunityCompetitiveDeveloper TalksExecutive VoicesGetting Started and DeploymentHazelVisionIoTJCacheMicroservicesMLPerformanceProduct ReleasesReal-TimeResourcesRTSP UnconferenceSecurityStream ProcessingTutorialsUncategorized Search Clear Search by Dale Kim / Apr 10, 2024 3 Techniques to Boost Event-Driven Microservices Architectures In the ever-changing world of software development, the event-driven microservices architecture has emerged as a game-changer for its ability to... by Dale Kim / Mar 26, 2024 Moving to Microservices The tech world appreciates the term “microservices,” which is often associated with a promise of agile, forward-thinking software architectures. Migrating... by Dale Kim / Mar 21, 2024 Microservices: Accelerate Software Scalability and Resilience by Fawaz Ghali / Mar 20, 2024 Transforms: mapUsingService by Kelly Herrell / Mar 13, 2024 Accelerating Innovation: Announcing Changes to Community Edition of Hazelcast Platform by Jakki Geiger / Mar 6, 2024 BNY Mellon and Hazelcast: Gaining More Business Value by Expanding Use from Caching to Instantly Processing Real-Time Events I love sharing our customer stories and celebrating the successes of our innovative customers and users. Today, I’m spotlighting BNY... by Fawaz Ghali / Mar 4, 2024 From Batch Machine Learning to Real-Time Machine Learning by Hendy Appleton / Feb 27, 2024 New Training Course: Stream Processing with the Hazelcast Pipeline API by Raj Barua / Feb 1, 2024 Hazelcast Platform Fault Tolerant Pipelines
by Fawaz Ghali / Apr 17, 2024 Announcing Hazelcast Platform 5.4 Release Introduction The impact of solutions built on the Hazelcast Platform is visible in many aspects of our daily lives. It...
by Dale Kim / Apr 10, 2024 3 Techniques to Boost Event-Driven Microservices Architectures In the ever-changing world of software development, the event-driven microservices architecture has emerged as a game-changer for its ability to...
by Dale Kim / Mar 26, 2024 Moving to Microservices The tech world appreciates the term “microservices,” which is often associated with a promise of agile, forward-thinking software architectures. Migrating...
by Kelly Herrell / Mar 13, 2024 Accelerating Innovation: Announcing Changes to Community Edition of Hazelcast Platform
by Jakki Geiger / Mar 6, 2024 BNY Mellon and Hazelcast: Gaining More Business Value by Expanding Use from Caching to Instantly Processing Real-Time Events I love sharing our customer stories and celebrating the successes of our innovative customers and users. Today, I’m spotlighting BNY...
by Hendy Appleton / Feb 27, 2024 New Training Course: Stream Processing with the Hazelcast Pipeline API